 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIFT: Stochastic Hidden-Trajectory Deflection for Removing Diffusion-based Watermark
Apr 01, 2026Diffusion-based watermarking methods embed verifiable marks by manipulating the initial noise or the reverse diffusion trajectory. However, these methods share a critical assumption: verification can succeed only if the diffusion trajectory can be faithfully reconstructed. This reliance on trajectory recovery constitutes a fundamental and exploitable vulnerability. We propose $\underline{\mathbf{S}}$tochastic $\underline{\mathbf{Hi}}$dden-Trajectory De$\underline{\mathbf{f}}$lec$\underline{\mathbf{t}}$ion ($\mathbf{SHIFT}$), a training-free attack that exploits this common weakness across diverse watermarking paradigms. SHIFT leverages stochastic diffusion resampling to deflect the generative trajectory in latent space, making the reconstructed image statistically decoupled from the original watermark-embedded trajectory while preserving strong visual quality and semantic consistency. Extensive experiments on nine representative watermarking methods spanning noise-space, frequency-domain, and optimization-based paradigms show that SHIFT achieves 95%--100% attack success rates with nearly no loss in semantic quality, without requiring any watermark-specific knowledge or model retraining.
Diffusion-Based Makeup Transfer with Facial Region-Aware Makeup Features
Mar 20, 2026Current diffusion-based makeup transfer methods commonly use the makeup information encoded by off-the-shelf foundation models (e.g., CLIP) as condition to preserve the makeup style of reference image in the generation. Although effective, these works mainly have two limitations: (1) foundation models pre-trained for generic tasks struggle to capture makeup styles; (2) the makeup features of reference image are injected to the diffusion denoising model as a whole for global makeup transfer, overlooking the facial region-aware makeup features (i.e., eyes, mouth, etc) and limiting the regional controllability for region-specific makeup transfer. To address these, in this work, we propose Facial Region-Aware Makeup features (FRAM), which has two stages: (1) makeup CLIP fine-tuning; (2) identity and facial region-aware makeup injection. For makeup CLIP fine-tuning, unlike prior works using off-the-shelf CLIP, we synthesize annotated makeup style data using GPT-o3 and text-driven image editing model, and then use the data to train a makeup CLIP encoder through self-supervised and image-text contrastive learning. For identity and facial region-aware makeup injection, we construct before-and-after makeup image pairs from the edited images in stage 1 and then use them to learn to inject identity of source image and makeup of reference image to the diffusion denoising model for makeup transfer. Specifically, we use learnable tokens to query the makeup CLIP encoder to extract facial region-aware makeup features for makeup injection, which is learned via an attention loss to enable regional control. As for identity injection, we use a ControlNet Union to encode source image and its 3D mesh simultaneously. The experimental results verify the superiority of our regional controllability and our makeup transfer performance.
SLICE: Semantic Latent Injection via Compartmentalized Embedding for Image Watermarking
Mar 13, 2026Watermarking the initial noise of diffusion models has emerged as a promising approach for image provenance, but content-independent noise patterns can be forged via inversion and regeneration attacks. Recent semantic-aware watermarking methods improve robustness by conditioning verification on image semantics. However, their reliance on a single global semantic binding makes them vulnerable to localized but globally coherent semantic edits. To address this limitation and provide a trustworthy semantic-aware watermark, we propose $\underline{\textbf{S}}$emantic $\underline{\textbf{L}}$atent $\underline{\textbf{I}}$njection via $\underline{\textbf{C}}$ompartmentalized $\underline{\textbf{E}}$mbedding ($\textbf{SLICE}$). Our framework decouples image semantics into four semantic factors (subject, environment, action, and detail) and precisely anchors them to distinct regions in the initial Gaussian noise. This fine-grained semantic binding enables advanced watermark verification where semantic tampering is detectable and localizable. We theoretically justify why SLICE enables robust and reliable tamper localization and provides statistical guarantees on false-accept rates. Experimental results demonstrate that SLICE significantly outperforms existing baselines against advanced semantic-guided regeneration attacks, substantially reducing attack success while preserving image quality and semantic fidelity. Overall, SLICE offers a practical, training-free provenance solution that is both fine-grained in diagnosis and robust to realistic adversarial manipulations.
