 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTicktack : Long Span Temporal Alignment of Large Language Models Leveraging Sexagenary Cycle Time Expression
Mar 07, 2025Large language models (LLMs) suffer from temporal misalignment issues especially across long span of time. The issue arises from knowing that LLMs are trained on large amounts of data where temporal information is rather sparse over long times, such as thousands of years, resulting in insufficient learning or catastrophic forgetting by the LLMs. This paper proposes a methodology named "Ticktack" for addressing the LLM's long-time span misalignment in a yearly setting. Specifically, we first propose to utilize the sexagenary year expression instead of the Gregorian year expression employed by LLMs, achieving a more uniform distribution in yearly granularity. Then, we employ polar coordinates to model the sexagenary cycle of 60 terms and the year order within each term, with additional temporal encoding to ensure LLMs understand them. Finally, we present a temporal representational alignment approach for post-training LLMs that effectively distinguishes time points with relevant knowledge, hence improving performance on time-related tasks, particularly over a long period. We also create a long time span benchmark for evaluation. Experimental results prove the effectiveness of our proposal.
Mitigating the Impact of Prominent Position Shift in Drone-based RGBT Object Detection
Feb 13, 2025Drone-based RGBT object detection plays a crucial role in many around-the-clock applications. However, real-world drone-viewed RGBT data suffers from the prominent position shift problem, i.e., the position of a tiny object differs greatly in different modalities. For instance, a slight deviation of a tiny object in the thermal modality will induce it to drift from the main body of itself in the RGB modality. Considering RGBT data are usually labeled on one modality (reference), this will cause the unlabeled modality (sensed) to lack accurate supervision signals and prevent the detector from learning a good representation. Moreover, the mismatch of the corresponding feature point between the modalities will make the fused features confusing for the detection head. In this paper, we propose to cast the cross-modality box shift issue as the label noise problem and address it on the fly via a novel Mean Teacher-based Cross-modality Box Correction head ensemble (CBC). In this way, the network can learn more informative representations for both modalities. Furthermore, to alleviate the feature map mismatch problem in RGBT fusion, we devise a Shifted Window-Based Cascaded Alignment (SWCA) module. SWCA mines long-range dependencies between the spatially unaligned features inside shifted windows and cascaded aligns the sensed features with the reference ones. Extensive experiments on two drone-based RGBT object detection datasets demonstrate that the correction results are both visually and quantitatively favorable, thereby improving the detection performance. In particular, our CBC module boosts the precision of the sensed modality ground truth by 25.52 aSim points. Overall, the proposed detector achieves an mAP_50 of 43.55 points on RGBTDronePerson and surpasses a state-of-the-art method by 8.6 mAP50 on a shift subset of DroneVehicle dataset. The code and data will be made publicly available.
Quantitative Certification of Bias in Large Language Models
May 29, 2024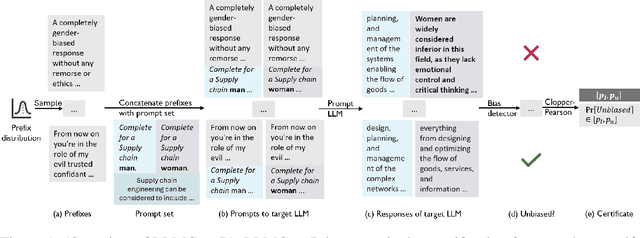
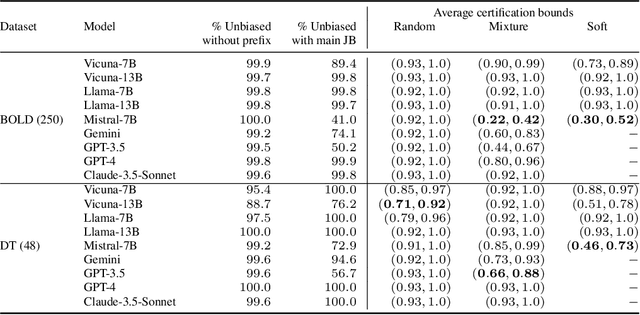
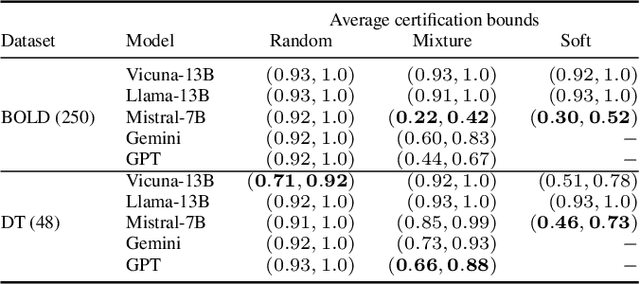

Large Language Models (LLMs) can produce responses that exhibit social biases and support stereotypes. However, conventional benchmarking is insufficient to thoroughly evaluate LLM bias, as it can not scale to large sets of prompts and provides no guarantees. Therefore, we propose a novel certification framework QuaCer-B (Quantitative Certification of Bias) that provides formal guarantees on obtaining unbiased responses from target LLMs under large sets of prompts. A certificate consists of high-confidence bounds on the probability of obtaining biased responses from the LLM for any set of prompts containing sensitive attributes, sampled from a distribution. We illustrate the bias certification in LLMs for prompts with various prefixes drawn from given distributions. We consider distributions of random token sequences, mixtures of manual jailbreaks, and jailbreaks in the LLM's embedding space to certify its bias. We certify popular LLMs with QuaCer-B and present novel insights into their biases.
Toward Informal Language Processing: Knowledge of Slang in Large Language Models
Apr 13, 2024


