 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeRunner 20B: Military Task Parity with GPT-5 while Running on the Edge
Oct 30, 2025We present EdgeRunner 20B, a fine-tuned version of gpt-oss-20b optimized for military tasks. EdgeRunner 20B was trained on 1.6M high-quality records curated from military documentation and websites. We also present four new tests sets: (a) combat arms, (b) combat medic, (c) cyber operations, and (d) mil-bench-5k (general military knowledge). On these military test sets, EdgeRunner 20B matches or exceeds GPT-5 task performance with 95%+ statistical significance, except for the high reasoning setting on the combat medic test set and the low reasoning setting on the mil-bench-5k test set. Versus gpt-oss-20b, there is no statistically-significant regression on general-purpose benchmarks like ARC-C, GPQA Diamond, GSM8k, IFEval, MMLU Pro, or TruthfulQA, except for GSM8k in the low reasoning setting. We also present analyses on hyperparameter settings, cost, and throughput. These findings show that small, locally-hosted models are ideal solutions for data-sensitive operations such as in the military domain, allowing for deployment in air-gapped edge devices.
Wanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
MATTER: Memory-Augmented Transformer Using Heterogeneous Knowledge Sources
Jun 07, 2024



Leveraging external knowledge is crucial for achieving high performance in knowledge-intensive tasks, such as question answering. The retrieve-and-read approach is widely adopted for integrating external knowledge into a language model. However, this approach suffers from increased computational cost and latency due to the long context length, which grows proportionally with the number of retrieved knowledge. Furthermore, existing retrieval-augmented models typically retrieve information from a single type of knowledge source, limiting their scalability to diverse knowledge sources with varying structures. In this work, we introduce an efficient memory-augmented transformer called MATTER, designed to retrieve relevant knowledge from multiple heterogeneous knowledge sources. Specifically, our model retrieves and reads from both unstructured sources (paragraphs) and semi-structured sources (QA pairs) in the form of fixed-length neural memories. We demonstrate that our model outperforms existing efficient retrieval-augmented models on popular QA benchmarks in terms of both accuracy and speed. Furthermore, MATTER achieves competitive results compared to conventional read-and-retrieve models while having 100x throughput during inference.
