 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Multi-regime Patterns in SciML: Distinct Failure Modes and Regime-specific Optimization
May 27, 2026Neural networks trained under different hyperparameter settings can fall into distinct training "regimes," with consistent behavior within regimes and qualitative differences across regimes. In this paper, we study such multi-regime behavior in scientific machine learning (SciML) models through a regime-aware diagnostic framework that jointly analyzes performance, training dynamics, and loss-landscape geometry. We identify three key findings: (i) a consistent three-regime structure emerges across many standard SciML models, different constraint enforcements, and various optimizer designs; (ii) optimization effectiveness is regime-specific, with no single method performing well across all regimes; and (iii) SciML models can exhibit fine-grained failure modes that can challenge conventional interpretations of standard loss-landscape metrics. Our results provide an approach to establish a unified, task-oblivious perspective on failure modes in SciML and to inform regime-aware guidance for improving robustness. We validate these findings across widely-used SciML models, including physics-informed neural networks, neural operators, and neural ordinary differential equations, on benchmarks spanning representative ordinary and partial differential equations.
Iterative Refinement Neural Operators are Learned Fixed-Point Solvers: A Principled Approach to Spectral Bias Mitigation
May 26, 2026Neural operators serve as fast, data-driven surrogates for scientific modeling but typically rely on a monolithic, single-pass inference procedure that struggles to resolve high-frequency details, a limitation known as spectral bias. We introduce the Iterative Refinement Neural Operator (IRNO), which augments pre-trained operators with a learned refinement module iteratively applied via fixed-point iteration. IRNO decomposes the prediction into a coarse initialization followed by successive residual corrections, paralleling classical numerical solvers. Under local assumptions, we establish contraction of the induced operator, ensuring convergence to a unique fixed point. To explicitly target high-frequency errors, we propose a progressive spectral loss that adaptively increases penalty on high-frequency components over refinement steps during training. Across physical systems, IRNO consistently lowers error, with up to 56.05% improvement on turbulent flow. On Active Matter, spectral analysis reveals that, relative to base operator, the normalized error ratios decrease to 27.72-36.10% in low-, 5.07-6.68% in mid-, and 1.48-2.04% in high-frequencies, remaining stable beyond the trained iteration count. Code is available at https://github.com/xiaotianliu-dartmouth/Iterative_Refinement_Neural_Operator
Learning, Solving and Optimizing PDEs with TensorGalerkin: an efficient high-performance Galerkin assembly algorithm
Feb 04, 2026We present a unified algorithmic framework for the numerical solution, constrained optimization, and physics-informed learning of PDEs with a variational structure. Our framework is based on a Galerkin discretization of the underlying variational forms, and its high efficiency stems from a novel highly-optimized and GPU-compliant TensorGalerkin framework for linear system assembly (stiffness matrices and load vectors). TensorGalerkin operates by tensorizing element-wise operations within a Python-level Map stage and then performs global reduction with a sparse matrix multiplication that performs message passing on the mesh-induced sparsity graph. It can be seamlessly employed downstream as i) a highly-efficient numerical PDEs solver, ii) an end-to-end differentiable framework for PDE-constrained optimization, and iii) a physics-informed operator learning algorithm for PDEs. With multiple benchmarks, including 2D and 3D elliptic, parabolic, and hyperbolic PDEs on unstructured meshes, we demonstrate that the proposed framework provides significant computational efficiency and accuracy gains over a variety of baselines in all the targeted downstream applications.
