 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
Feb 05, 2026Humans rarely plan whole-body interactions with objects at the level of explicit whole-body movements. High-level intentions, such as affordance, define the goal, while coordinated balance, contact, and manipulation can emerge naturally from underlying physical and motor priors. Scaling such priors is key to enabling humanoids to compose and generalize loco-manipulation skills across diverse contexts while maintaining physically coherent whole-body coordination. To this end, we introduce InterPrior, a scalable framework that learns a unified generative controller through large-scale imitation pretraining and post-training by reinforcement learning. InterPrior first distills a full-reference imitation expert into a versatile, goal-conditioned variational policy that reconstructs motion from multimodal observations and high-level intent. While the distilled policy reconstructs training behaviors, it does not generalize reliably due to the vast configuration space of large-scale human-object interactions. To address this, we apply data augmentation with physical perturbations, and then perform reinforcement learning finetuning to improve competence on unseen goals and initializations. Together, these steps consolidate the reconstructed latent skills into a valid manifold, yielding a motion prior that generalizes beyond the training data, e.g., it can incorporate new behaviors such as interactions with unseen objects. We further demonstrate its effectiveness for user-interactive control and its potential for real robot deployment.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025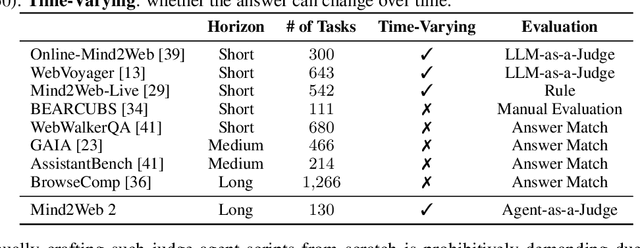
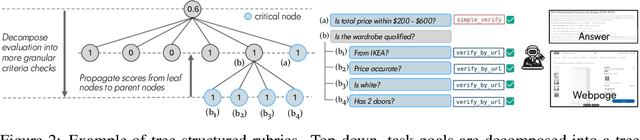

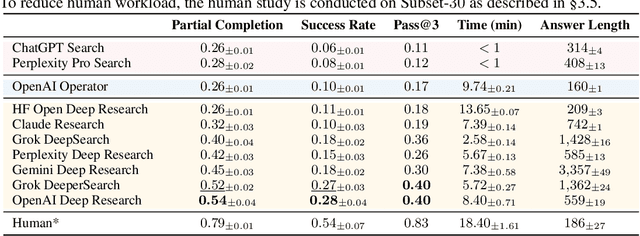
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
RAGPPI: RAG Benchmark for Protein-Protein Interactions in Drug Discovery
May 28, 2025
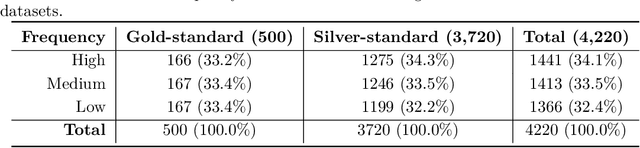


Retrieving the biological impacts of protein-protein interactions (PPIs) is essential for target identification (Target ID) in drug development. Given the vast number of proteins involved, this process remains time-consuming and challenging. Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) frameworks have supported Target ID; however, no benchmark currently exists for identifying the biological impacts of PPIs. To bridge this gap, we introduce the RAG Benchmark for PPIs (RAGPPI), a factual question-answer benchmark of 4,420 question-answer pairs that focus on the potential biological impacts of PPIs. Through interviews with experts, we identified criteria for a benchmark dataset, such as a type of QA and source. We built a gold-standard dataset (500 QA pairs) through expert-driven data annotation. We developed an ensemble auto-evaluation LLM that reflected expert labeling characteristics, which facilitates the construction of a silver-standard dataset (3,720 QA pairs). We are committed to maintaining RAGPPI as a resource to support the research community in advancing RAG systems for drug discovery QA solutions.
MAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025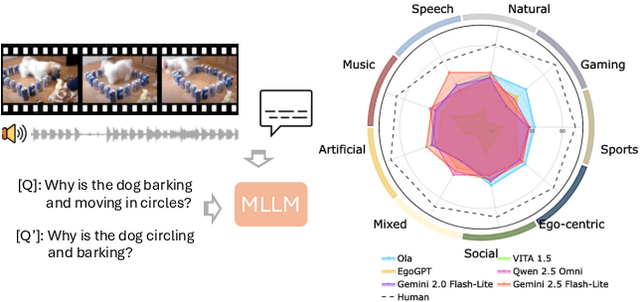
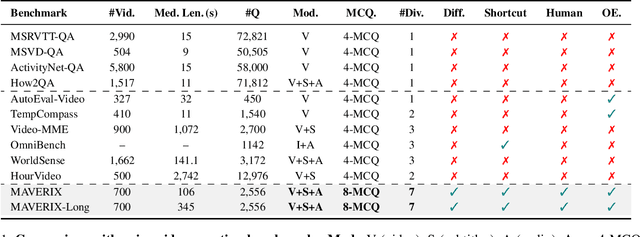
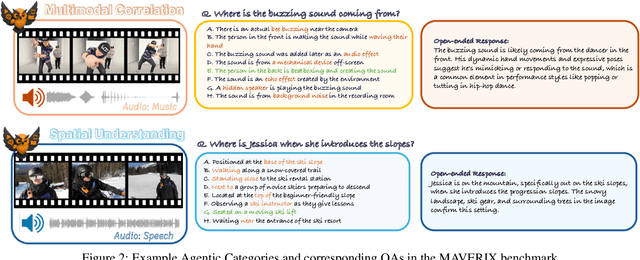
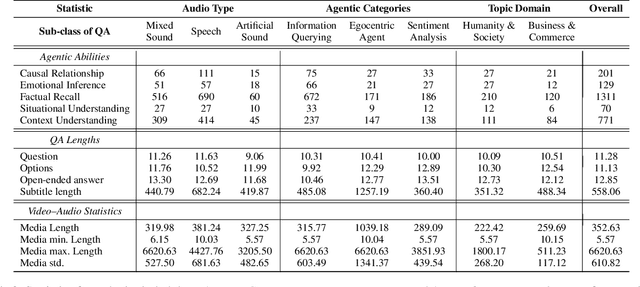
Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Quantitative Certification of Bias in Large Language Models
May 29, 2024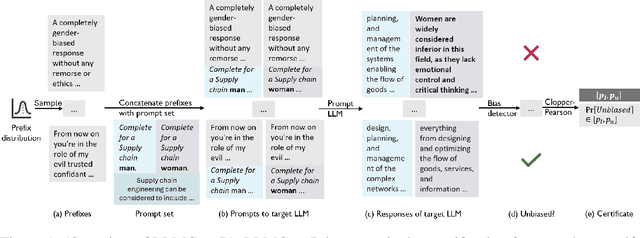
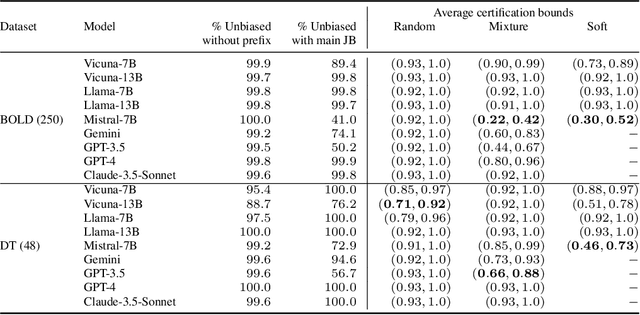
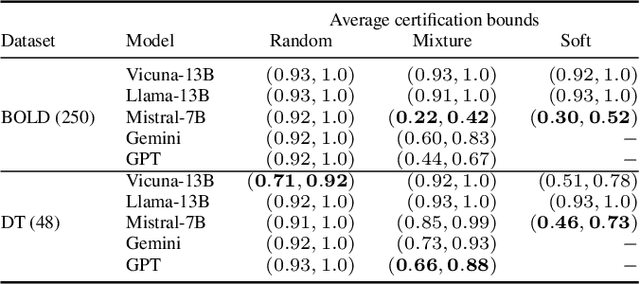

Large Language Models (LLMs) can produce responses that exhibit social biases and support stereotypes. However, conventional benchmarking is insufficient to thoroughly evaluate LLM bias, as it can not scale to large sets of prompts and provides no guarantees. Therefore, we propose a novel certification framework QuaCer-B (Quantitative Certification of Bias) that provides formal guarantees on obtaining unbiased responses from target LLMs under large sets of prompts. A certificate consists of high-confidence bounds on the probability of obtaining biased responses from the LLM for any set of prompts containing sensitive attributes, sampled from a distribution. We illustrate the bias certification in LLMs for prompts with various prefixes drawn from given distributions. We consider distributions of random token sequences, mixtures of manual jailbreaks, and jailbreaks in the LLM's embedding space to certify its bias. We certify popular LLMs with QuaCer-B and present novel insights into their biases.
