 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping LLM-based Task-Oriented Dialogue Agents via Self-Talk
Jan 10, 2024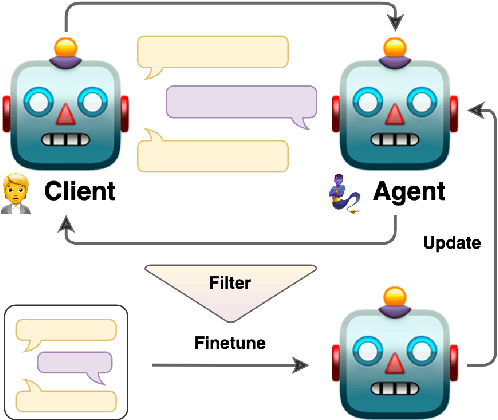

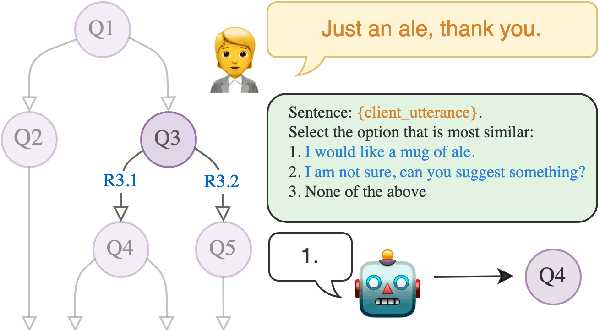

Large language models (LLMs) are powerful dialogue agents, but specializing them towards fulfilling a specific function can be challenging. Instructing tuning, i.e. tuning models on instruction and sample responses generated by humans (Ouyang et al., 2022), has proven as an effective method to do so, yet requires a number of data samples that a) might not be available or b) costly to generate. Furthermore, this cost increases when the goal is to make the LLM follow a specific workflow within a dialogue instead of single instructions. Inspired by the self-play technique in reinforcement learning and the use of LLMs to simulate human agents, we propose a more effective method for data collection through LLMs engaging in a conversation in various roles. This approach generates a training data via "self-talk" of LLMs that can be refined and utilized for supervised fine-tuning. We introduce an automated way to measure the (partial) success of a dialogue. This metric is used to filter the generated conversational data that is fed back in LLM for training. Based on our automated and human evaluations of conversation quality, we demonstrate that such self-talk data improves results. In addition, we examine the various characteristics that showcase the quality of generated dialogues and how they can be connected to their potential utility as training data.
Backward Compatibility During Data Updates by Weight Interpolation
Jan 25, 2023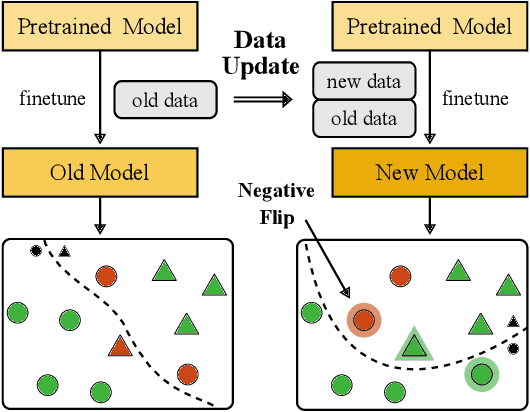



Backward compatibility of model predictions is a desired property when updating a machine learning driven application. It allows to seamlessly improve the underlying model without introducing regression bugs. In classification tasks these bugs occur in the form of negative flips. This means an instance that was correctly classified by the old model is now classified incorrectly by the updated model. This has direct negative impact on the user experience of such systems e.g. a frequently used voice assistant query is suddenly misclassified. A common reason to update the model is when new training data becomes available and needs to be incorporated. Simply retraining the model with the updated data introduces the unwanted negative flips. We study the problem of regression during data updates and propose Backward Compatible Weight Interpolation (BCWI). This method interpolates between the weights of the old and new model and we show in extensive experiments that it reduces negative flips without sacrificing the improved accuracy of the new model. BCWI is straight forward to implement and does not increase inference cost. We also explore the use of importance weighting during interpolation and averaging the weights of multiple new models in order to further reduce negative flips.
Two-stage Voice Application Recommender System for Unhandled Utterances in Intelligent Personal Assistant
Oct 19, 2021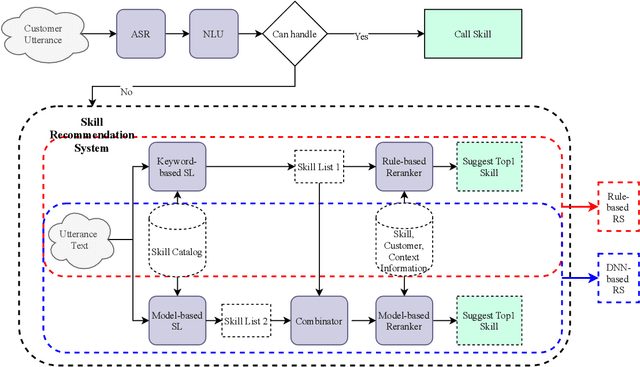
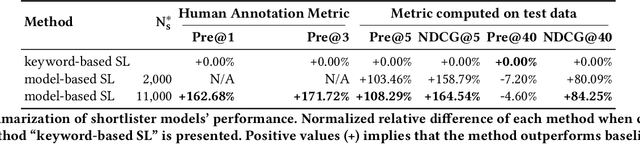
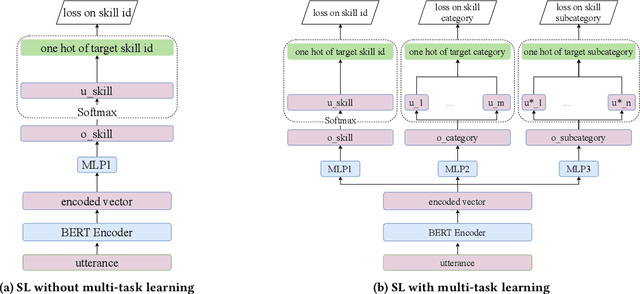

Intelligent personal assistants (IPA) enable voice applications that facilitate people's daily tasks. However, due to the complexity and ambiguity of voice requests, some requests may not be handled properly by the standard natural language understanding (NLU) component. In such cases, a simple reply like "Sorry, I don't know" hurts the user's experience and limits the functionality of IPA. In this paper, we propose a two-stage shortlister-reranker recommender system to match third-party voice applications (skills) to unhandled utterances. In this approach, a skill shortlister is proposed to retrieve candidate skills from the skill catalog by calculating both lexical and semantic similarity between skills and user requests. We also illustrate how to build a new system by using observed data collected from a baseline rule-based system, and how the exposure biases can generate discrepancy between offline and human metrics. Lastly, we present two relabeling methods that can handle the incomplete ground truth, and mitigate exposure bias. We demonstrate the effectiveness of our proposed system through extensive offline experiments. Furthermore, we present online A/B testing results that show a significant boost on user experience satisfaction.