Modeling Non-Ergodic Path Effects Using Conditional Generative Model for Fourier Amplitude Spectra
Dec 22, 2025Recent developments in non-ergodic ground-motion models (GMMs) explicitly model systematic spatial variations in source, site, and path effects, reducing standard deviation to 30-40% of ergodic models and enabling more accurate site-specific seismic hazard analysis. Current non-ergodic GMMs rely on Gaussian Process (GP) methods with prescribed correlation functions and thus have computational limitations for large-scale predictions. This study proposes a deep-learning approach called Conditional Generative Modeling for Fourier Amplitude Spectra (CGM-FAS) as an alternative to GP-based methods for modeling non-ergodic path effects in Fourier Amplitude Spectra (FAS). CGM-FAS uses a Conditional Variational Autoencoder architecture to learn spatial patterns and interfrequency correlation directly from data by using geographical coordinates of earthquakes and stations as conditional variables. Using San Francisco Bay Area earthquake data, we compare CGM-FAS against a recent GP-based GMM for the region and demonstrate consistent predictions of non-ergodic path effects. Additionally, CGM-FAS offers advantages compared to GP-based approaches in learning spatial patterns without prescribed correlation functions, capturing interfrequency correlations, and enabling rapid predictions, generating maps for 10,000 sites across 1,000 frequencies within 10 seconds using a few GB of memory. CGM-FAS hyperparameters can be tuned to ensure generated path effects exhibit variability consistent with the GP-based empirical GMM. This work demonstrates a promising direction for efficient non-ergodic ground-motion prediction across multiple frequencies and large spatial domains.
Conservation-informed Graph Learning for Spatiotemporal Dynamics Prediction
Dec 30, 2024



Data-centric methods have shown great potential in understanding and predicting spatiotemporal dynamics, enabling better design and control of the object system. However, pure deep learning models often lack interpretability, fail to obey intrinsic physics, and struggle to cope with the various domains. While geometry-based methods, e.g., graph neural networks (GNNs), have been proposed to further tackle these challenges, they still need to find the implicit physical laws from large datasets and rely excessively on rich labeled data. In this paper, we herein introduce the conservation-informed GNN (CiGNN), an end-to-end explainable