 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling the Extraction of Memorized Data from Large Language Models via Prompt-Tuning
May 19, 2023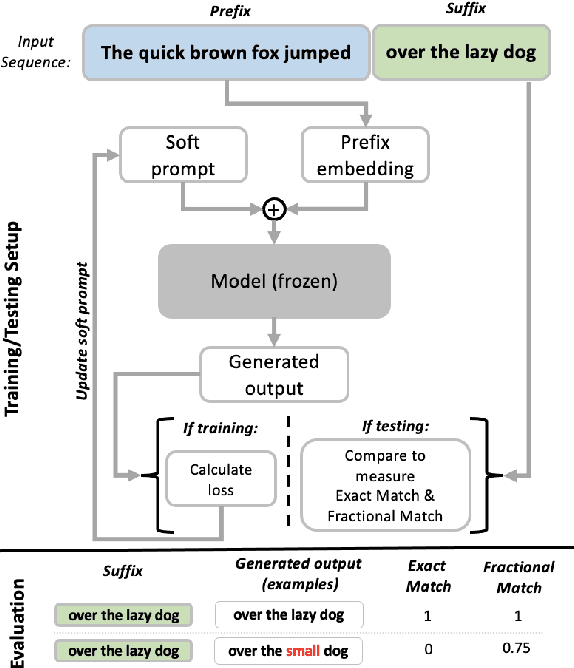
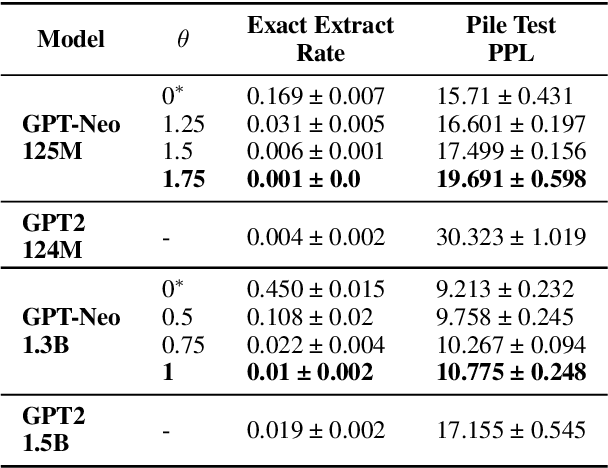
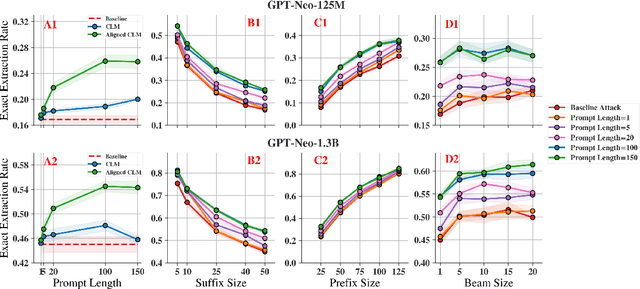
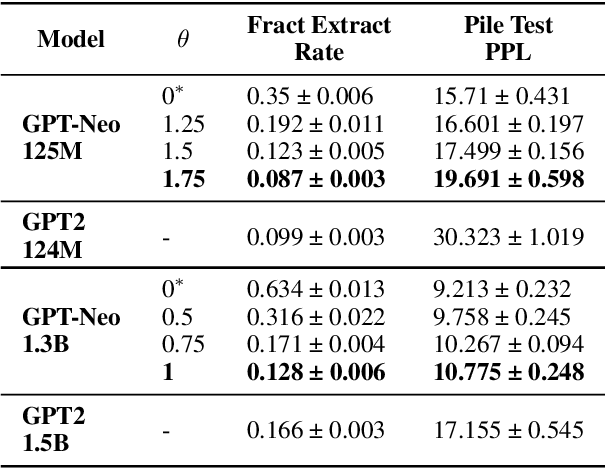
Large Language Models (LLMs) are known to memorize significant portions of their training data. Parts of this memorized content have been shown to be extractable by simply querying the model, which poses a privacy risk. We present a novel approach which uses prompt-tuning to control the extraction rates of memorized content in LLMs. We present two prompt training strategies to increase and decrease extraction rates, which correspond to an attack and a defense, respectively. We demonstrate the effectiveness of our techniques by using models from the GPT-Neo family on a public benchmark. For the 1.3B parameter GPT-Neo model, our attack yields a 9.3 percentage point increase in extraction rate compared to our baseline. Our defense can be tuned to achieve different privacy-utility trade-offs by a user-specified hyperparameter. We achieve an extraction rate reduction of up to 97.7% relative to our baseline, with a perplexity increase of 16.9%.
