 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Voice Application Recommender System for Unhandled Utterances in Intelligent Personal Assistant
Oct 19, 2021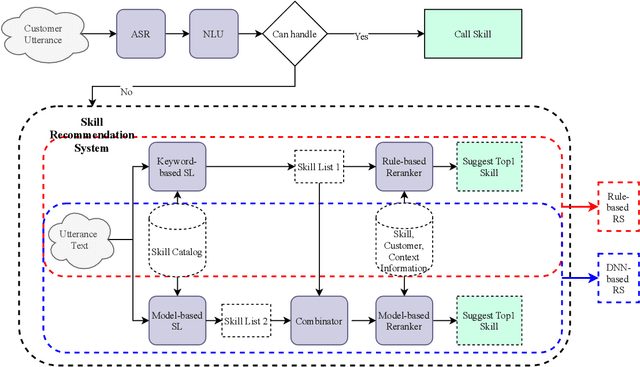
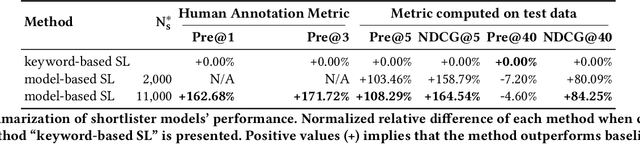
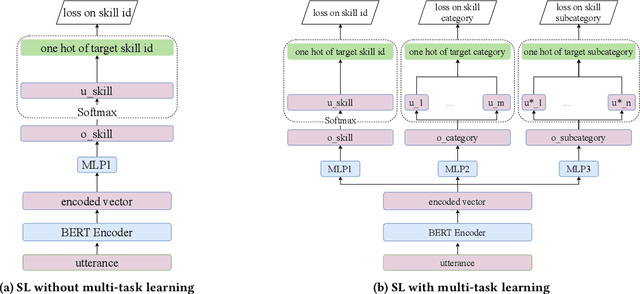

Intelligent personal assistants (IPA) enable voice applications that facilitate people's daily tasks. However, due to the complexity and ambiguity of voice requests, some requests may not be handled properly by the standard natural language understanding (NLU) component. In such cases, a simple reply like "Sorry, I don't know" hurts the user's experience and limits the functionality of IPA. In this paper, we propose a two-stage shortlister-reranker recommender system to match third-party voice applications (skills) to unhandled utterances. In this approach, a skill shortlister is proposed to retrieve candidate skills from the skill catalog by calculating both lexical and semantic similarity between skills and user requests. We also illustrate how to build a new system by using observed data collected from a baseline rule-based system, and how the exposure biases can generate discrepancy between offline and human metrics. Lastly, we present two relabeling methods that can handle the incomplete ground truth, and mitigate exposure bias. We demonstrate the effectiveness of our proposed system through extensive offline experiments. Furthermore, we present online A/B testing results that show a significant boost on user experience satisfaction.
An Efficient DP-SGD Mechanism for Large Scale NLP Models
Jul 14, 2021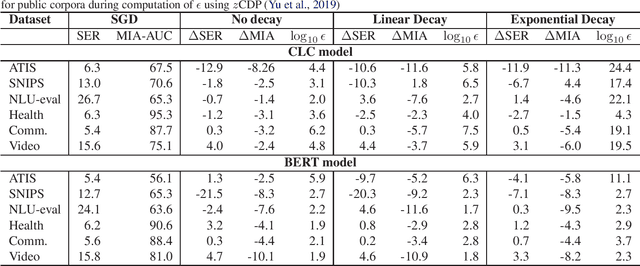
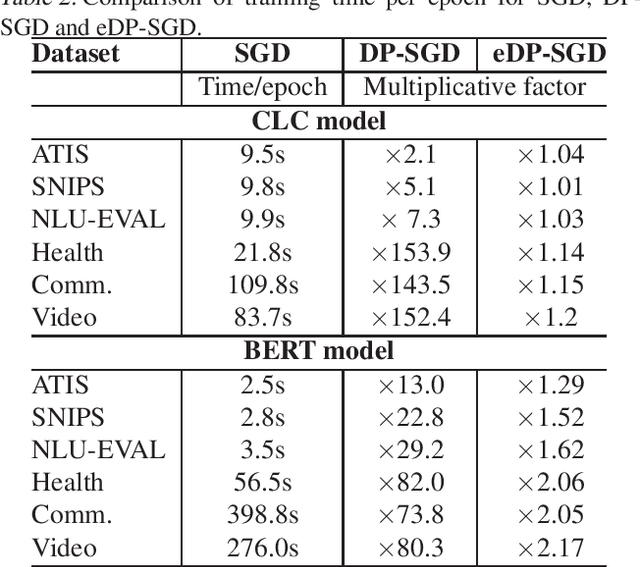
Recent advances in deep learning have drastically improved performance on many Natural Language Understanding (NLU) tasks. However, the data used to train NLU models may contain private information such as addresses or phone numbers, particularly when drawn from human subjects. It is desirable that underlying models do not expose private information contained in the training data. Differentially Private Stochastic Gradient Descent (DP-SGD) has been proposed as a mechanism to build privacy-preserving models. However, DP-SGD can be prohibitively slow to train. In this work, we propose a more efficient DP-SGD for training using a GPU infrastructure and apply it to fine-tuning models based on LSTM and transformer architectures. We report faster training times, alongside accuracy, theoretical privacy guarantees and success of Membership inference attacks for our models and observe that fine-tuning with proposed variant of DP-SGD can yield competitive models without significant degradation in training time and improvement in privacy protection. We also make observations such as looser theoretical $\epsilon, \delta$ can translate into significant practical privacy gains.