 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning
Feb 27, 2025



Mainstream issue-resolving frameworks predominantly rely on commercial models, leading to high costs and privacy concerns. Existing training approaches for issue resolving struggle with poor generalization and fail to fully leverage open-source development resources. We propose Subtask-oriented Reinforced Fine-Tuning (SoRFT), a novel training approach to enhance the issue resolving capability of LLMs. We decomposes issue resolving into structured subtasks: file localization, function localization, line localization, and code edit generation. SoRFT consists of two training stages: (1) rejection-sampled supervised fine-tuning, Chain of Thought (CoT) data is filtered using ground-truth before fine-tuning the LLM, and (2) rule-based reinforcement learning, which leverages PPO with ground-truth based rewards. We evaluate the SoRFT-trained model on SWE-Bench Verified and SWE-Bench Lite, achieving state-of-the-art (SOTA) performance among open-source models (e.g., resolve 21.4% issues on SWE-Bench Verified with SoRFT-Qwen-7B). The experimental results demonstrate that SoRFT significantly enhances issue-resolving performance, improves model generalization, and provides a cost-efficient alternative to commercial models.
CodeRepoQA: A Large-scale Benchmark for Software Engineering Question Answering
Dec 19, 2024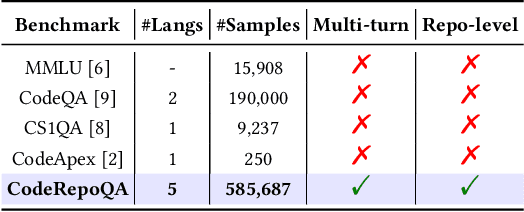
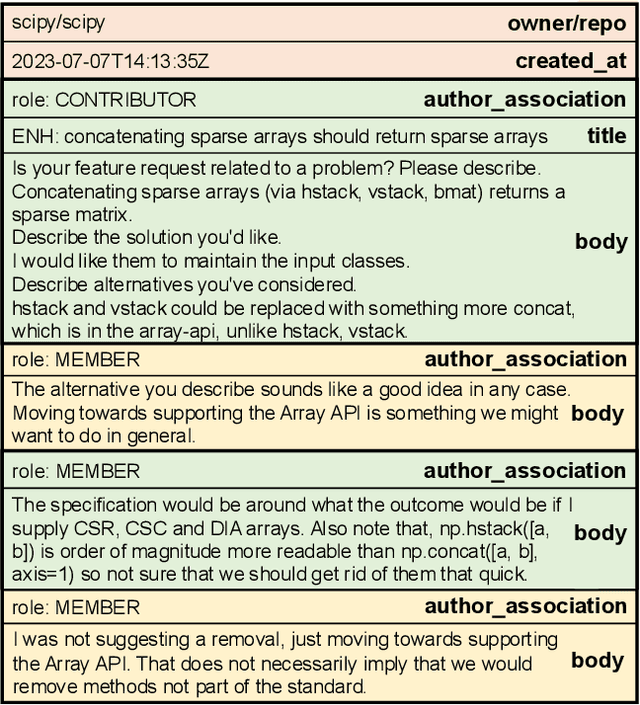

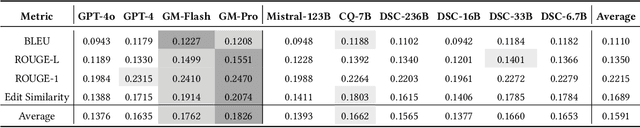
In this work, we introduce CodeRepoQA, a large-scale benchmark specifically designed for evaluating repository-level question-answering capabilities in the field of software engineering. CodeRepoQA encompasses five programming languages and covers a wide range of scenarios, enabling comprehensive evaluation of language models. To construct this dataset, we crawl data from 30 well-known repositories in GitHub, the largest platform for hosting and collaborating on code, and carefully filter raw data. In total, CodeRepoQA is a multi-turn question-answering benchmark with 585,687 entries, covering a diverse array of software engineering scenarios, with an average of 6.62 dialogue turns per entry. We evaluate ten popular large language models on our dataset and provide in-depth analysis. We find that LLMs still have limitations in question-answering capabilities in the field of software engineering, and medium-length contexts are more conducive to LLMs' performance. The entire benchmark is publicly available at https://github.com/kinesiatricssxilm14/CodeRepoQA.
AEGIS: An Agent-based Framework for General Bug Reproduction from Issue Descriptions
Nov 27, 2024In software maintenance, bug reproduction is essential for effective fault localization and repair. Manually writing reproduction scripts is a time-consuming task with high requirements for developers. Hence, automation of bug reproduction has increasingly attracted attention from researchers and practitioners. However, the existing studies on bug reproduction are generally limited to specific bug types such as program crashes, and hard to be applied to general bug reproduction. In this paper, considering the superior performance of agent-based methods in code intelligence tasks, we focus on designing an agent-based framework for the task. Directly employing agents would lead to limited bug reproduction performance, due to entangled subtasks, lengthy retrieved context, and unregulated actions. To mitigate the challenges, we propose an Automated gEneral buG reproductIon Scripts generation framework, named AEGIS, which is the first agent-based framework for the task. AEGIS mainly contains two modules: (1) A concise context construction module, which aims to guide the code agent in extracting structured information from issue descriptions, identifying issue-related code with detailed explanations, and integrating these elements to construct the concise context; (2) A FSM-based multi-feedback optimization module to further regulate the behavior of the code agent within the finite state machine (FSM), ensuring a controlled and efficient script generation process based on multi-dimensional feedback. Extensive experiments on the public benchmark dataset show that AEGIS outperforms the state-of-the-art baseline by 23.0% in F->P metric. In addition, the bug reproduction scripts generated by AEGIS can improve the relative resolved rate of Agentless by 12.5%.
An Empirical Study on LLM-based Agents for Automated Bug Fixing
Nov 15, 2024



Large language models (LLMs) and LLM-based Agents have been applied to fix bugs automatically, demonstrating the capability in addressing software defects by engaging in development environment interaction, iterative validation and code modification. However, systematic analysis of these agent and non-agent systems remain limited, particularly regarding performance variations among top-performing ones. In this paper, we examine seven proprietary and open-source systems on the SWE-bench Lite benchmark for automated bug fixing. We first assess each system's overall performance, noting instances solvable by all or none of these sytems, and explore why some instances are uniquely solved by specific system types. We also compare fault localization accuracy at file and line levels and evaluate bug reproduction capabilities, identifying instances solvable only through dynamic reproduction. Through analysis, we concluded that further optimization is needed in both the LLM itself and the design of Agentic flow to improve the effectiveness of the Agent in bug fixing.