The Impact of Data Distribution on Fairness and Robustness in Federated Learning
Nov 29, 2021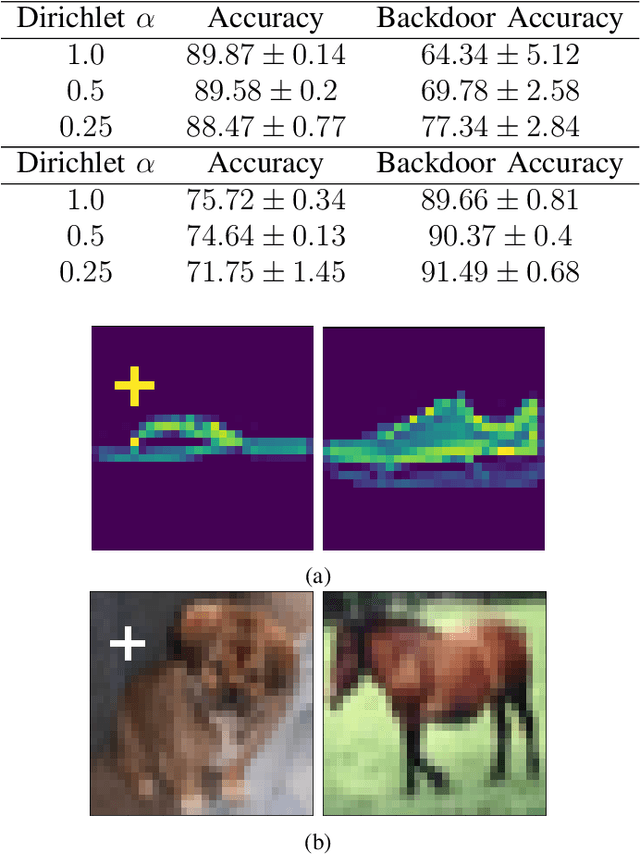

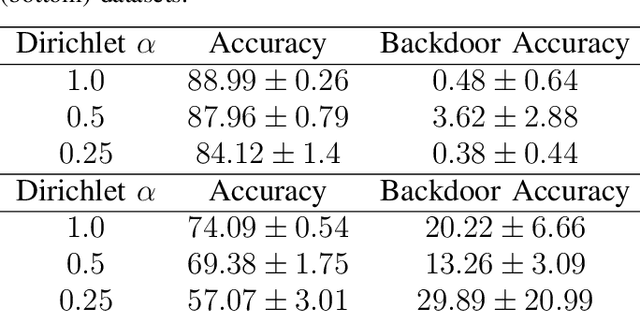
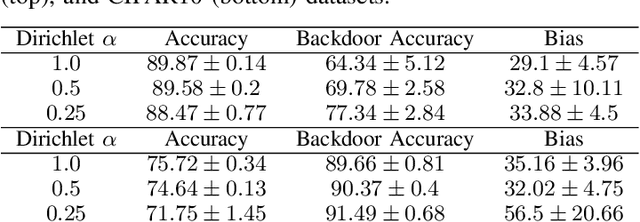
Federated Learning (FL) is a distributed machine learning protocol that allows a set of agents to collaboratively train a model without sharing their datasets. This makes FL particularly suitable for settings where data privacy is desired. However, it has been observed that the performance of FL is closely related to the similarity of the local data distributions of agents. Particularly, as the data distributions of agents differ, the accuracy of the trained models drop. In this work, we look at how variations in local data distributions affect the fairness and the robustness properties of the trained models in addition to the accuracy. Our experimental results indicate that, the trained models exhibit higher bias, and become more susceptible to attacks as local data distributions differ. Importantly, the degradation in the fairness, and robustness can be much more severe than the accuracy. Therefore, we reveal that small variations that have little impact on the accuracy could still be important if the trained model is to be deployed in a fairness/security critical context.
