 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
May 04, 2026Human-level agentic intelligence extends beyond low-level geometric perception, evolving from recognizing where things are to understanding what they are for. While existing benchmarks effectively evaluate the geometric perception capabilities of multimodal large language models (MLLMs), they fall short of probing the higher-order cognitive abilities required for grounded intelligence. To address this gap, we introduce the Spatial-Functional Intelligence Benchmark (SFI-Bench), a video-based benchmark with over 1,500 expert-annotated questions derived from diverse egocentric indoor video scans. SFI-Bench systematically evaluates two complementary dimensions of advanced reasoning: (1) Structured Spatial Reasoning, which requires understanding complex layouts and forming coherent spatial representations, and (2) Functional Reasoning, which involves inferring object affordances and their context-dependent utility. The benchmark includes tasks such as conditional counting, multi-hop relational reasoning, functional pairing, and knowledge-grounded troubleshooting, directly challenging models to integrate perception, memory, and inference. Our experiments reveal that current MLLMs consistently struggle to combine spatial memory with functional reasoning and external knowledge, highlighting a critical bottleneck in achieving grounded intelligence. SFI-Bench therefore provides a diagnostic tool for measuring progress toward more cognitively capable and truly grounded multimodal agents.
Partial Federated Learning
Mar 03, 2024
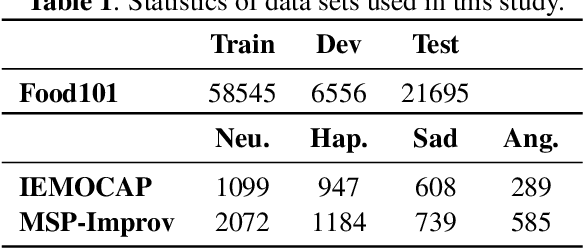
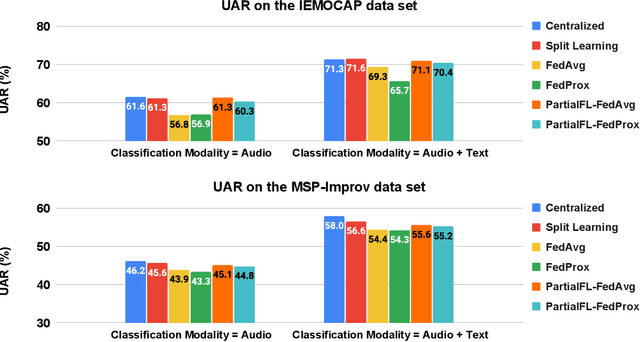
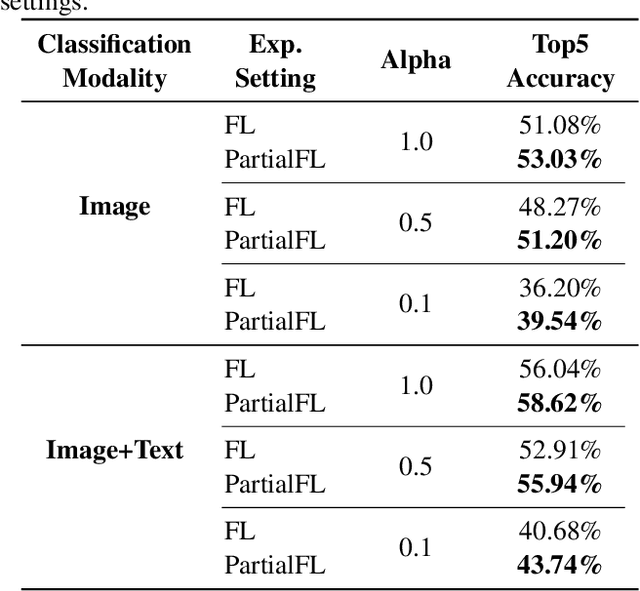
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
Coordinated Replay Sample Selection for Continual Federated Learning
Oct 23, 2023



Continual Federated Learning (CFL) combines Federated Learning (FL), the decentralized learning of a central model on a number of client devices that may not communicate their data, and Continual Learning (CL), the learning of a model from a continual stream of data without keeping the entire history. In CL, the main challenge is \textit{forgetting} what was learned from past data. While replay-based algorithms that keep a small pool of past training data are effective to reduce forgetting, only simple replay sample selection strategies have been applied to CFL in prior work, and no previous work has explored coordination among clients for better sample selection. To bridge this gap, we adapt a replay sample selection objective based on loss gradient diversity to CFL and propose a new relaxation-based selection of samples to optimize the objective. Next, we propose a practical algorithm to coordinate gradient-based replay sample selection across clients without communicating private data. We benchmark our coordinated and uncoordinated replay sample selection algorithms against random sampling-based baselines with language models trained on a large scale de-identified real-world text dataset. We show that gradient-based sample selection methods both boost performance and reduce forgetting compared to random sampling methods, with our coordination method showing gains early in the low replay size regime (when the budget for storing past data is small).
