 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Low-Dimensional Representation for O-RAN Testing via Transformer-ESN
Apr 14, 2026Open Radio Access Network (O-RAN) architectures enhance flexibility for 6G and NextG networks. However, it also brings significant challenges in O-RAN testing with evaluating abundant, high-dimensional key performance indicators (KPIs). In this paper, we introduce a novel two-stage framework to learn temporally-aware low-dimensional representations of O-RAN testing KPIs. To be specific, stage one employs an information-theoretic H-score to train a hybrid self-attentive transformer and echo state network (ESN) reservoir, called Transformer-ESN, capturing temporal dynamics and producing task-aligned $8$-dimensional embeddings. Stage two evaluates these embeddings by training a lightweight multilayer perceptron (MLP) predictor exclusively on them for key target KPIs such as reference signal received quality (RSRQ) and spectral efficiency. Using real-world O-RAN testbed data (video streaming with interference), our approach demonstrates a significant advantage specifically when training samples are very limited. In this scenario, the low-dimensional representations learned from the Transformer-ESN yield mean square error (MSE) reductions of up to 41.9\% for RSRQ and 29.9\% for spectral efficiency compared to predictions from the original high-dimensional data. The framework exhibits high efficiency for O-RAN testing, significantly reducing testing complexities for O-RAN systems.
Implicit Patterns in LLM-Based Binary Analysis
Mar 19, 2026Binary vulnerability analysis is increasingly performed by LLM-based agents in an iterative, multi-pass manner, with the model as the core decision-maker. However, how such systems organize exploration over hundreds of reasoning steps remains poorly understood, due to limited context windows and implicit token-level behaviors. We present the first large-scale, trace-level study showing that multi-pass LLM reasoning gives rise to structured, token-level implicit patterns. Analyzing 521 binaries with 99,563 reasoning steps, we identify four dominant patterns: early pruning, path-dependent lock-in, targeted backtracking, and knowledge-guided prioritization that emerge implicitly from reasoning traces. These token-level implicit patterns serve as an abstraction of LLM reasoning: instead of explicit control-flow or predefined heuristics, exploration is organized through implicit decisions regulating path selection, commitment, and revision. Our analysis shows these patterns form a stable, structured system with distinct temporal roles and measurable characteristics. Our results provide the first systematic characterization of LLM-driven binary analysis and a foundation for more reliable analysis systems.
HiRQA: Hierarchical Ranking and Quality Alignment for Opinion-Unaware Image Quality Assessment
Aug 20, 2025Despite significant progress in no-reference image quality assessment (NR-IQA), dataset biases and reliance on subjective labels continue to hinder their generalization performance. We propose HiRQA, Hierarchical Ranking and Quality Alignment), a self-supervised, opinion-unaware framework that offers a hierarchical, quality-aware embedding through a combination of ranking and contrastive learning. Unlike prior approaches that depend on pristine references or auxiliary modalities at inference time, HiRQA predicts quality scores using only the input image. We introduce a novel higher-order ranking loss that supervises quality predictions through relational ordering across distortion pairs, along with an embedding distance loss that enforces consistency between feature distances and perceptual differences. A training-time contrastive alignment loss, guided by structured textual prompts, further enhances the learned representation. Trained only on synthetic distortions, HiRQA generalizes effectively to authentic degradations, as demonstrated through evaluation on various distortions such as lens flare, haze, motion blur, and low-light conditions. For real-time deployment, we introduce \textbf{HiRQA-S}, a lightweight variant with an inference time of only 3.5 ms per image. Extensive experiments across synthetic and authentic benchmarks validate HiRQA's state-of-the-art (SOTA) performance, strong generalization ability, and scalability.
SlotPi: Physics-informed Object-centric Reasoning Models
Jun 12, 2025Understanding and reasoning about dynamics governed by physical laws through visual observation, akin to human capabilities in the real world, poses significant challenges. Currently, object-centric dynamic simulation methods, which emulate human behavior, have achieved notable progress but overlook two critical aspects: 1) the integration of physical knowledge into models. Humans gain physical insights by observing the world and apply this knowledge to accurately reason about various dynamic scenarios; 2) the validation of model adaptability across diverse scenarios. Real-world dynamics, especially those involving fluids and objects, demand models that not only capture object interactions but also simulate fluid flow characteristics. To address these gaps, we introduce SlotPi, a slot-based physics-informed object-centric reasoning model. SlotPi integrates a physical module based on Hamiltonian principles with a spatio-temporal prediction module for dynamic forecasting. Our experiments highlight the model's strengths in tasks such as prediction and Visual Question Answering (VQA) on benchmark and fluid datasets. Furthermore, we have created a real-world dataset encompassing object interactions, fluid dynamics, and fluid-object interactions, on which we validated our model's capabilities. The model's robust performance across all datasets underscores its strong adaptability, laying a foundation for developing more advanced world models.