Breaking Semantic-Aware Watermarks via LLM-Guided Coherence-Preserving Semantic Injection
Feb 25, 2026Generative images have proliferated on Web platforms in social media and online copyright distribution scenarios, and semantic watermarking has increasingly been integrated into diffusion models to support reliable provenance tracking and forgery prevention for web content. Traditional noise-layer-based watermarking, however, remains vulnerable to inversion attacks that can recover embedded signals. To mitigate this, recent content-aware semantic watermarking schemes bind watermark signals to high-level image semantics, constraining local edits that would otherwise disrupt global coherence. Yet, large language models (LLMs) possess structured reasoning capabilities that enable targeted exploration of semantic spaces, allowing locally fine-grained but globally coherent semantic alterations that invalidate such bindings. To expose this overlooked vulnerability, we introduce a Coherence-Preserving Semantic Injection (CSI) attack that leverages LLM-guided semantic manipulation under embedding-space similarity constraints. This alignment enforces visual-semantic consistency while selectively perturbing watermark-relevant semantics, ultimately inducing detector misclassification. Extensive empirical results show that CSI consistently outperforms prevailing attack baselines against content-aware semantic watermarking, revealing a fundamental security weakness of current semantic watermark designs when confronted with LLM-driven semantic perturbations.
Are LLMs Better GNN Helpers? Rethinking Robust Graph Learning under Deficiencies with Iterative Refinement
Oct 02, 2025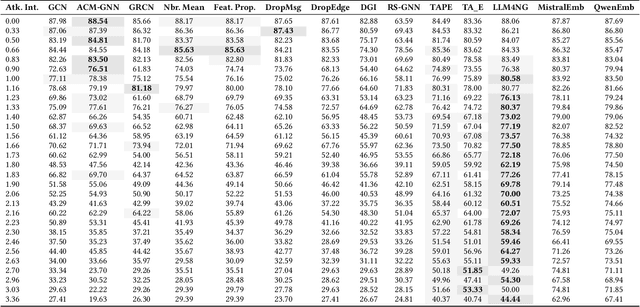
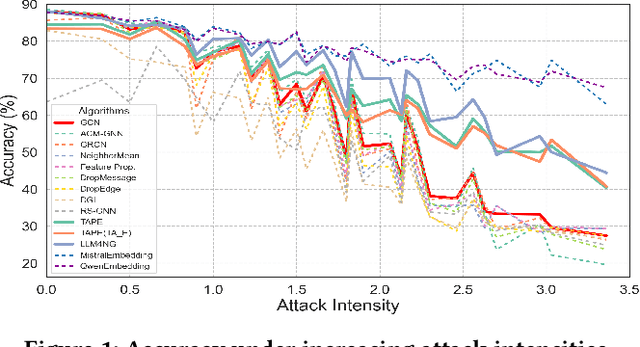
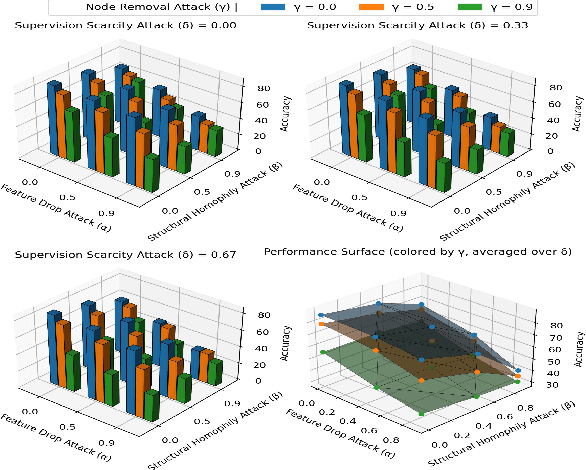
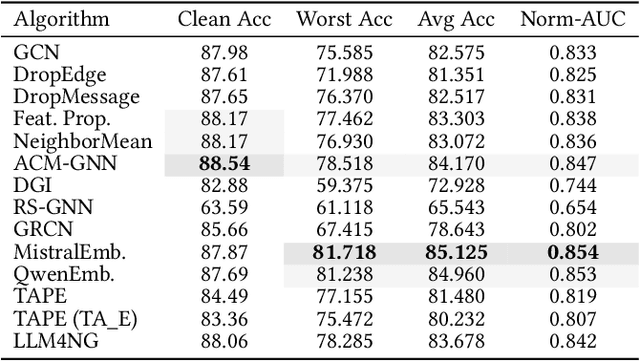
Graph Neural Networks (GNNs) are widely adopted in Web-related applications, serving as a core technique for learning from graph-structured data, such as text-attributed graphs. Yet in real-world scenarios, such graphs exhibit deficiencies that substantially undermine GNN performance. While prior GNN-based augmentation studies have explored robustness against individual imperfections, a systematic understanding of how graph-native and Large Language Models (LLMs) enhanced methods behave under compound deficiencies is still missing. Specifically, there has been no comprehensive investigation comparing conventional approaches and recent LLM-on-graph frameworks, leaving their merits unclear. To fill this gap, we conduct the first empirical study that benchmarks these two lines of methods across diverse graph deficiencies, revealing overlooked vulnerabilities and challenging the assumption that LLM augmentation is consistently superior. Building on empirical findings, we propose Robust Graph Learning via Retrieval-Augmented Contrastive Refinement (RoGRAD) framework. Unlike prior one-shot LLM-as-Enhancer designs, RoGRAD is the first iterative paradigm that leverages Retrieval-Augmented Generation (RAG) to inject retrieval-grounded augmentations by supplying class-consistent, diverse augmentations and enforcing discriminative representations through iterative graph contrastive learning. It transforms LLM augmentation for graphs from static signal injection into dynamic refinement. Extensive experiments demonstrate RoGRAD's superiority over both conventional GNN- and LLM-enhanced baselines, achieving up to 82.43% average improvement.
Citation Recommendation based on Argumentative Zoning of User Queries
Jan 30, 2025Citation recommendation aims to locate the important papers for scholars to cite. When writing the citing sentences, the authors usually hold different citing intents, which are referred to citation function in citation analysis. Since argumentative zoning is to identify the argumentative and rhetorical structure in scientific literature, we want to use this information to improve the citation recommendation task. In this paper, a multi-task learning model is built for citation recommendation and argumentative zoning classification. We also generated an annotated corpus of the data from PubMed Central based on a new argumentative zoning schema. The experimental results show that, by considering the argumentative information in the citing sentence, citation recommendation model will get better performance.
Science Out of Its Ivory Tower: Improving Accessibility with Reinforcement Learning
Oct 22, 2024A vast amount of scholarly work is published daily, yet much of it remains inaccessible to the general public due to dense jargon and complex language. To address this challenge in science communication, we introduce a reinforcement learning framework that fine-tunes a language model to rewrite scholarly abstracts into more comprehensible versions. Guided by a carefully balanced combination of word- and sentence-level accessibility rewards, our language model effectively substitutes technical terms with more accessible alternatives, a task which models supervised fine-tuned or guided by conventional readability measures struggle to accomplish. Our best model adjusts the readability level of scholarly abstracts by approximately six U.S. grade levels -- in other words, from a postgraduate to a high school level. This translates to roughly a 90% relative boost over the supervised fine-tuning baseline, all while maintaining factual accuracy and high-quality language. An in-depth analysis of our approach shows that balanced rewards lead to systematic modifications in the base model, likely contributing to smoother optimization and superior performance. We envision this work as a step toward bridging the gap between scholarly research and the general public, particularly younger readers and those without a college degree.
