 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Metadata-Agnostic Representations for Text-to-SQL In-Context Example Selection
Oct 17, 2024



In-context learning (ICL) is a powerful paradigm where large language models (LLMs) benefit from task demonstrations added to the prompt. Yet, selecting optimal demonstrations is not trivial, especially for complex or multi-modal tasks where input and output distributions differ. We hypothesize that forming task-specific representations of the input is key. In this paper, we propose a method to align representations of natural language questions and those of SQL queries in a shared embedding space. Our technique, dubbed MARLO - Metadata-Agnostic Representation Learning for Text-tO-SQL - uses query structure to model querying intent without over-indexing on underlying database metadata (i.e. tables, columns, or domain-specific entities of a database referenced in the question or query). This allows MARLO to select examples that are structurally and semantically relevant for the task rather than examples that are spuriously related to a certain domain or question phrasing. When used to retrieve examples based on question similarity, MARLO shows superior performance compared to generic embedding models (on average +2.9\%pt. in execution accuracy) on the Spider benchmark. It also outperforms the next best method that masks metadata information by +0.8\%pt. in execution accuracy on average, while imposing a significantly lower inference latency.
Two-stage Voice Application Recommender System for Unhandled Utterances in Intelligent Personal Assistant
Oct 19, 2021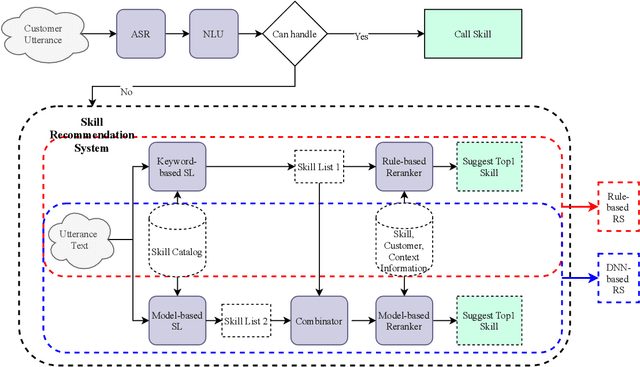
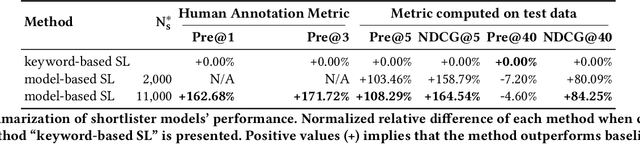
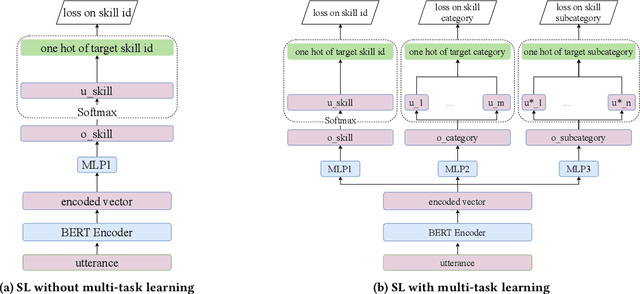

Intelligent personal assistants (IPA) enable voice applications that facilitate people's daily tasks. However, due to the complexity and ambiguity of voice requests, some requests may not be handled properly by the standard natural language understanding (NLU) component. In such cases, a simple reply like "Sorry, I don't know" hurts the user's experience and limits the functionality of IPA. In this paper, we propose a two-stage shortlister-reranker recommender system to match third-party voice applications (skills) to unhandled utterances. In this approach, a skill shortlister is proposed to retrieve candidate skills from the skill catalog by calculating both lexical and semantic similarity between skills and user requests. We also illustrate how to build a new system by using observed data collected from a baseline rule-based system, and how the exposure biases can generate discrepancy between offline and human metrics. Lastly, we present two relabeling methods that can handle the incomplete ground truth, and mitigate exposure bias. We demonstrate the effectiveness of our proposed system through extensive offline experiments. Furthermore, we present online A/B testing results that show a significant boost on user experience satisfaction.