DGIQA: Depth-guided Feature Attention and Refinement for Generalizable Image Quality Assessment
May 29, 2025



A long-held challenge in no-reference image quality assessment (NR-IQA) learning from human subjective perception is the lack of objective generalization to unseen natural distortions. To address this, we integrate a novel Depth-Guided cross-attention and refinement (Depth-CAR) mechanism, which distills scene depth and spatial features into a structure-aware representation for improved NR-IQA. This brings in the knowledge of object saliency and relative contrast of the scene for more discriminative feature learning. Additionally, we introduce the idea of TCB (Transformer-CNN Bridge) to fuse high-level global contextual dependencies from a transformer backbone with local spatial features captured by a set of hierarchical CNN (convolutional neural network) layers. We implement TCB and Depth-CAR as multimodal attention-based projection functions to select the most informative features, which also improve training time and inference efficiency. Experimental results demonstrate that our proposed DGIQA model achieves state-of-the-art (SOTA) performance on both synthetic and authentic benchmark datasets. More importantly, DGIQA outperforms SOTA models on cross-dataset evaluations as well as in assessing natural image distortions such as low-light effects, hazy conditions, and lens flares.
Are Large Language Models Ready for Travel Planning?
Oct 22, 2024
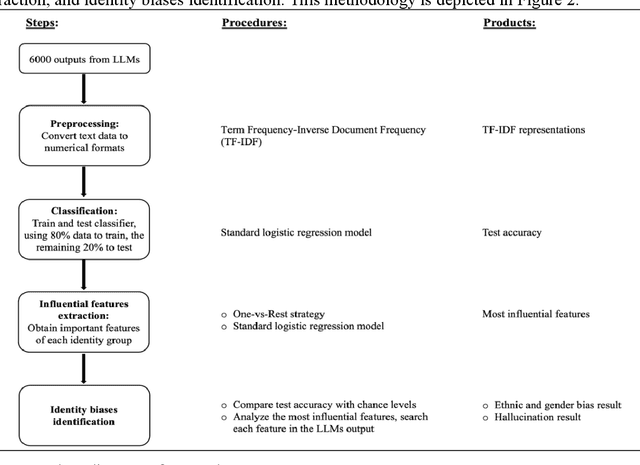

While large language models (LLMs) show promise in hospitality and tourism, their ability to provide unbiased service across demographic groups remains unclear. This paper explores gender and ethnic biases when LLMs are utilized as travel planning assistants. To investigate this issue, we apply machine learning techniques to analyze travel suggestions generated from three open-source LLMs. Our findings reveal that the performance of race and gender classifiers substantially exceeds random chance, indicating differences in how LLMs engage with varied subgroups. Specifically, outputs align with cultural expectations tied to certain races and genders. To minimize the effect of these stereotypes, we used a stop-word classification strategy, which decreased identifiable differences, with no disrespectful terms found. However, hallucinations related to African American and gender minority groups were noted. In conclusion, while LLMs can generate travel plans seemingly free from bias, it remains essential to verify the accuracy and appropriateness of their recommendations.
UCFE: A User-Centric Financial Expertise Benchmark for Large Language Models
Oct 22, 2024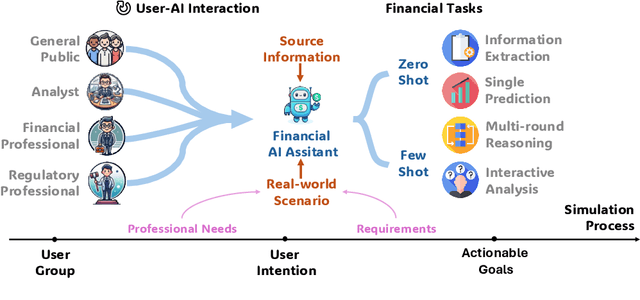
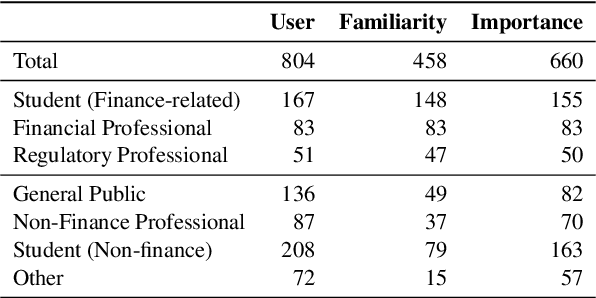
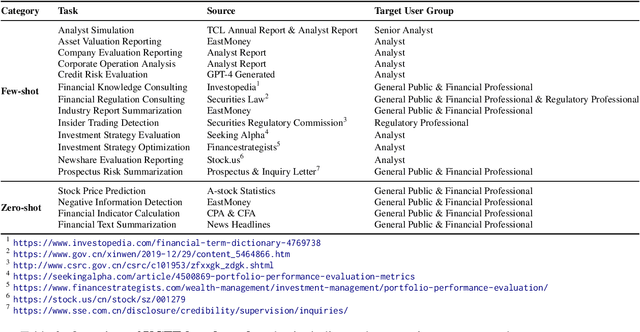
This paper introduces the UCFE: User-Centric Financial Expertise benchmark, an innovative framework designed to evaluate the ability of large language models (LLMs) to handle complex real-world financial tasks. UCFE benchmark adopts a hybrid approach that combines human expert evaluations with dynamic, task-specific interactions to simulate the complexities of evolving financial scenarios. Firstly, we conducted a user study involving 804 participants, collecting their feedback on financial tasks. Secondly, based on this feedback, we created our dataset that encompasses a wide range of user intents and interactions. This dataset serves as the foundation for benchmarking 12 LLM services using the LLM-as-Judge methodology. Our results show a significant alignment between benchmark scores and human preferences, with a Pearson correlation coefficient of 0.78, confirming the effectiveness of the UCFE dataset and our evaluation approach. UCFE benchmark not only reveals the potential of LLMs in the financial sector but also provides a robust framework for assessing their performance and user satisfaction. The benchmark dataset and evaluation code are available.
