 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Repository-level Software Documentation via Question Answering and Feature-Driven Development
Apr 08, 2026Software documentation is crucial for repository comprehension. While Large Language Models (LLMs) advance documentation generation from code snippets to entire repositories, existing benchmarks have two key limitations: (1) they lack a holistic, repository-level assessment, and (2) they rely on unreliable evaluation strategies, such as LLM-as-a-judge, which suffers from vague criteria and limited repository-level knowledge. To address these issues, we introduce SWD-Bench, a novel benchmark for evaluating repository-level software documentation. Inspired by documentation-driven development, our strategy evaluates documentation quality by assessing an LLM's ability to understand and implement functionalities using the documentation, rather than by directly scoring it. This is measured through function-driven Question Answering (QA) tasks. SWD-Bench comprises three interconnected QA tasks: (1) Functionality Detection, to determine if a functionality is described; (2) Functionality Localization, to evaluate the accuracy of locating related files; and (3) Functionality Completion, to measure the comprehensiveness of implementation details. We construct the benchmark, containing 4,170 entries, by mining high-quality Pull Requests and enriching them with repository-level context. Experiments reveal limitations in current documentation generation methods and show that source code provides complementary value. Notably, documentation from the best-performing method improves the issue-solving rate of SWE-Agent by 20.00%, which demonstrates the practical value of high-quality documentation in supporting documentation-driven development.
Evaluating LLM-Based 0-to-1 Software Generation in End-to-End CLI Tool Scenarios
Apr 08, 2026Large Language Models (LLMs) are driving a shift towards intent-driven development, where agents build complete software from scratch. However, existing benchmarks fail to assess this 0-to-1 generation capability due to two limitations: reliance on predefined scaffolds that ignore repository structure planning, and rigid white-box unit testing that lacks end-to-end behavioral validation. To bridge this gap, we introduce CLI-Tool-Bench, a structure-agnostic benchmark for evaluating the ground-up generation of Command-Line Interface (CLI) tools. It features 100 diverse real-world repositories evaluated via a black-box differential testing framework. Agent-generated software is executed in sandboxes, comparing system side effects and terminal outputs against human-written oracles using multi-tiered equivalence metrics. Evaluating seven state-of-the-art LLMs, we reveal that top models achieve under 43% success, highlighting the ongoing challenge of 0-to-1 generation. Furthermore, higher token consumption does not guarantee better performance, and agents tend to generate monolithic code.
Benchmarking LLMs for Fine-Grained Code Review with Enriched Context in Practice
Nov 10, 2025



Code review is a cornerstone of software quality assurance, and recent advances in Large Language Models (LLMs) have shown promise in automating this process. However, existing benchmarks for LLM-based code review face three major limitations. (1) Lack of semantic context: most benchmarks provide only code diffs without textual information such as issue descriptions, which are crucial for understanding developer intent. (2) Data quality issues: without rigorous validation, many samples are noisy-e.g., reviews on outdated or irrelevant code-reducing evaluation reliability. (3) Coarse granularity: most benchmarks operate at the file or commit level, overlooking the fine-grained, line-level reasoning essential for precise review. We introduce ContextCRBench, a high-quality, context-rich benchmark for fine-grained LLM evaluation in code review. Our construction pipeline comprises: (1) Raw Data Crawling, collecting 153.7K issues and pull requests from top-tier repositories; (2) Comprehensive Context Extraction, linking issue-PR pairs for textual context and extracting the full surrounding function or class for code context; and (3) Multi-stage Data Filtering, combining rule-based and LLM-based validation to remove outdated, malformed, or low-value samples, resulting in 67,910 context-enriched entries. ContextCRBench supports three evaluation scenarios aligned with the review workflow: (1) hunk-level quality assessment, (2) line-level defect localization, and (3) line-level comment generation. Evaluating eight leading LLMs (four closed-source and four open-source) reveals that textual context yields greater performance gains than code context alone, while current LLMs remain far from human-level review ability. Deployed at ByteDance, ContextCRBench drives a self-evolving code review system, improving performance by 61.98% and demonstrating its robustness and industrial utility.