BiFair: Training Fair Models with Bilevel Optimization
Jun 03, 2021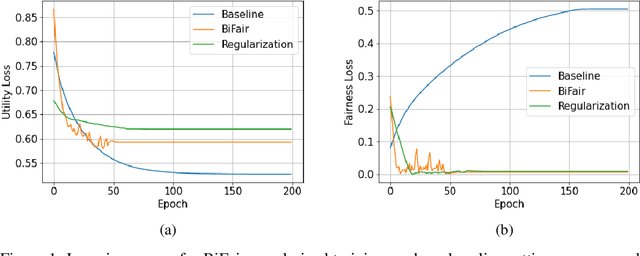
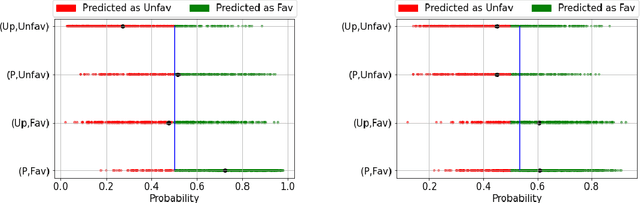

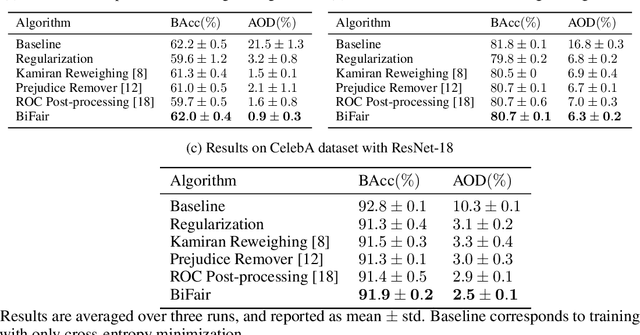
Prior studies have shown that, training machine learning models via empirical loss minimization to maximize a utility metric (e.g., accuracy), might yield models that make discriminatory predictions. To alleviate this issue, we develop a new training algorithm, named BiFair, which jointly minimizes for a utility, and a fairness loss of interest. Crucially, we do so without directly modifying the training objective, e.g., by adding regularization terms. Rather, we learn a set of weights on the training dataset, such that, training on the weighted dataset ensures both good utility, and fairness. The dataset weights are learned in concurrence to the model training, which is done by solving a bilevel optimization problem using a held-out validation dataset. Overall, this approach yields models with better fairness-utility trade-offs. Particularly, we compare our algorithm with three other state-of-the-art fair training algorithms over three real-world datasets, and demonstrate that, BiFair consistently performs better, i.e., we reach to better values of a given fairness metric under same, or higher accuracy. Further, our algorithm is scalable. It is applicable both to simple models, such as logistic regression, as well as more complex models, such as deep neural networks, as evidenced by our experimental analysis.
BlockFLA: Accountable Federated Learning via Hybrid Blockchain Architecture
Oct 14, 2020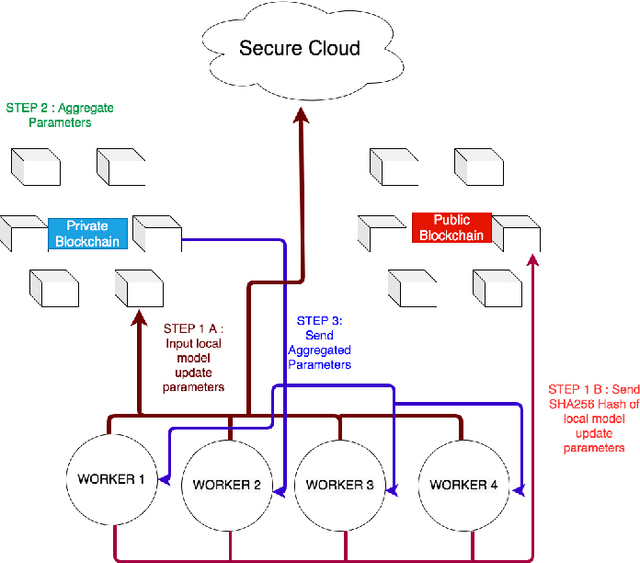
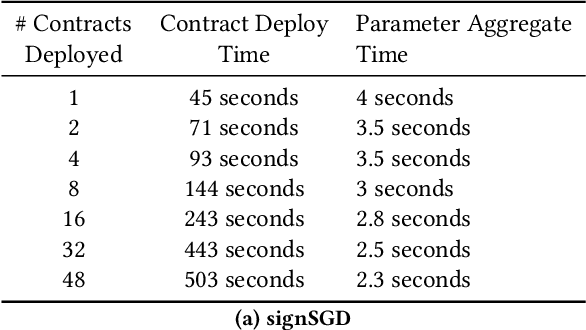
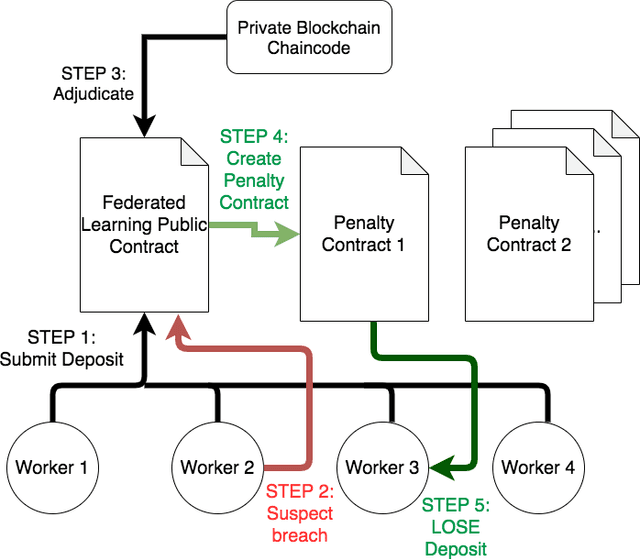
Federated Learning (FL) is a distributed, and decentralized machine learning protocol. By executing FL, a set of agents can jointly train a model without sharing their datasets with each other, or a third-party. This makes FL particularly suitable for settings where data privacy is desired. At the same time, concealing training data gives attackers an opportunity to