 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP$^2$C$^2$Net: PDE-Preserved Coarse Correction Network for efficient prediction of spatiotemporal dynamics
Oct 29, 2024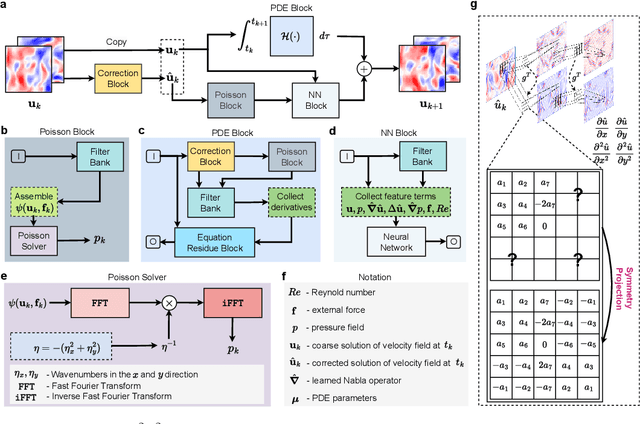
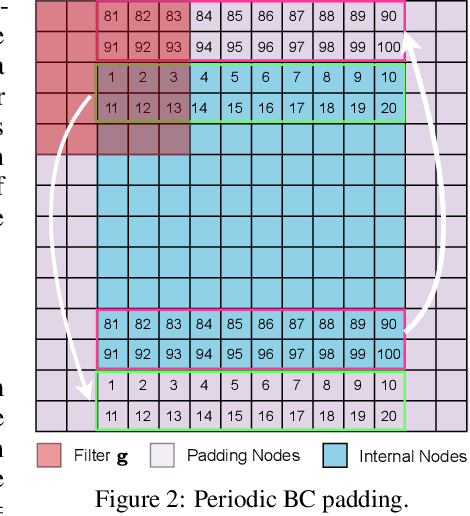
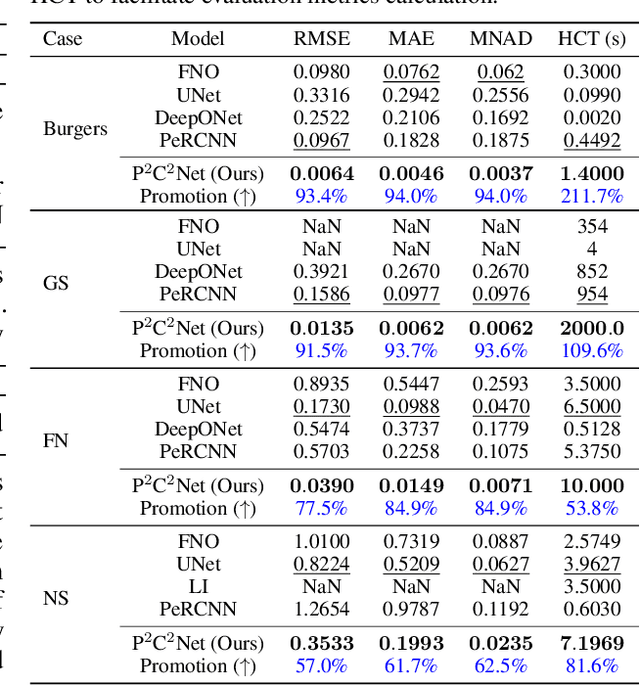
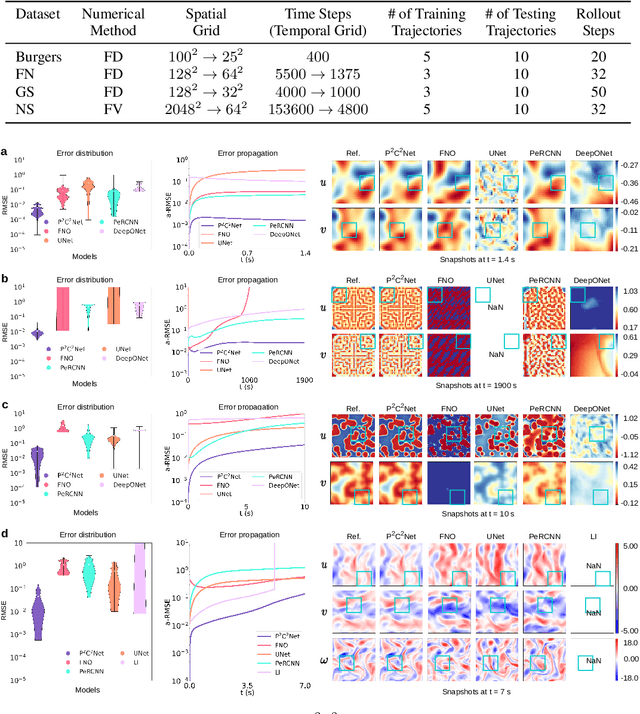
When solving partial differential equations (PDEs), classical numerical methods often require fine mesh grids and small time stepping to meet stability, consistency, and convergence conditions, leading to high computational cost. Recently, machine learning has been increasingly utilized to solve PDE problems, but they often encounter challenges related to interpretability, generalizability, and strong dependency on rich labeled data. Hence, we introduce a new PDE-Preserved Coarse Correction Network (P$^2$C$^2$Net) to efficiently solve spatiotemporal PDE problems on coarse mesh grids in small data regimes. The model consists of two synergistic modules: (1) a trainable PDE block that learns to update the coarse solution (i.e., the system state), based on a high-order numerical scheme with boundary condition encoding, and (2) a neural network block that consistently corrects the solution on the fly. In particular, we propose a learnable symmetric Conv filter, with weights shared over the entire model, to accurately estimate the spatial derivatives of PDE based on the neural-corrected system state. The resulting physics-encoded model is capable of handling limited training data (e.g., 3--5 trajectories) and accelerates the prediction of PDE solutions on coarse spatiotemporal grids while maintaining a high accuracy. P$^2$C$^2$Net achieves consistent state-of-the-art performance with over 50\% gain (e.g., in terms of relative prediction error) across four datasets covering complex reaction-diffusion processes and turbulent flows.
RepoMasterEval: Evaluating Code Completion via Real-World Repositories
Aug 07, 2024



With the growing reliance on automated code completion tools in software development, the need for robust evaluation benchmarks has become critical. However, existing benchmarks focus more on code generation tasks in function and class level and provide rich text description to prompt the model. By contrast, such descriptive prompt is commonly unavailable in real development and code completion can occur in wider range of situations such as in the middle of a function or a code block. These limitations makes the evaluation poorly align with the practical scenarios of code completion tools. In this paper, we propose RepoMasterEval, a novel benchmark for evaluating code completion models constructed from real-world Python and TypeScript repositories. Each benchmark datum is generated by masking a code snippet (ground truth) from one source code file with existing test suites. To improve test accuracy of model generated code, we employ mutation testing to measure the effectiveness of the test cases and we manually crafted new test cases for those test suites with low mutation score. Our empirical evaluation on 6 state-of-the-art models shows that test argumentation is critical in improving the accuracy of the benchmark and RepoMasterEval is able to report difference in model performance in real-world scenarios. The deployment of RepoMasterEval in a collaborated company for one month also revealed that the benchmark is useful to give accurate feedback during model training and the score is in high correlation with the model's performance in practice. Based on our findings, we call for the software engineering community to build more LLM benchmarks tailored for code generation tools taking the practical and complex development environment into consideration.