CodeVisionary: An Agent-based Framework for Evaluating Large Language Models in Code Generation
Apr 18, 2025Large language models (LLMs) have demonstrated strong capabilities in code generation, underscoring the critical need for rigorous and comprehensive evaluation. Existing evaluation approaches fall into three categories, including human-centered, metric-based, and LLM-based. Considering that human-centered approaches are labour-intensive and metric-based ones overly rely on reference answers, LLM-based approaches are gaining increasing attention due to their stronger contextual understanding capabilities and superior efficiency. However, the performance of LLM-based approaches remains limited due to: (1) lack of multisource domain knowledge, and (2) insufficient comprehension of complex code. To mitigate the limitations, we propose CodeVisionary, the first LLM-based agent framework for evaluating LLMs in code generation. CodeVisionary consists of two stages: (1) Multiscore knowledge analysis stage, which aims to gather multisource and comprehensive domain knowledge by formulating and executing a stepwise evaluation plan. (2) Negotiation-based scoring stage, which involves multiple judges engaging in discussions to better comprehend the complex code and reach a consensus on the evaluation score. Extensive experiments demonstrate that CodeVisionary achieves the best performance for evaluating LLMs in code generation, outperforming the best baseline methods with average improvements of 0.202, 0.139, and 0.117 in Pearson, Spearman, and Kendall-Tau coefficients, respectively. Besides, CodeVisionary provides detailed evaluation reports, which assist developers in identifying shortcomings and making improvements. The resources of CodeVisionary are available at https://anonymous.4open.science/r/CodeVisionary.
An LLM-based Agent for Reliable Docker Environment Configuration
Feb 19, 2025Environment configuration is a critical yet time-consuming step in software development, especially when dealing with unfamiliar code repositories. While Large Language Models (LLMs) demonstrate the potential to accomplish software engineering tasks, existing methods for environment configuration often rely on manual efforts or fragile scripts, leading to inefficiencies and unreliable outcomes. We introduce Repo2Run, the first LLM-based agent designed to fully automate environment configuration and generate executable Dockerfiles for arbitrary Python repositories. We address two major challenges: (1) enabling the LLM agent to configure environments within isolated Docker containers, and (2) ensuring the successful configuration process is recorded and accurately transferred to a Dockerfile without error. To achieve this, we propose atomic configuration synthesis, featuring a dual-environment architecture (internal and external environment) with a rollback mechanism to prevent environment "pollution" from failed commands, guaranteeing atomic execution (execute fully or not at all) and a Dockerfile generator to transfer successful configuration steps into runnable Dockerfiles. We evaluate Repo2Run~on our proposed benchmark of 420 recent Python repositories with unit tests, where it achieves an 86.0% success rate, outperforming the best baseline by 63.9%.
CodeRepoQA: A Large-scale Benchmark for Software Engineering Question Answering
Dec 19, 2024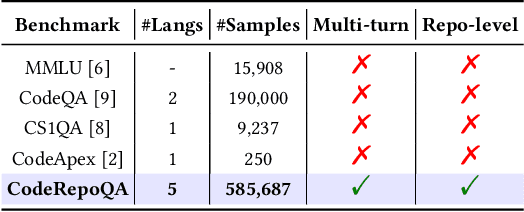
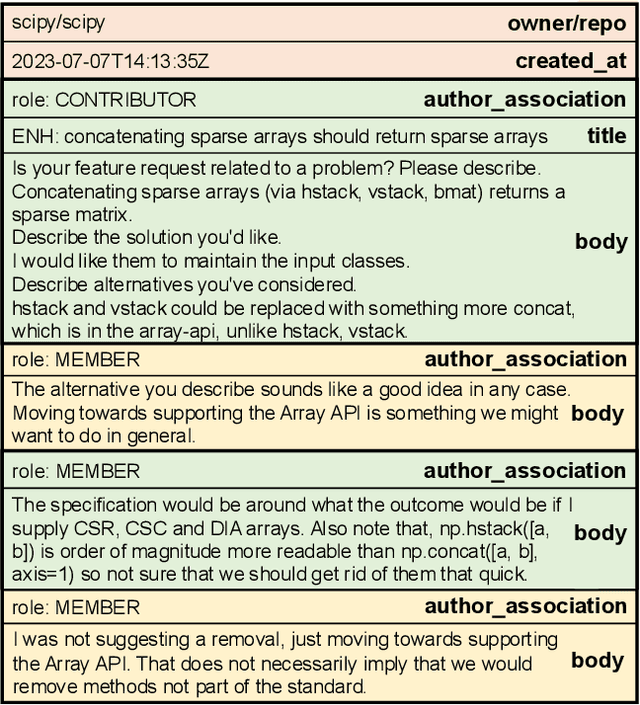

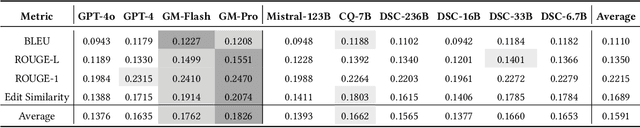
In this work, we introduce CodeRepoQA, a large-scale benchmark specifically designed for evaluating repository-level question-answering capabilities in the field of software engineering. CodeRepoQA encompasses five programming languages and covers a wide range of scenarios, enabling comprehensive evaluation of language models. To construct this dataset, we crawl data from 30 well-known repositories in GitHub, the largest platform for hosting and collaborating on code, and carefully filter raw data. In total, CodeRepoQA is a multi-turn question-answering benchmark with 585,687 entries, covering a diverse array of software engineering scenarios, with an average of 6.62 dialogue turns per entry. We evaluate ten popular large language models on our dataset and provide in-depth analysis. We find that LLMs still have limitations in question-answering capabilities in the field of software engineering, and medium-length contexts are more conducive to LLMs' performance. The entire benchmark is publicly available at https://github.com/kinesiatricssxilm14/CodeRepoQA.