Controlling the Extraction of Memorized Data from Large Language Models via Prompt-Tuning
May 19, 2023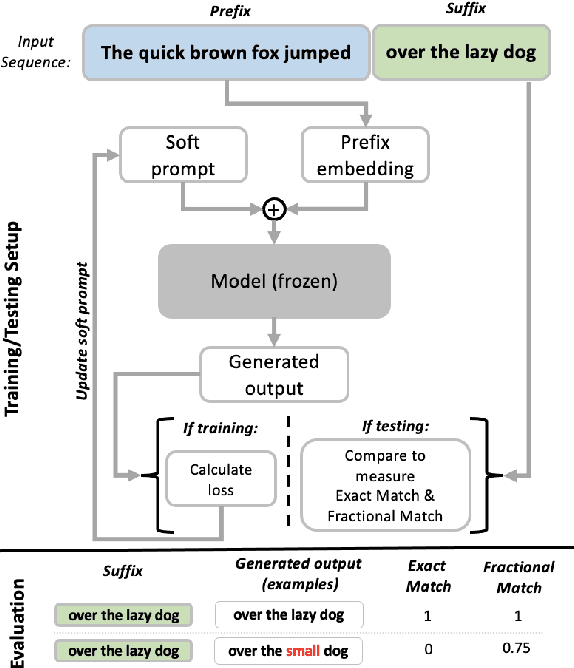
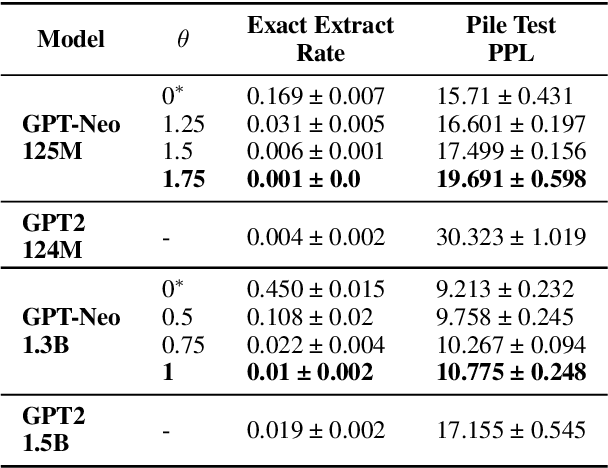
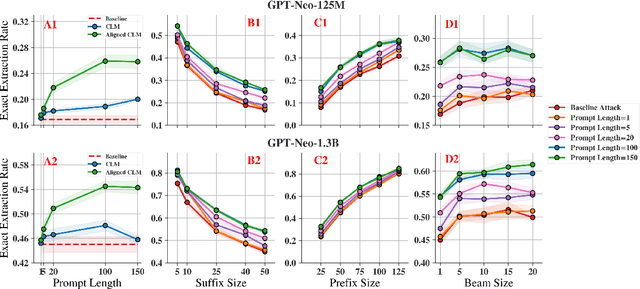
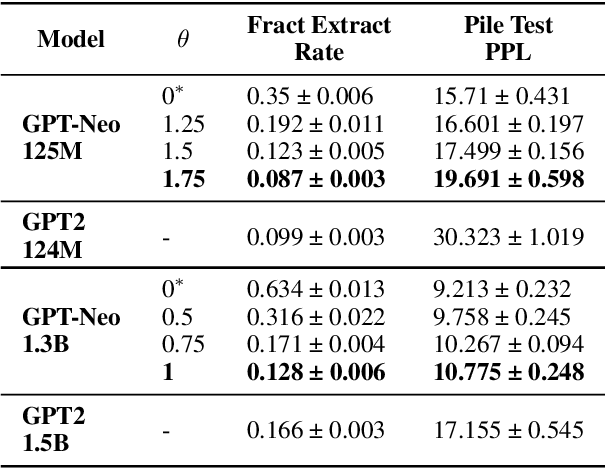
Large Language Models (LLMs) are known to memorize significant portions of their training data. Parts of this memorized content have been shown to be extractable by simply querying the model, which poses a privacy risk. We present a novel approach which uses prompt-tuning to control the extraction rates of memorized content in LLMs. We present two prompt training strategies to increase and decrease extraction rates, which correspond to an attack and a defense, respectively. We demonstrate the effectiveness of our techniques by using models from the GPT-Neo family on a public benchmark. For the 1.3B parameter GPT-Neo model, our attack yields a 9.3 percentage point increase in extraction rate compared to our baseline. Our defense can be tuned to achieve different privacy-utility trade-offs by a user-specified hyperparameter. We achieve an extraction rate reduction of up to 97.7% relative to our baseline, with a perplexity increase of 16.9%.
