 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction
May 07, 2026Large language models (LLMs) are increasingly used as interactive agents, but optimizing them for long-horizon decision making remains difficult because current methods are largely purely reactive, which weakens both exploration and credit assignment over extended trajectories. In this work, we present Strategic Trajectory Abstraction (StraTA), a simple framework that introduces an explicit trajectory-level strategy into agentic reinforcement learning (RL). StraTA samples a compact strategy from the initial task state, conditions subsequent actions on that strategy, and trains strategy generation and action execution jointly with a hierarchical GRPO-style rollout design, further enhanced by diverse strategy rollout and critical self-judgment. Experiments on ALFWorld, WebShop, and SciWorld show that StraTA consistently improves both sample efficiency and final performance over strong baselines. StraTA reaches success rates of 93.1% on ALFWorld and 84.2% on WebShop. On SciWorld, StraTA attains a 63.5% overall score, outperforming frontier closed-source models.
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Robust Causal Discovery under Imperfect Structural Constraints
Nov 10, 2025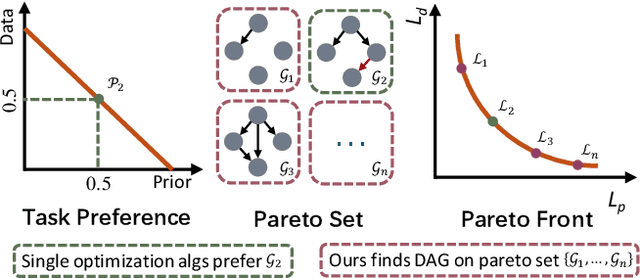
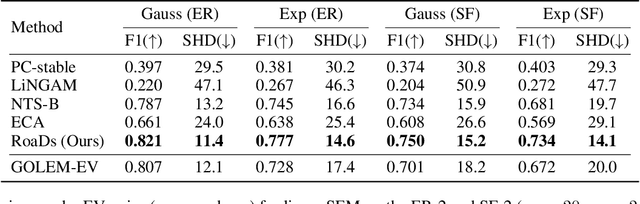
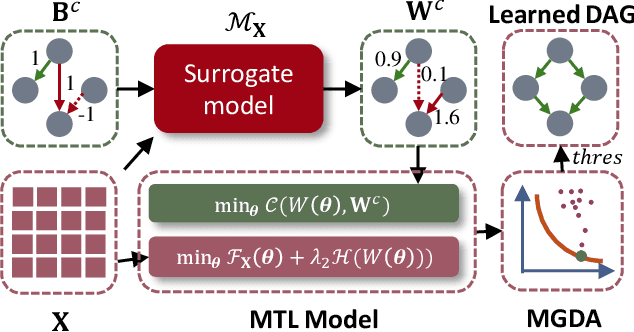
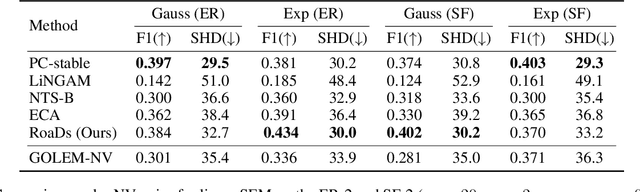
Robust causal discovery from observational data under imperfect prior knowledge remains a significant and largely unresolved challenge. Existing methods typically presuppose perfect priors or can only handle specific, pre-identified error types. And their performance degrades substantially when confronted with flawed constraints of unknown location and type. This decline arises because most of them rely on inflexible and biased thresholding strategies that may conflict with the data distribution. To overcome these limitations, we propose to harmonizes knowledge and data through prior alignment and conflict resolution. First, we assess the credibility of imperfect structural constraints through a surrogate model, which then guides a sparse penalization term measuring the loss between the learned and constrained adjacency matrices. We theoretically prove that, under ideal assumption, the knowledge-driven objective aligns with the data-driven objective. Furthermore, to resolve conflicts when this assumption is violated, we introduce a multi-task learning framework optimized via multi-gradient descent, jointly minimizing both objectives. Our proposed method is robust to both linear and nonlinear settings. Extensive experiments, conducted under diverse noise conditions and structural equation model types, demonstrate the effectiveness and efficiency of our method under imperfect structural constraints.
Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Sep 18, 2025



Recent studies have demonstrated the importance of high-quality visual representations in image generation and have highlighted the limitations of generative models in image understanding. As a generative paradigm originally designed for natural language, autoregressive models face similar challenges. In this work, we present the first systematic investigation into the mechanisms of applying the next-token prediction paradigm to the visual domain. We identify three key properties that hinder the learning of high-level visual semantics: local and conditional dependence, inter-step semantic inconsistency, and spatial invariance deficiency. We show that these issues can be effectively addressed by introducing self-supervised objectives during training, leading to a novel training framework, Self-guided Training for AutoRegressive models (ST-AR). Without relying on pre-trained representation models, ST-AR significantly enhances the image understanding ability of autoregressive models and leads to improved generation quality. Specifically, ST-AR brings approximately 42% FID improvement for LlamaGen-L and 49% FID improvement for LlamaGen-XL, while maintaining the same sampling strategy.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

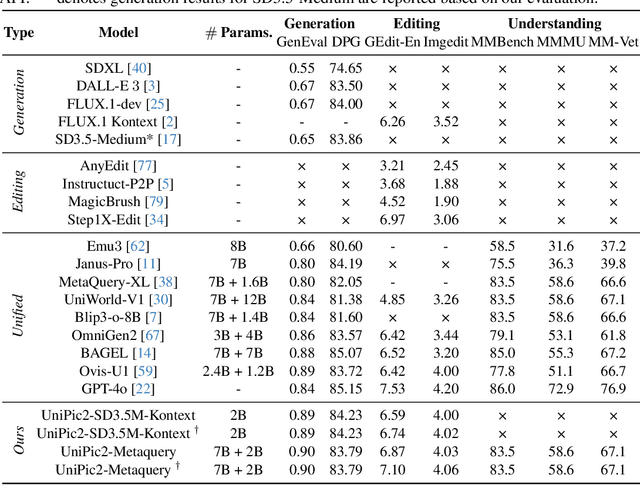
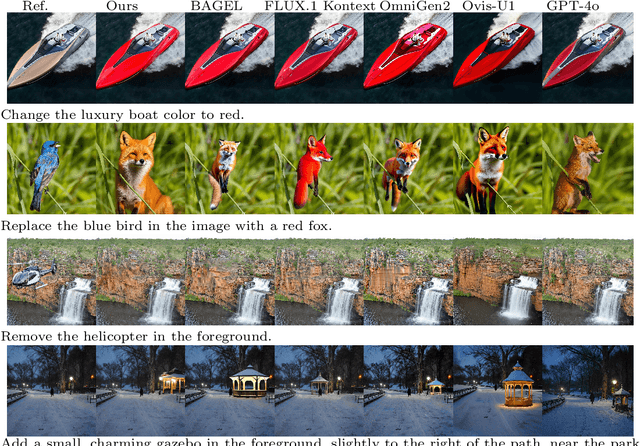
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Transition Models: Rethinking the Generative Learning Objective
Sep 04, 2025

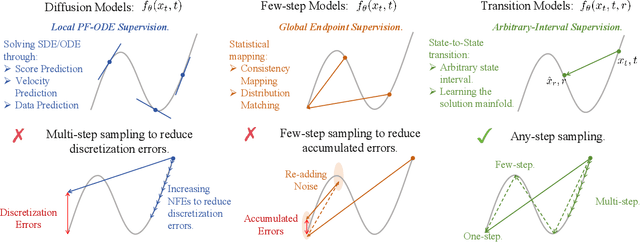

A fundamental dilemma in generative modeling persists: iterative diffusion models achieve outstanding fidelity, but at a significant computational cost, while efficient few-step alternatives are constrained by a hard quality ceiling. This conflict between generation steps and output quality arises from restrictive training objectives that focus exclusively on either infinitesimal dynamics (PF-ODEs) or direct endpoint prediction. We address this challenge by introducing an exact, continuous-time dynamics equation that analytically defines state transitions across any finite time interval. This leads to a novel generative paradigm, Transition Models (TiM), which adapt to arbitrary-step transitions, seamlessly traversing the generative trajectory from single leaps to fine-grained refinement with more steps. Despite having only 865M parameters, TiM achieves state-of-the-art performance, surpassing leading models such as SD3.5 (8B parameters) and FLUX.1 (12B parameters) across all evaluated step counts. Importantly, unlike previous few-step generators, TiM demonstrates monotonic quality improvement as the sampling budget increases. Additionally, when employing our native-resolution strategy, TiM delivers exceptional fidelity at resolutions up to 4096x4096.