learning framework, to learn spatiotemporal dynamics based on limited training data. The network is designed to conform to the general conservation law via symmetry, where conservative and non-conservative information passes over a multiscale space enhanced by a latent temporal marching strategy. The efficacy of our model has been verified in various spatiotemporal systems based on synthetic and real-world datasets, showing superiority over baseline models. Results demonstrate that CiGNN exhibits remarkable accuracy and generalization ability, and is readily applicable to learning for prediction of various spatiotemporal dynamics in a spatial domain with complex geometry.
P$^2$C$^2$Net: PDE-Preserved Coarse Correction Network for efficient prediction of spatiotemporal dynamics
Oct 29, 2024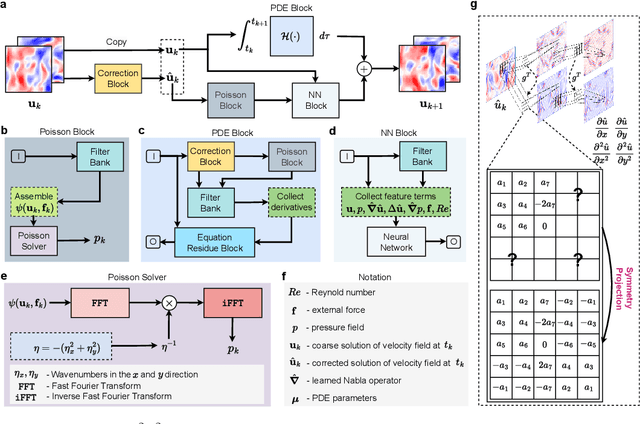
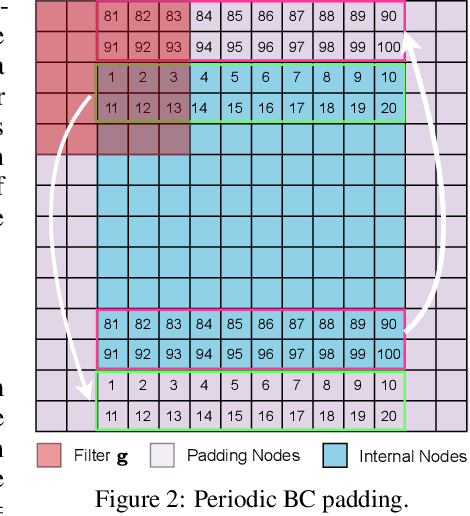
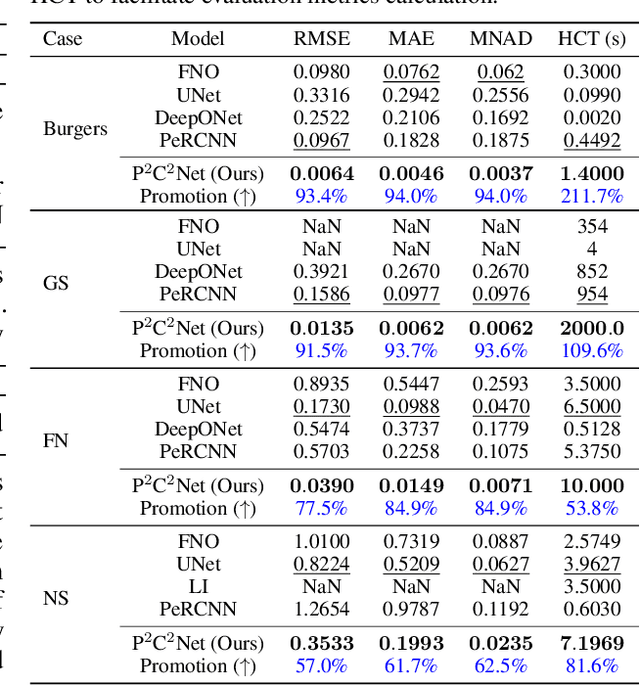
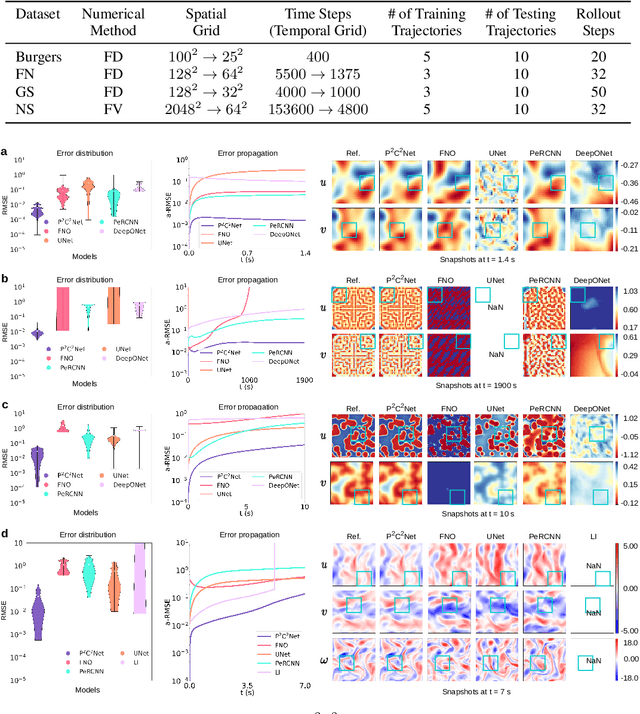
When solving partial differential equations (PDEs), classical numerical methods often require fine mesh grids and small time stepping to meet stability, consistency, and convergence conditions, leading to high computational cost. Recently, machine learning has been increasingly utilized to solve PDE problems, but they often encounter challenges related to interpretability, generalizability, and strong dependency on rich labeled data. Hence, we introduce a new PDE-Preserved Coarse Correction Network (P$^2$C$^2$Net) to efficiently solve spatiotemporal PDE problems on coarse mesh grids in small data regimes. The model consists of two synergistic modules: (1) a trainable PDE block that learns to update the coarse solution (i.e., the system state), based on a high-order numerical scheme with boundary condition encoding, and (2) a neural network block that consistently corrects the solution on the fly. In particular, we propose a learnable symmetric Conv filter, with weights shared over the entire model, to accurately estimate the spatial derivatives of PDE based on the neural-corrected system state. The resulting physics-encoded model is capable of handling limited training data (e.g., 3--5 trajectories) and accelerates the prediction of PDE solutions on coarse spatiotemporal grids while maintaining a high accuracy. P$^2$C$^2$Net achieves consistent state-of-the-art performance with over 50\% gain (e.g., in terms of relative prediction error) across four datasets covering complex reaction-diffusion processes and turbulent flows.