Differentially Private Decoding in Large Language Models
May 26, 2022
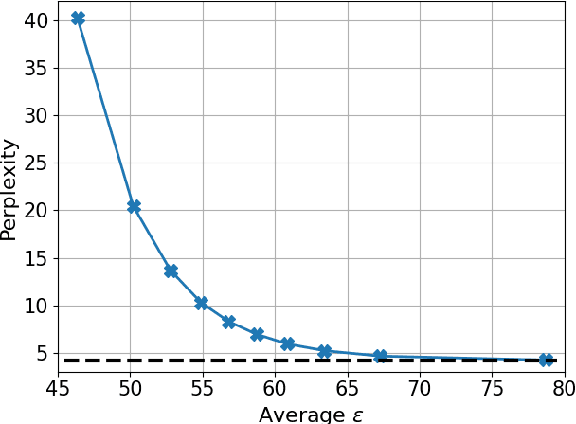
Recent large-scale natural language processing (NLP) systems use a pre-trained Large Language Model (LLM) on massive and diverse corpora as a headstart. In practice, the pre-trained model is adapted to a wide array of tasks via fine-tuning on task-specific datasets. LLMs, while effective, have been shown to memorize instances of training data thereby potentially revealing private information processed during pre-training. The potential leakage might further propagate to the downstream tasks for which LLMs are fine-tuned. On the other hand, privacy-preserving algorithms usually involve retraining from scratch, which is prohibitively expensive for LLMs. In this work, we propose a simple, easy to interpret, and computationally lightweight perturbation mechanism to be applied to an already trained model at the decoding stage. Our perturbation mechanism is model-agnostic and can be used in conjunction with any LLM. We provide theoretical analysis showing that the proposed mechanism is differentially private, and experimental results showing a privacy-utility trade-off.
Federated Learning with Noisy User Feedback
May 06, 2022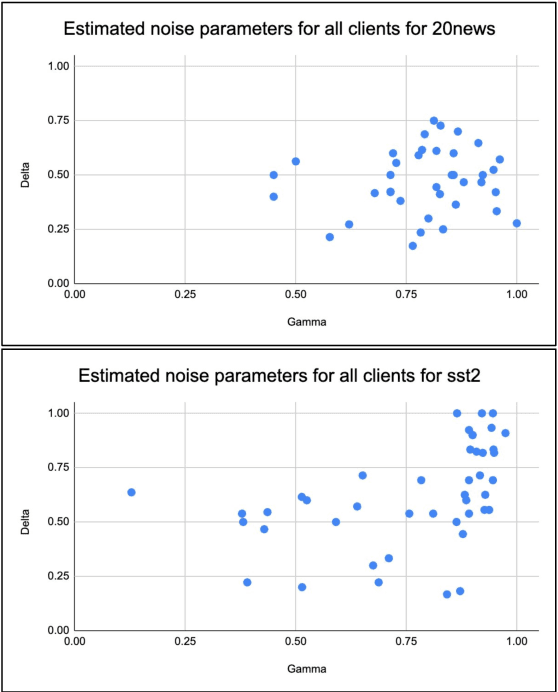



Machine Learning (ML) systems are getting increasingly popular, and drive more and more applications and services in our daily life. This has led to growing concerns over user privacy, since human interaction data typically needs to be transmitted to the cloud in order to train and improve such systems. Federated learning (FL) has recently emerged as a method for training ML models on edge devices using sensitive user data and is seen as a way to mitigate concerns over data privacy. However, since ML models are most commonly trained with label supervision, we need a way to extract labels on edge to make FL viable. In this work, we propose a strategy for training FL models using positive and negative user feedback. We also design a novel framework to study different noise patterns in user feedback, and explore how well standard noise-robust objectives can help mitigate this noise when training models in a federated setting. We evaluate our proposed training setup through detailed experiments on two text classification datasets and analyze the effects of varying levels of user reliability and feedback noise on model performance. We show that our method improves substantially over a self-training baseline, achieving performance closer to models trained with full supervision.