SlotPi: Physics-informed Object-centric Reasoning Models
Jun 12, 2025Understanding and reasoning about dynamics governed by physical laws through visual observation, akin to human capabilities in the real world, poses significant challenges. Currently, object-centric dynamic simulation methods, which emulate human behavior, have achieved notable progress but overlook two critical aspects: 1) the integration of physical knowledge into models. Humans gain physical insights by observing the world and apply this knowledge to accurately reason about various dynamic scenarios; 2) the validation of model adaptability across diverse scenarios. Real-world dynamics, especially those involving fluids and objects, demand models that not only capture object interactions but also simulate fluid flow characteristics. To address these gaps, we introduce SlotPi, a slot-based physics-informed object-centric reasoning model. SlotPi integrates a physical module based on Hamiltonian principles with a spatio-temporal prediction module for dynamic forecasting. Our experiments highlight the model's strengths in tasks such as prediction and Visual Question Answering (VQA) on benchmark and fluid datasets. Furthermore, we have created a real-world dataset encompassing object interactions, fluid dynamics, and fluid-object interactions, on which we validated our model's capabilities. The model's robust performance across all datasets underscores its strong adaptability, laying a foundation for developing more advanced world models.
Conservation-informed Graph Learning for Spatiotemporal Dynamics Prediction
Dec 30, 2024



Data-centric methods have shown great potential in understanding and predicting spatiotemporal dynamics, enabling better design and control of the object system. However, pure deep learning models often lack interpretability, fail to obey intrinsic physics, and struggle to cope with the various domains. While geometry-based methods, e.g., graph neural networks (GNNs), have been proposed to further tackle these challenges, they still need to find the implicit physical laws from large datasets and rely excessively on rich labeled data. In this paper, we herein introduce the conservation-informed GNN (CiGNN), an end-to-end explainable learning framework, to learn spatiotemporal dynamics based on limited training data. The network is designed to conform to the