Model Balancing Helps Low-data Training and Fine-tuning
Oct 16, 2024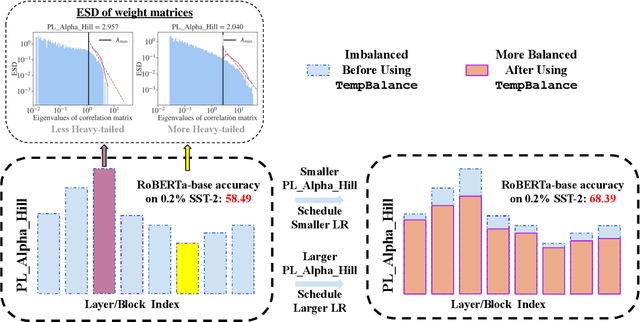

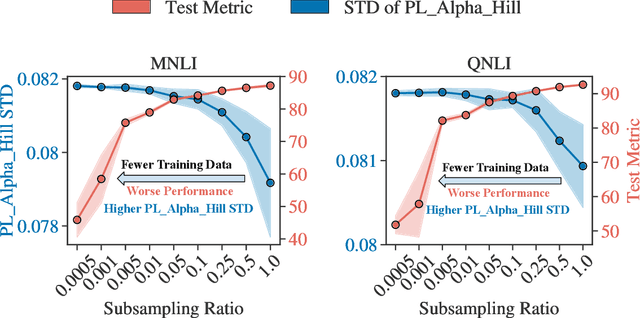
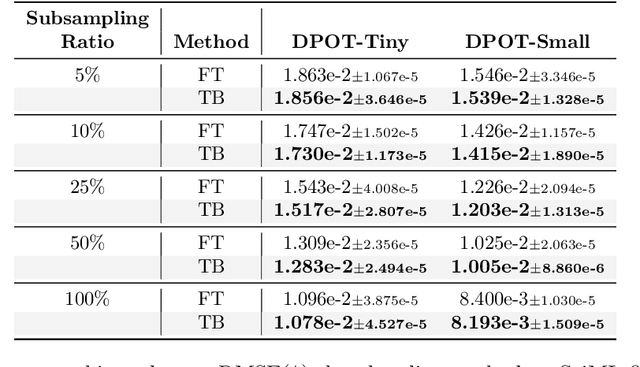
Recent advances in foundation models have emphasized the need to align pre-trained models with specialized domains using small, curated datasets. Studies on these foundation models underscore the importance of low-data training and fine-tuning. This topic, well-known in natural language processing (NLP), has also gained increasing attention in the emerging field of scientific machine learning (SciML). To address the limitations of low-data training and fine-tuning, we draw inspiration from Heavy-Tailed Self-Regularization (HT-SR) theory, analyzing the shape of empirical spectral densities (ESDs) and revealing an imbalance in training quality across different model layers. To mitigate this issue, we adapt a recently proposed layer-wise learning rate scheduler, TempBalance, which effectively balances training quality across layers and enhances low-data training and fine-tuning for both NLP and SciML tasks. Notably, TempBalance demonstrates increasing performance gains as the amount of available tuning data decreases. Comparative analyses further highlight the effectiveness of TempBalance and its adaptability as an "add-on" method for improving model performance.