AEGIS: An Agent-based Framework for General Bug Reproduction from Issue Descriptions
Nov 27, 2024In software maintenance, bug reproduction is essential for effective fault localization and repair. Manually writing reproduction scripts is a time-consuming task with high requirements for developers. Hence, automation of bug reproduction has increasingly attracted attention from researchers and practitioners. However, the existing studies on bug reproduction are generally limited to specific bug types such as program crashes, and hard to be applied to general bug reproduction. In this paper, considering the superior performance of agent-based methods in code intelligence tasks, we focus on designing an agent-based framework for the task. Directly employing agents would lead to limited bug reproduction performance, due to entangled subtasks, lengthy retrieved context, and unregulated actions. To mitigate the challenges, we propose an Automated gEneral buG reproductIon Scripts generation framework, named AEGIS, which is the first agent-based framework for the task. AEGIS mainly contains two modules: (1) A concise context construction module, which aims to guide the code agent in extracting structured information from issue descriptions, identifying issue-related code with detailed explanations, and integrating these elements to construct the concise context; (2) A FSM-based multi-feedback optimization module to further regulate the behavior of the code agent within the finite state machine (FSM), ensuring a controlled and efficient script generation process based on multi-dimensional feedback. Extensive experiments on the public benchmark dataset show that AEGIS outperforms the state-of-the-art baseline by 23.0% in F->P metric. In addition, the bug reproduction scripts generated by AEGIS can improve the relative resolved rate of Agentless by 12.5%.
RepoMasterEval: Evaluating Code Completion via Real-World Repositories
Aug 07, 2024



With the growing reliance on automated code completion tools in software development, the need for robust evaluation benchmarks has become critical. However, existing benchmarks focus more on code generation tasks in function and class level and provide rich text description to prompt the model. By contrast, such descriptive prompt is commonly unavailable in real development and code completion can occur in wider range of situations such as in the middle of a function or a code block. These limitations makes the evaluation poorly align with the practical scenarios of code completion tools. In this paper, we propose RepoMasterEval, a novel benchmark for evaluating code completion models constructed from real-world Python and TypeScript repositories. Each benchmark datum is generated by masking a code snippet (ground truth) from one source code file with existing test suites. To improve test accuracy of model generated code, we employ mutation testing to measure the effectiveness of the test cases and we manually crafted new test cases for those test suites with low mutation score. Our empirical evaluation on 6 state-of-the-art models shows that test argumentation is critical in improving the accuracy of the benchmark and RepoMasterEval is able to report difference in model performance in real-world scenarios. The deployment of RepoMasterEval in a collaborated company for one month also revealed that the benchmark is useful to give accurate feedback during model training and the score is in high correlation with the model's performance in practice. Based on our findings, we call for the software engineering community to build more LLM benchmarks tailored for code generation tools taking the practical and complex development environment into consideration.