inject backdoors into the trained model. It has been shown that an attacker can inject backdoors to the trained model during FL, and then can leverage the backdoor to make the model misclassify later. Several works tried to alleviate this threat by designing robust aggregation functions. However, given more sophisticated attacks are developed over time, which by-pass the existing defenses, we approach this problem from a complementary angle in this work. Particularly, we aim to discourage backdoor attacks by detecting, and punishing the attackers, possibly after the end of training phase. To this end, we develop a hybrid blockchain-based FL framework that uses smart contracts to automatically detect, and punish the attackers via monetary penalties. Our framework is general in the sense that, any aggregation function, and any attacker detection algorithm can be plugged into it. We conduct experiments to demonstrate that our framework preserves the communication-efficient nature of FL, and provide empirical results to illustrate that it can successfully penalize attackers by leveraging our novel attacker detection algorithm.
Improving Accuracy of Federated Learning in Non-IID Settings
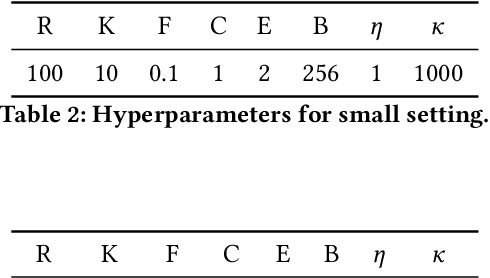
Oct 14, 2020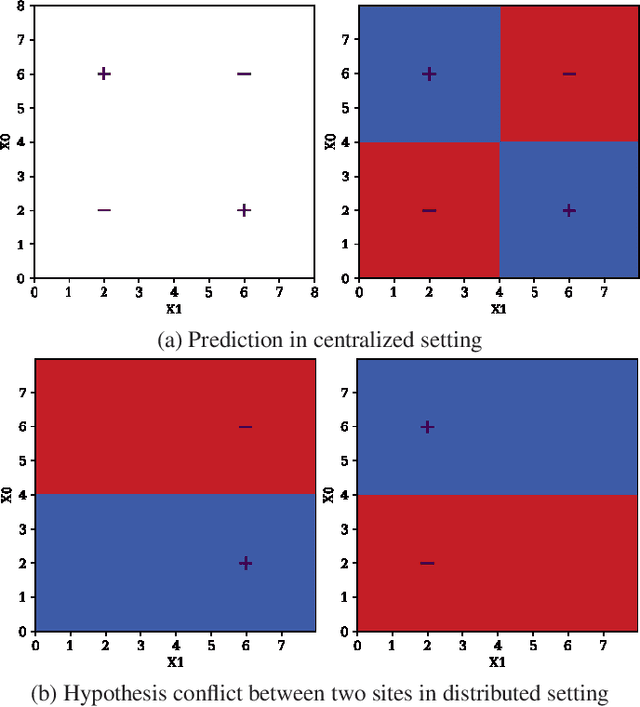
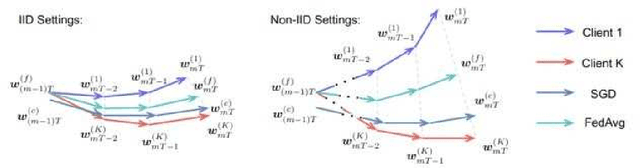
Federated Learning (FL) is a decentralized machine learning protocol that allows a set of participating agents to collaboratively train a model without sharing their data. This makes FL particularly suitable for settings where data privacy is desired. However, it has been observed that the performance of FL is closely tied with the local data distributions of agents. Particularly, in settings where local data distributions vastly differ among agents, FL performs rather poorly with respect to the centralized training. To address this problem, we hypothesize the reasons behind the performance degradation, and develop some techniques to address these reasons accordingly. In this work, we identify four simple techniques that can improve the performance of