Learning Physics for Unveiling Hidden Earthquake Ground Motions via Conditional Generative Modeling
Jul 21, 2024



Predicting high-fidelity ground motions for future earthquakes is crucial for seismic hazard assessment and infrastructure resilience. Conventional empirical simulations suffer from sparse sensor distribution and geographically localized earthquake locations, while physics-based methods are computationally intensive and require accurate representations of Earth structures and earthquake sources. We propose a novel artificial intelligence (AI) simulator, Conditional Generative Modeling for Ground Motion (CGM-GM), to synthesize high-frequency and spatially continuous earthquake ground motion waveforms. CGM-GM leverages earthquake magnitudes and geographic coordinates of earthquakes and sensors as inputs, learning complex wave physics and Earth heterogeneities, without explicit physics constraints. This is achieved through a probabilistic autoencoder that captures latent distributions in the time-frequency domain and variational sequential models for prior and posterior distributions. We evaluate the performance of CGM-GM using small-magnitude earthquake records from the San Francisco Bay Area, a region with high seismic risks. CGM-GM demonstrates a strong potential for outperforming a state-of-the-art non-ergodic empirical ground motion model and shows great promise in seismology and beyond.
WaveCastNet: An AI-enabled Wavefield Forecasting Framework for Earthquake Early Warning
May 30, 2024



Large earthquakes can be destructive and quickly wreak havoc on a landscape. To mitigate immediate threats, early warning systems have been developed to alert residents, emergency responders, and critical infrastructure operators seconds to a minute before seismic waves arrive. These warnings provide time to take precautions and prevent damage. The success of these systems relies on fast, accurate predictions of ground motion intensities, which is challenging due to the complex physics of earthquakes, wave propagation, and their intricate spatial and temporal interactions. To improve early warning, we propose a novel AI-enabled framework, WaveCastNet, for forecasting ground motions from large earthquakes. WaveCastNet integrates a novel convolutional Long Expressive Memory (ConvLEM) model into a sequence to sequence (seq2seq) forecasting framework to model long-term dependencies and multi-scale patterns in both space and time. WaveCastNet, which shares weights across spatial and temporal dimensions, requires fewer parameters compared to more resource-intensive models like transformers and thus, in turn, reduces inference times. Importantly, WaveCastNet also generalizes better than transformer-based models to different seismic scenarios, including to more rare and critical situations with higher magnitude earthquakes. Our results using simulated data from the San Francisco Bay Area demonstrate the capability to rapidly predict the intensity and timing of destructive ground motions. Importantly, our proposed approach does not require estimating earthquake magnitudes and epicenters, which are prone to errors using conventional approaches; nor does it require empirical ground motion models, which fail to capture strongly heterogeneous wave propagation effects.
Reasoning-Enhanced Object-Centric Learning for Videos
Mar 22, 2024


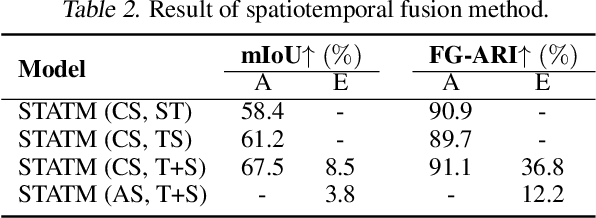
Object-centric learning aims to break down complex visual scenes into more manageable object representations, enhancing the understanding and reasoning abilities of machine learning systems toward the physical world. Recently, slot-based video models have demonstrated remarkable proficiency in segmenting and tracking objects, but they overlook the importance of the effective reasoning module. In the real world, reasoning and predictive abilities play a crucial role in human perception and object tracking; in particular, these abilities are closely related to human intuitive physics. Inspired by this, we designed a novel reasoning module called the Slot-based Time-Space Transformer with Memory buffer (STATM) to enhance the model's perception ability in complex scenes. The memory buffer primarily serves as storage for slot information from upstream modules, the Slot-based Time-Space Transformer makes predictions through slot-based spatiotemporal attention computations and fusion. Our experiment results on various datasets show that STATM can significantly enhance object-centric learning capabilities of slot-based video models.