Partial Federated Learning
Mar 03, 2024
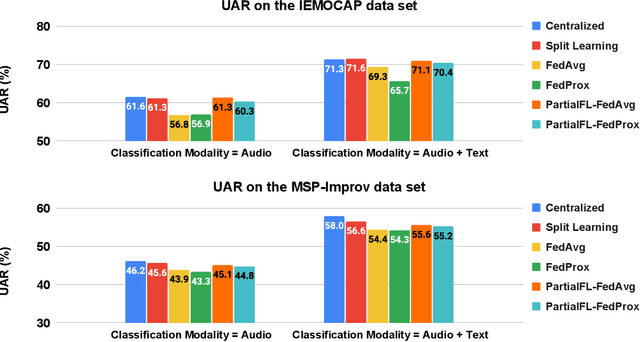
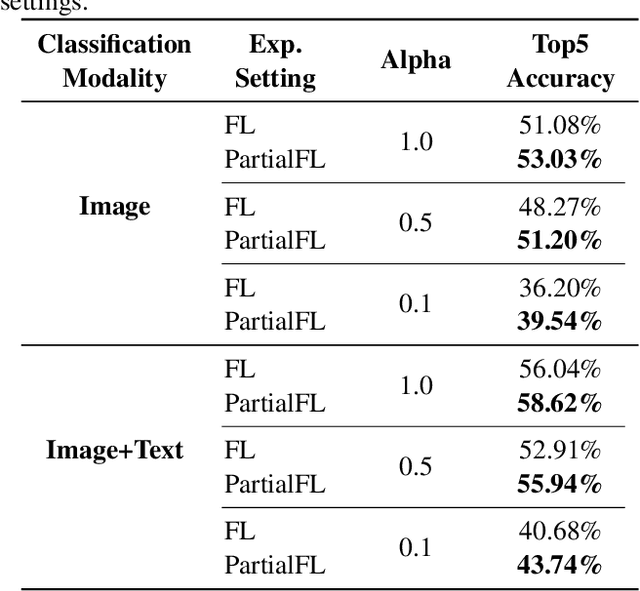
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
Reasoning Like Program Executors
Jan 27, 2022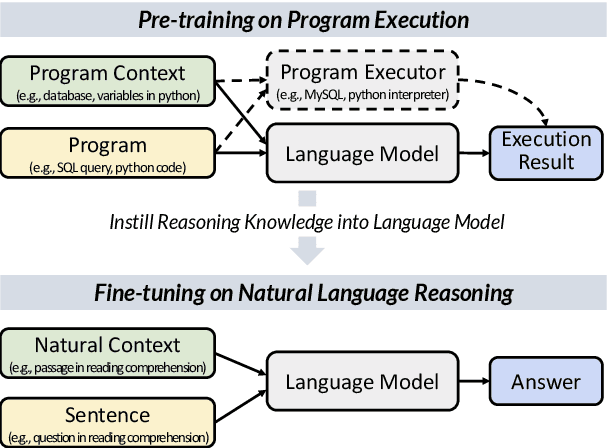

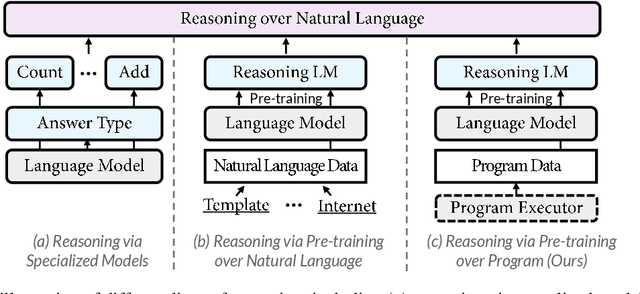
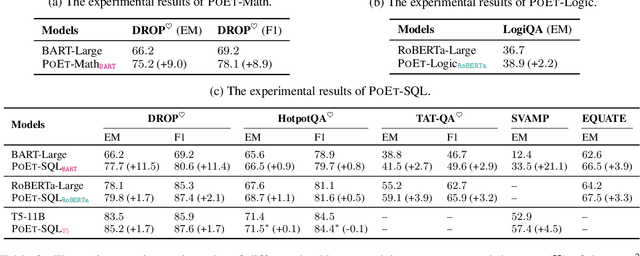
Reasoning over natural language is a long-standing goal for the research community. However, studies have shown that existing language models are inadequate in reasoning. To address the issue, we present POET, a new pre-training paradigm. Through pre-training language models with programs and their execution results, POET empowers language models to harvest the reasoning knowledge possessed in program executors via a data-driven approach. POET is conceptually simple and can be instantiated by different kinds of programs. In this paper, we show three empirically powerful instances, i.e., POET-Math, POET-Logic, and POET-SQL. Experimental results on six benchmarks demonstrate that POET can significantly boost model performance on natural language reasoning, such as numerical reasoning, logical reasoning, and multi-hop reasoning. Taking the DROP benchmark as a representative example, POET improves the F1 metric of BART from 69.2% to 80.6%. Furthermore, POET shines in giant language models, pushing the F1 metric of T5-11B to 87.6% and achieving a new state-of-the-art performance on DROP. POET opens a new gate on reasoning-enhancement pre-training and we hope our analysis would shed light on the future research of reasoning like program executors.