Self-Supervised Facial Representation Learning with Facial Region Awareness
Mar 04, 2024Self-supervised pre-training has been proved to be effective in learning transferable representations that benefit various visual tasks. This paper asks this question: can self-supervised pre-training learn general facial representations for various facial analysis tasks? Recent efforts toward this goal are limited to treating each face image as a whole, i.e., learning consistent facial representations at the image-level, which overlooks the consistency of local facial representations (i.e., facial regions like eyes, nose, etc). In this work, we make a first attempt to propose a novel self-supervised facial representation learning framework to learn consistent global and local facial representations, Facial Region Awareness (FRA). Specifically, we explicitly enforce the consistency of facial regions by matching the local facial representations across views, which are extracted with learned heatmaps highlighting the facial regions. Inspired by the mask prediction in supervised semantic segmentation, we obtain the heatmaps via cosine similarity between the per-pixel projection of feature maps and facial mask embeddings computed from learnable positional embeddings, which leverage the attention mechanism to globally look up the facial image for facial regions. To learn such heatmaps, we formulate the learning of facial mask embeddings as a deep clustering problem by assigning the pixel features from the feature maps to them. The transfer learning results on facial classification and regression tasks show that our FRA outperforms previous pre-trained models and more importantly, using ResNet as the unified backbone for various tasks, our FRA achieves comparable or even better performance compared with SOTA methods in facial analysis tasks.
Self-Supervised Representation Learning with Cross-Context Learning between Global and Hypercolumn Features
Sep 01, 2023Whilst contrastive learning yields powerful representations by matching different augmented views of the same instance, it lacks the ability to capture the similarities between different instances. One popular way to address this limitation is by learning global features (after the global pooling) to capture inter-instance relationships based on knowledge distillation, where the global features of the teacher are used to guide the learning of the global features of the student. Inspired by cross-modality learning, we extend this existing framework that only learns from global features by encouraging the global features and intermediate layer features to learn from each other. This leads to our novel self-supervised framework: cross-context learning between global and hypercolumn features (CGH), that enforces the consistency of instance relations between low- and high-level semantics. Specifically, we stack the intermediate feature maps to construct a hypercolumn representation so that we can measure instance relations using two contexts (hypercolumn and global feature) separately, and then use the relations of one context to guide the learning of the other. This cross-context learning allows the model to learn from the differences between the two contexts. The experimental results on linear classification and downstream tasks show that our method outperforms the state-of-the-art methods.
FrFT based estimation of linear and nonlinear impairments using Vision Transformer
Aug 25, 2023



To comprehensively assess optical fiber communication system conditions, it is essential to implement joint estimation of the following four critical impairments: nonlinear signal-to-noise ratio (SNRNL), optical signal-to-noise ratio (OSNR), chromatic dispersion (CD) and differential group delay (DGD). However, current studies only achieve identifying a limited number of impairments within a narrow range, due to limitations in network capabilities and lack of unified representation of impairments. To address these challenges, we adopt time-frequency signal processing based on fractional Fourier transform (FrFT) to achieve the unified representation of impairments, while employing a Transformer based neural networks (NN) to break through network performance limitations. To verify the effectiveness of the proposed estimation method, the numerical simulation is carried on a 5-channel polarization-division-multiplexed quadrature phase shift keying (PDM-QPSK) long haul optical transmission system with the symbol rate of 50 GBaud per channel, the mean absolute error (MAE) for SNRNL, OSNR, CD, and DGD estimation is 0.091 dB, 0.058 dB, 117 ps/nm, and 0.38 ps, and the monitoring window ranges from 0~20 dB, 10~30 dB, 0~51000 ps/nm, and 0~100 ps, respectively. Our proposed method achieves accurate estimation of linear and nonlinear impairments over a broad range, representing a significant advancement in the field of optical performance monitoring (OPM).