 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Accuracy of Federated Learning in Non-IID Settings
Paper and Code
Oct 14, 2020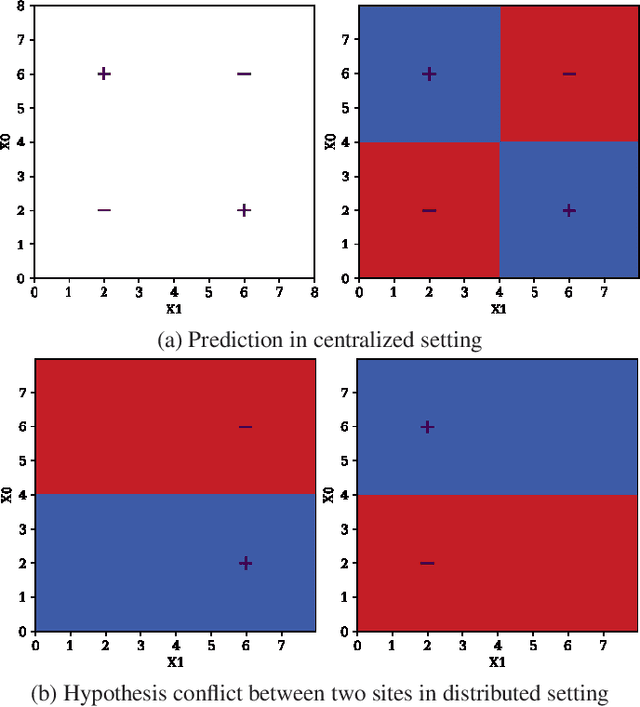
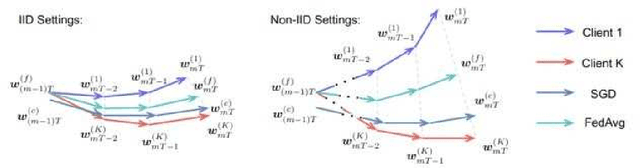
Federated Learning (FL) is a decentralized machine learning protocol that allows a set of participating agents to collaboratively train a model without sharing their data. This makes FL particularly suitable for settings where data privacy is desired. However, it has been observed that the performance of FL is closely tied with the local data distributions of agents. Particularly, in settings where local data distributions vastly differ among agents, FL performs rather poorly with respect to the centralized training. To address this problem, we hypothesize the reasons behind the performance degradation, and develop some techniques to address these reasons accordingly. In this work, we identify four simple techniques that can improve the performance of trained models without incurring any additional communication overhead to FL, but rather, some light computation overhead either on the client, or the server-side. In our experimental analysis, combination of our techniques improved the validation accuracy of a model trained via FL by more than 12% with respect to our baseline. This is about 5% less than the accuracy of the model trained on centralized data.