general conservation law via symmetry, where conservative and non-conservative information passes over a multiscale space enhanced by a latent temporal marching strategy. The efficacy of our model has been verified in various spatiotemporal systems based on synthetic and real-world datasets, showing superiority over baseline models. Results demonstrate that CiGNN exhibits remarkable accuracy and generalization ability, and is readily applicable to learning for prediction of various spatiotemporal dynamics in a spatial domain with complex geometry.
P$^2$C$^2$Net: PDE-Preserved Coarse Correction Network for efficient prediction of spatiotemporal dynamics
Oct 29, 2024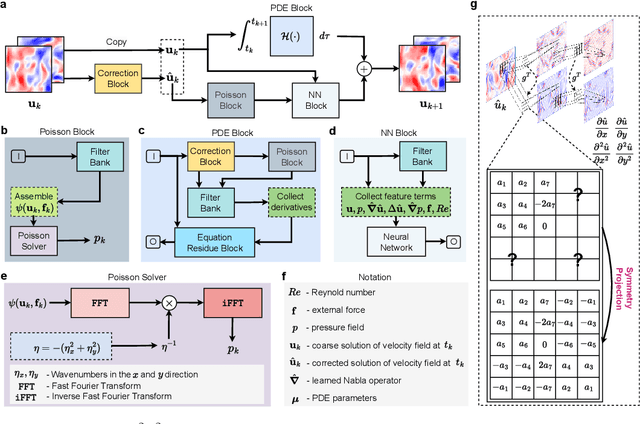
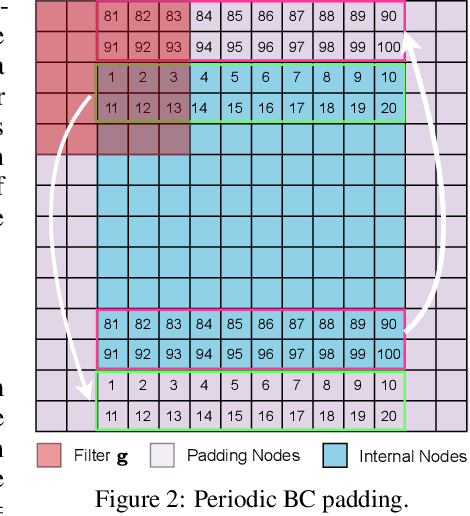
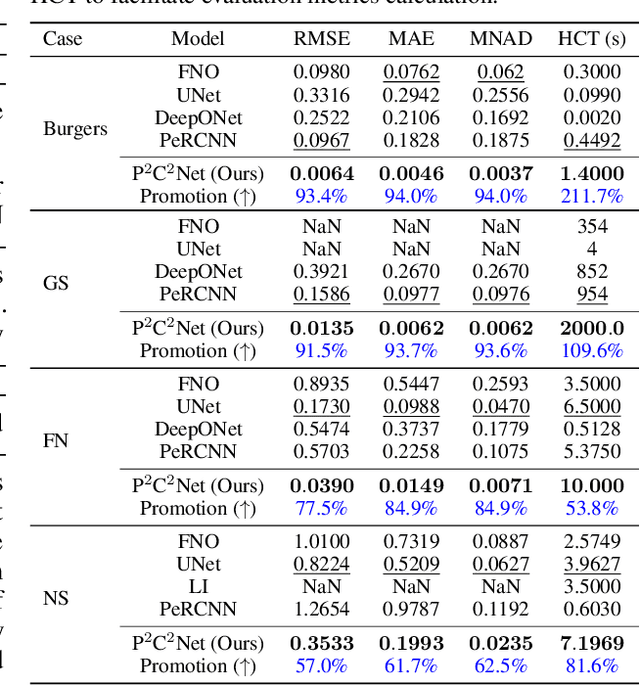
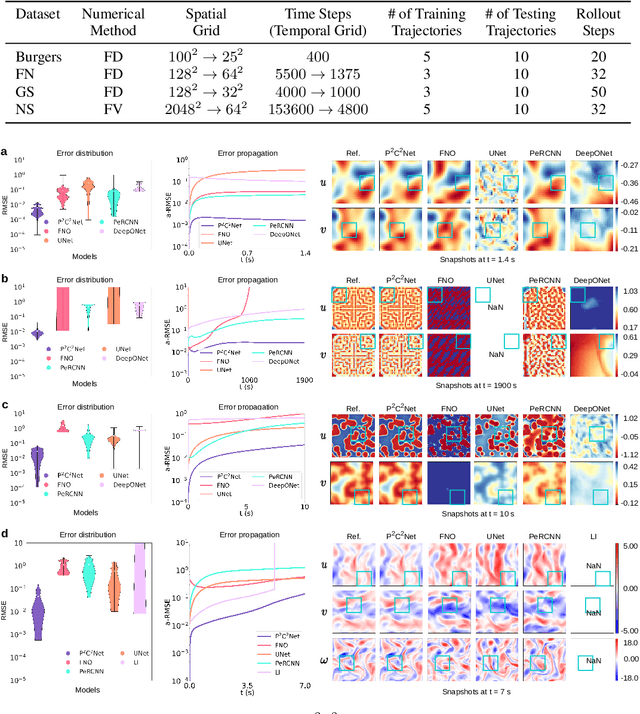
When solving partial differential equations (PDEs), classical numerical methods often require fine mesh grids and small time stepping to meet stability, consistency, and convergence conditions, leading to high computational cost. Recently, machine learning has been increasingly utilized to solve PDE problems, but they often encounter challenges related to interpretability, generalizability, and strong dependency on rich labeled data. Hence, we introduce a new PDE-Preserved Coarse Correction Network (P$^2$C$^2$Net) to efficiently solve spatiotemporal PDE problems on coarse mesh grids in small data regimes. The model consists of two synergistic modules: (1) a trainable PDE block that learns to update the coarse solution (i.e., the system state), based on a high-order numerical scheme with boundary condition encoding, and (2) a neural network block that consistently corrects the solution on the fly. In particular, we propose a learnable symmetric Conv filter, with weights shared over the entire model, to accurately estimate the spatial derivatives of PDE based on the neural-corrected system state. The resulting physics-encoded model is capable of handling limited training data (e.g., 3--5 trajectories) and accelerates the prediction of PDE solutions on coarse spatiotemporal grids while maintaining a high accuracy. P$^2$C$^2$Net achieves consistent state-of-the-art performance with over 50\% gain (e.g., in terms of relative prediction error) across four datasets covering complex reaction-diffusion processes and turbulent flows.