Controlling the Extraction of Memorized Data from Large Language Models via Prompt-Tuning
May 19, 2023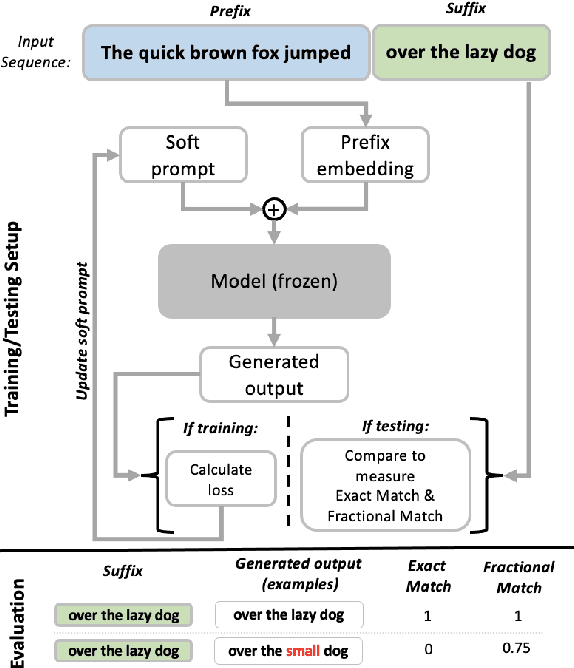
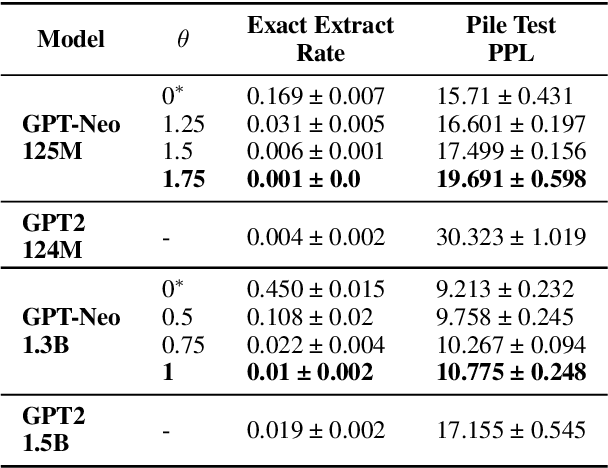
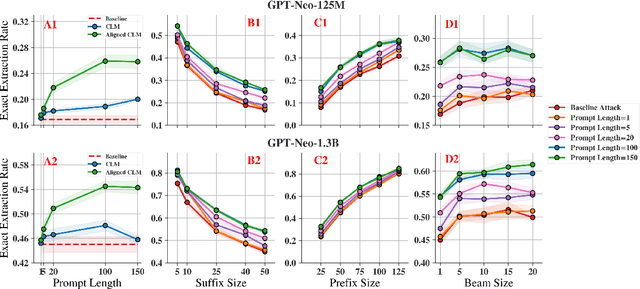
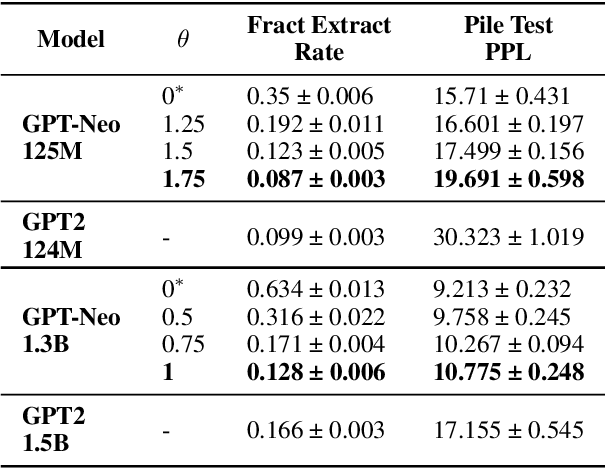
Large Language Models (LLMs) are known to memorize significant portions of their training data. Parts of this memorized content have been shown to be extractable by simply querying the model, which poses a privacy risk. We present a novel approach which uses prompt-tuning to control the extraction rates of memorized content in LLMs. We present two prompt training strategies to increase and decrease extraction rates, which correspond to an attack and a defense, respectively. We demonstrate the effectiveness of our techniques by using models from the GPT-Neo family on a public benchmark. For the 1.3B parameter GPT-Neo model, our attack yields a 9.3 percentage point increase in extraction rate compared to our baseline. Our defense can be tuned to achieve different privacy-utility trade-offs by a user-specified hyperparameter. We achieve an extraction rate reduction of up to 97.7% relative to our baseline, with a perplexity increase of 16.9%.
The Massively Multilingual Natural Language Understanding 2022 (MMNLU-22) Workshop and Competition
Dec 13, 2022Despite recent progress in Natural Language Understanding (NLU), the creation of multilingual NLU systems remains a challenge. It is common to have NLU systems limited to a subset of languages due to lack of available data. They also often vary widely in performance. We launch a three-phase approach to address the limitations in NLU and help propel NLU technology to new heights. We release a 52 language dataset called the Multilingual Amazon SLU resource package (SLURP) for Slot-filling, Intent classification, and Virtual assistant Evaluation, or MASSIVE, in an effort to address parallel data availability for voice assistants. We organize the Massively Multilingual NLU 2022 Challenge to provide a competitive environment and push the state-of-the art in the transferability of models into other languages. Finally, we host the first Massively Multilingual NLU workshop which brings these components together. The MMNLU workshop seeks to advance the science behind multilingual NLU by providing a platform for the presentation of new research in the field and connecting teams working on this research direction. This paper summarizes the dataset, workshop and the competition and the findings of each phase.