Robust Correlation Clustering with Asymmetric Noise
Oct 15, 2021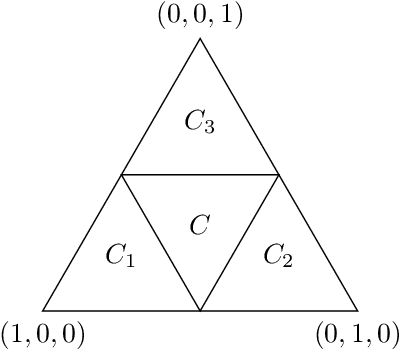

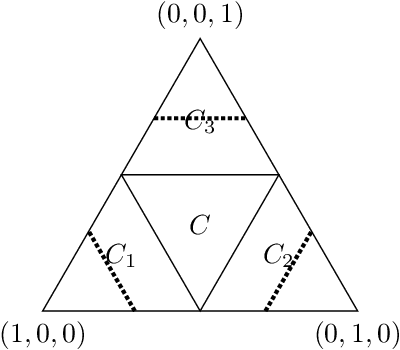
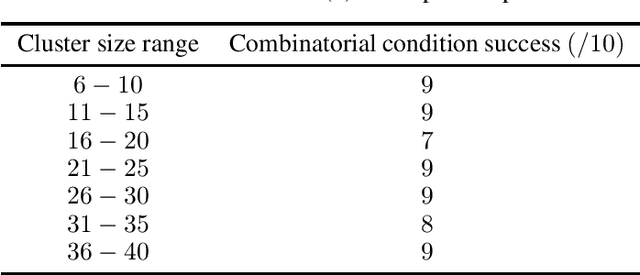
Graph clustering problems typically aim to partition the graph nodes such that two nodes belong to the same partition set if and only if they are similar. Correlation Clustering is a graph clustering formulation which: (1) takes as input a signed graph with edge weights representing a similarity/dissimilarity measure between the nodes, and (2) requires no prior estimate of the number of clusters in the input graph. However, the combinatorial optimization problem underlying Correlation Clustering is NP-hard. In this work, we propose a novel graph generative model, called the Node Factors Model (NFM), which is based on generating feature vectors/embeddings for the graph nodes. The graphs generated by the NFM contain asymmetric noise in the sense that there may exist pairs of nodes in the same cluster which are negatively correlated. We propose a novel Correlation Clustering algorithm, called \anormd, using techniques from semidefinite programming. Using a combination of theoretical and computational results, we demonstrate that $\texttt{$\ell_2$-norm-diag}$ recovers nodes with sufficiently strong cluster membership in graph instances generated by the NFM, thereby making progress towards establishing the provable robustness of our proposed algorithm.
Provable Overlapping Community Detection in Weighted Graphs
Apr 19, 2020


Community detection is a widely-studied unsupervised learning problem in which the task is to group similar entities together based on observed pairwise entity interactions. This problem has applications in diverse domains such as social network analysis and computational biology. There is a significant amount of literature studying this problem under the assumption that the communities do not overlap. When the communities are allowed to overlap, often a pure nodes assumption is made, i.e. each community has a node that belongs exclusively to that community. This assumption, however, may not always be satisfied in practice. In this paper, we provide a provable method to detect overlapping communities in weighted graphs without explicitly making the pure nodes assumption. Moreover, contrary to most existing algorithms, our approach is based on convex optimization, for which many useful theoretical properties are already known. We demonstrate the success of our algorithm on artificial and real-world datasets.