 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Enhanced Object-Centric Learning for Videos
Paper and Code



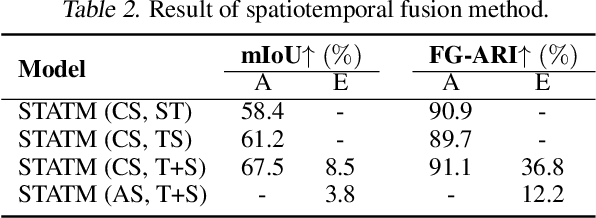
Object-centric learning aims to break down complex visual scenes into more manageable object representations, enhancing the understanding and reasoning abilities of machine learning systems toward the physical world. Recently, slot-based video models have demonstrated remarkable proficiency in segmenting and tracking objects, but they overlook the importance of the effective reasoning module. In the real world, reasoning and predictive abilities play a crucial role in human perception and object tracking; in particular, these abilities are closely related to human intuitive physics. Inspired by this, we designed a novel reasoning module called the Slot-based Time-Space Transformer with Memory buffer (STATM) to enhance the model's perception ability in complex scenes. The memory buffer primarily serves as storage for slot information from upstream modules, the Slot-based Time-Space Transformer makes predictions through slot-based spatiotemporal attention computations and fusion. Our experiment results on various datasets show that STATM can significantly enhance object-centric learning capabilities of slot-based video models.