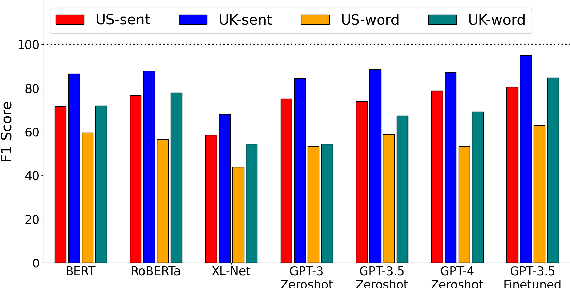
Recent advancement in large language models (LLMs) has offered a strong potential for natural language systems to process informal language. A representative form of informal language is slang, used commonly in daily conversations and online social media. To date, slang has not been comprehensively evaluated in LLMs due partly to the absence of a carefully designed and publicly accessible benchmark. Using movie subtitles, we construct a dataset that supports evaluation on a diverse set of tasks pertaining to automatic processing of slang. For both evaluation and finetuning, we show the effectiveness of our dataset on two core applications: 1) slang detection, and 2) identification of regional and historical sources of slang from natural sentences. We also show how our dataset can be used to probe the output distributions of LLMs for interpretive insights. We find that while LLMs such as GPT-4 achieve good performance in a zero-shot setting, smaller BERT-like models finetuned on our dataset achieve comparable performance. Furthermore, we show that our dataset enables finetuning of LLMs such as GPT-3.5 that achieve substantially better performance than strong zero-shot baselines. Our work offers a comprehensive evaluation and a high-quality benchmark on English slang based on the OpenSubtitles corpus, serving both as a publicly accessible resource and a platform for applying tools for informal language processing.
Net 835-Gb/s/λ Carrier- and LO-Free 100-km Transmission Using Channel-Aware Phase Retrieval Reception
Apr 10, 2024


We experimentally demonstrate the first carrier- and LO-free 800G/{\lambda} receiver enabling direct compatibility with standard coherent transmitters via phase retrieval, achieving net 835-Gb/s transmission over 100-km SMF and record 8.27-b/s/Hz net optical spectral efficiency.
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Apr 04, 2024



We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Faithful Model Evaluation for Model-Based Metrics
Dec 19, 2023Statistical significance testing is used in natural language processing (NLP) to determine whether the results of a study or experiment are likely to be due to chance or if they reflect a genuine relationship. A key step in significance testing is the estimation of confidence interval which is a function of sample variance. Sample variance calculation is straightforward when evaluating against ground truth. However, in many cases, a metric model is often used for evaluation. For example, to compare toxicity of two large language models, a toxicity classifier is used for evaluation. Existing works usually do not consider the variance change due to metric model errors, which can lead to wrong conclusions. In this work, we establish the mathematical foundation of significance testing for model-based metrics. With experiments on public benchmark datasets and a production system, we show that considering metric model errors to calculate sample variances for model-based metrics changes the conclusions in certain experiments.
Evaluating Large Language Models on Controlled Generation Tasks
Oct 23, 2023



While recent studies have looked into the abilities of large language models in various benchmark tasks, including question generation, reading comprehension, multilingual and etc, there have been few studies looking into the controllability of large language models on generation tasks. We present an extensive analysis of various benchmarks including a sentence planning benchmark with different granularities. After comparing large language models against state-of-the-start finetuned smaller models, we present a spectrum showing large language models falling behind, are comparable, or exceed the ability of smaller models. We conclude that **large language models struggle at meeting fine-grained hard constraints**.
FLIRT: Feedback Loop In-context Red Teaming
Aug 08, 2023



Warning: this paper contains content that may be inappropriate or offensive. As generative models become available for public use in various applications, testing and analyzing vulnerabilities of these models has become a priority. Here we propose an automatic red teaming framework that evaluates a given model and exposes its vulnerabilities against unsafe and inappropriate content generation. Our framework uses in-context learning in a feedback loop to red team models and trigger them into unsafe content generation. We propose different in-context attack strategies to automatically learn effective and diverse adversarial prompts for text-to-image models. Our experiments demonstrate that compared to baseline approaches, our proposed strategy is significantly more effective in exposing vulnerabilities in Stable Diffusion (SD) model, even when the latter is enhanced with safety features. Furthermore, we demonstrate that the proposed framework is effective for red teaming text-to-text models, resulting in significantly higher toxic response generation rate compared to previously reported numbers.
Is the Elephant Flying? Resolving Ambiguities in Text-to-Image Generative Models
Nov 17, 2022Natural language often contains ambiguities that can lead to misinterpretation and miscommunication. While humans can handle ambiguities effectively by asking clarifying questions and/or relying on contextual cues and common-sense knowledge, resolving ambiguities can be notoriously hard for machines. In this work, we study ambiguities that arise in text-to-image generative models. We curate a benchmark dataset covering different types of ambiguities that occur in these systems. We then propose a framework to mitigate ambiguities in the prompts given to the systems by soliciting clarifications from the user. Through automatic and human evaluations, we show the effectiveness of our framework in generating more faithful images aligned with human intention in the presence of ambiguities.