* 5 pages
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


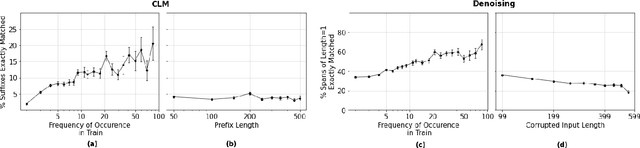
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022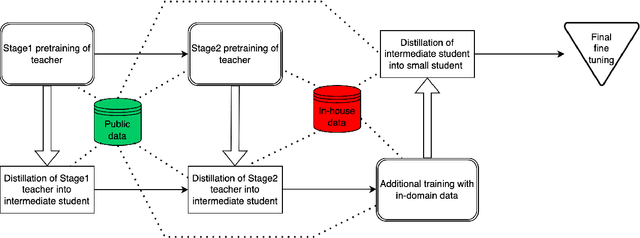
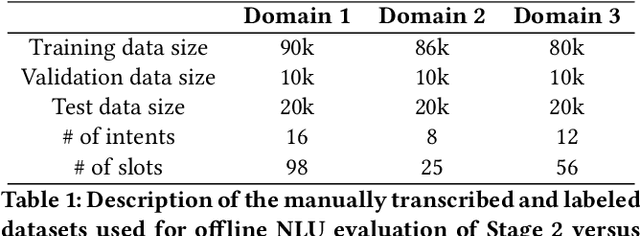
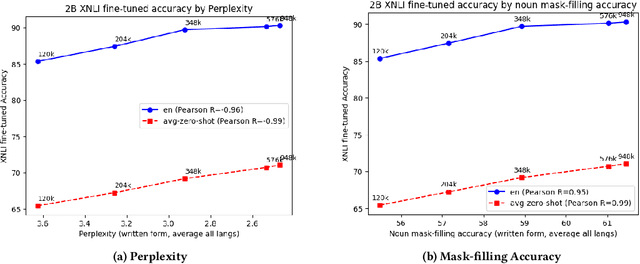
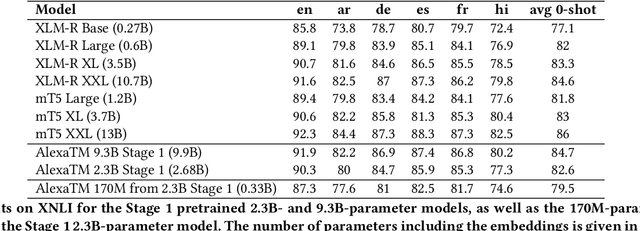
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
MASSIVE: A 1M-Example Multilingual Natural Language Understanding Dataset with 51 Typologically-Diverse Languages
Apr 18, 2022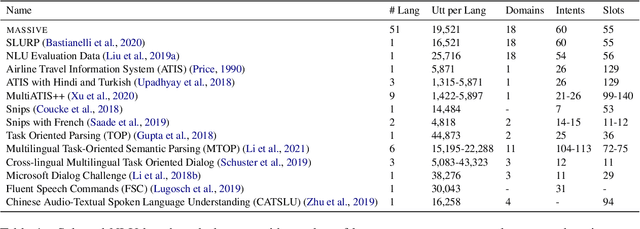
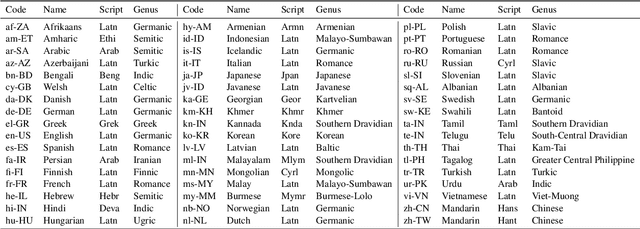
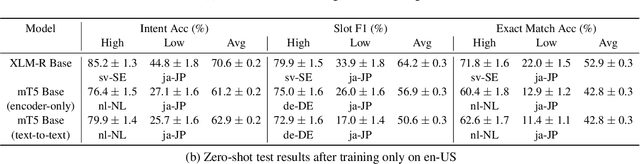

We present the MASSIVE dataset--Multilingual Amazon Slu resource package (SLURP) for Slot-filling, Intent classification, and Virtual assistant Evaluation. MASSIVE contains 1M realistic, parallel, labeled virtual assistant utterances spanning 51 languages, 18 domains, 60 intents, and 55 slots. MASSIVE was created by tasking professional translators to localize the English-only SLURP dataset into 50 typologically diverse languages from 29 genera. We also present modeling results on XLM-R and mT5, including exact match accuracy, intent classification accuracy, and slot-filling F1 score. We have released our dataset, modeling code, and models publicly.