Example-Based Named Entity Recognition
Aug 24, 2020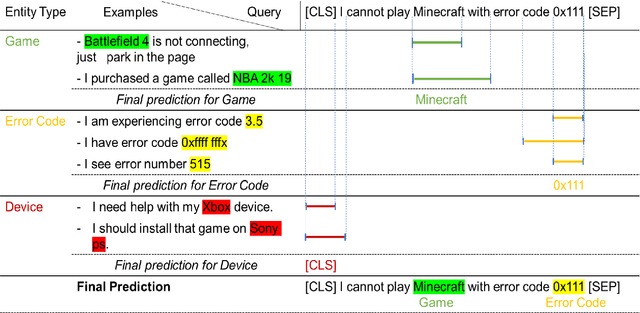
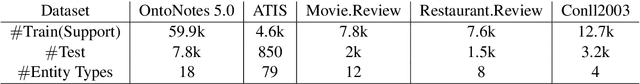
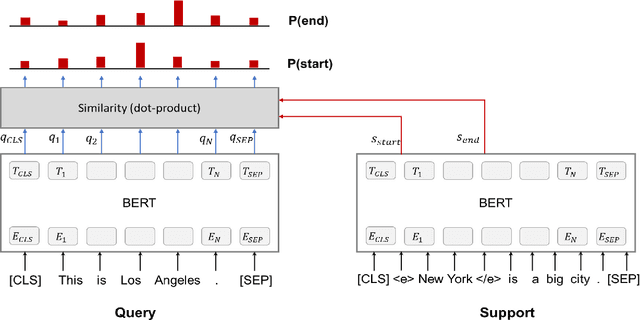
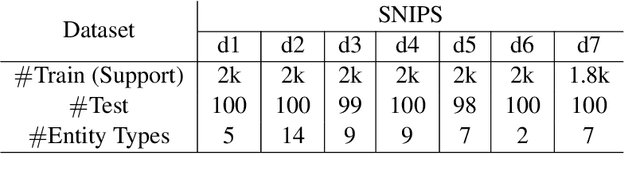
We present a novel approach to named entity recognition (NER) in the presence of scarce data that we call example-based NER. Our train-free few-shot learning approach takes inspiration from question-answering to identify entity spans in a new and unseen domain. In comparison with the current state-of-the-art, the proposed method performs significantly better, especially when using a low number of support examples.
MT-BioNER: Multi-task Learning for Biomedical Named Entity Recognition using Deep Bidirectional Transformers
Jan 24, 2020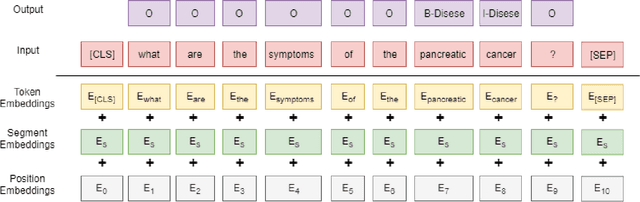


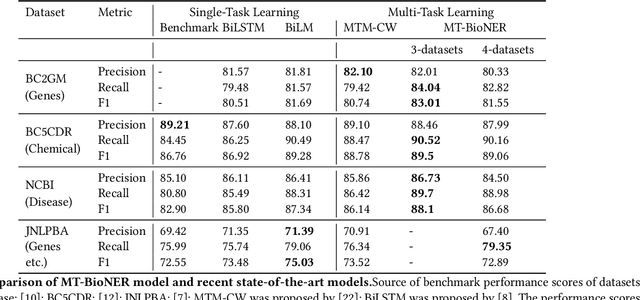
Conversational agents such as Cortana, Alexa and Siri are continuously working on increasing their capabilities by adding new domains. The support of a new domain includes the design and development of a number of NLU components for domain classification, intents classification and slots tagging (including named entity recognition). Each component only performs well when trained on a large amount of labeled data. Second, these components are deployed on limited-memory devices which requires some model compression. Third, for some domains such as the health domain, it is hard to find a single training data set that covers all the required slot types. To overcome these mentioned problems, we present a multi-task transformer-based neural architecture for slot tagging. We consider the training of a slot tagger using multiple data sets covering different slot types as a multi-task learning problem. The experimental results on the biomedical domain have shown that the proposed approach outperforms the previous state-of-the-art systems for slot tagging on the different benchmark biomedical datasets in terms of (time and memory) efficiency and effectiveness. The output slot tagger can be used by the conversational agent to better identify entities in the input utterances.