Science Out of Its Ivory Tower: Improving Accessibility with Reinforcement Learning
Oct 22, 2024A vast amount of scholarly work is published daily, yet much of it remains inaccessible to the general public due to dense jargon and complex language. To address this challenge in science communication, we introduce a reinforcement learning framework that fine-tunes a language model to rewrite scholarly abstracts into more comprehensible versions. Guided by a carefully balanced combination of word- and sentence-level accessibility rewards, our language model effectively substitutes technical terms with more accessible alternatives, a task which models supervised fine-tuned or guided by conventional readability measures struggle to accomplish. Our best model adjusts the readability level of scholarly abstracts by approximately six U.S. grade levels -- in other words, from a postgraduate to a high school level. This translates to roughly a 90% relative boost over the supervised fine-tuning baseline, all while maintaining factual accuracy and high-quality language. An in-depth analysis of our approach shows that balanced rewards lead to systematic modifications in the base model, likely contributing to smoother optimization and superior performance. We envision this work as a step toward bridging the gap between scholarly research and the general public, particularly younger readers and those without a college degree.
ViTGuard: Attention-aware Detection against Adversarial Examples for Vision Transformer
Sep 20, 2024The use of transformers for vision tasks has challenged the traditional dominant role of convolutional neural networks (CNN) in computer vision (CV). For image classification tasks, Vision Transformer (ViT) effectively establishes spatial relationships between patches within images, directing attention to important areas for accurate predictions. However, similar to CNNs, ViTs are vulnerable to adversarial attacks, which mislead the image classifier into making incorrect decisions on images with carefully designed perturbations. Moreover, adversarial patch attacks, which introduce arbitrary perturbations within a small area, pose a more serious threat to ViTs. Even worse, traditional detection methods, originally designed for CNN models, are impractical or suffer significant performance degradation when applied to ViTs, and they generally overlook patch attacks. In this paper, we propose ViTGuard as a general detection method for defending ViT models against adversarial attacks, including typical attacks where perturbations spread over the entire input and patch attacks. ViTGuard uses a Masked Autoencoder (MAE) model to recover randomly masked patches from the unmasked regions, providing a flexible image reconstruction strategy. Then, threshold-based detectors leverage distinctive ViT features, including attention maps and classification (CLS) token representations, to distinguish between normal and adversarial samples. The MAE model does not involve any adversarial samples during training, ensuring the effectiveness of our detectors against unseen attacks. ViTGuard is compared with seven existing detection methods under nine attacks across three datasets. The evaluation results show the superiority of ViTGuard over existing detectors. Finally, considering the potential detection evasion, we further demonstrate ViTGuard's robustness against adaptive attacks for evasion.
Simplifying Scholarly Abstracts for Accessible Digital Libraries
Aug 07, 2024Standing at the forefront of knowledge dissemination, digital libraries curate vast collections of scientific literature. However, these scholarly writings are often laden with jargon and tailored for domain experts rather than the general public. As librarians, we strive to offer services to a diverse audience, including those with lower reading levels. To extend our services beyond mere access, we propose fine-tuning a language model to rewrite scholarly abstracts into more comprehensible versions, thereby making scholarly literature more accessible when requested. We began by introducing a corpus specifically designed for training models to simplify scholarly abstracts. This corpus consists of over three thousand pairs of abstracts and significance statements from diverse disciplines. We then fine-tuned four language models using this corpus. The outputs from the models were subsequently examined both quantitatively for accessibility and semantic coherence, and qualitatively for language quality, faithfulness, and completeness. Our findings show that the resulting models can improve readability by over three grade levels, while maintaining fidelity to the original content. Although commercial state-of-the-art models still hold an edge, our models are much more compact, can be deployed locally in an affordable manner, and alleviate the privacy concerns associated with using commercial models. We envision this work as a step toward more inclusive and accessible libraries, improving our services for young readers and those without a college degree.