trained models without incurring any additional communication overhead to FL, but rather, some light computation overhead either on the client, or the server-side. In our experimental analysis, combination of our techniques improved the validation accuracy of a model trained via FL by more than 12% with respect to our baseline. This is about 5% less than the accuracy of the model trained on centralized data.
Defending Against Backdoors in Federated Learning with Robust Learning Rate
Jul 07, 2020
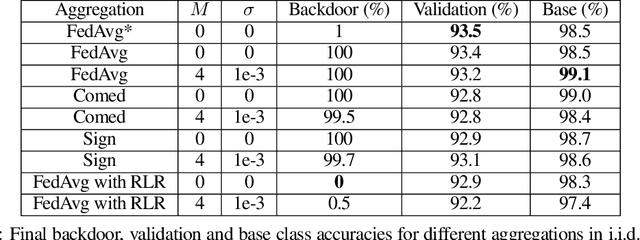
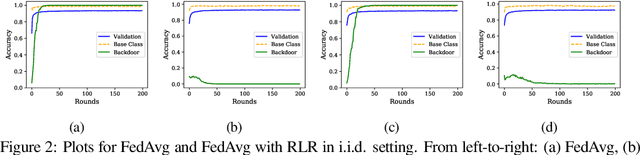
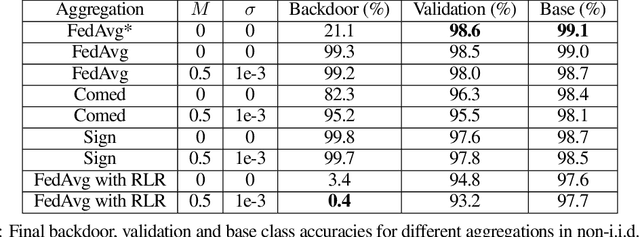
Federated Learning (FL) allows a set of agents to collaboratively train a model in a decentralized fashion without sharing their potentially sensitive data. This makes FL suitable for privacy-preserving applications. At the same time, FL is susceptible to adversarial attacks due to decentralized and unvetted data. One important line of attacks against FL is the backdoor attacks. In a backdoor attack, an adversary tries to embed a backdoor trigger functionality to the model during training which can later be activated to cause a desired misclassification. To prevent such backdoor attacks, we propose a lightweight defense that requires no change to the FL structure. At a high level, our defense is based on carefully adjusting the server's learning rate, per dimension, at each round based on the sign information of agent's updates. We first conjecture the necessary steps to carry a successful backdoor attack in FL setting, and then, explicitly formulate the defense based on our conjecture. Through experiments, we provide empirical evidence to the support of our conjecture. We test our defense against backdoor attacks under different settings, and, observe that either backdoor is completely eliminated, or its accuracy is significantly reduced. Overall, our experiments suggests that our approach significantly outperforms some of the recently proposed defenses in the literature. We achieve this by having minimal influence over the accuracy of the trained models.