 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Considerations For Hypothesis Rejection Modules In Spoken Language Understanding Systems
Oct 31, 2022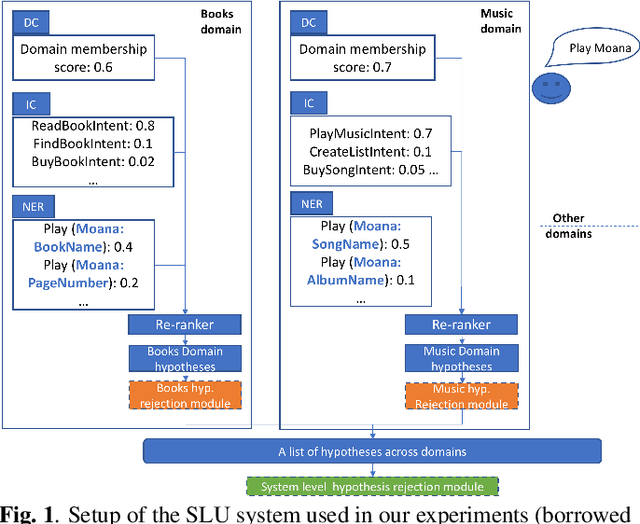



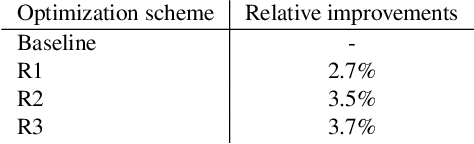
Spoken Language Understanding (SLU) systems typically consist of a set of machine learning models that operate in conjunction to produce an SLU hypothesis. The generated hypothesis is then sent to downstream components for further action. However, it is desirable to discard an incorrect hypothesis before sending it downstream. In this work, we present two designs for SLU hypothesis rejection modules: (i) scheme R1 that performs rejection on domain specific SLU hypothesis and, (ii) scheme R2 that performs rejection on hypothesis generated from the overall SLU system. Hypothesis rejection modules in both schemes reject/accept a hypothesis based on features drawn from the utterance directed to the SLU system, the associated SLU hypothesis and SLU confidence score. Our experiments suggest that both the schemes yield similar results (scheme R1: 2.5% FRR @ 4.5% FAR, scheme R2: 2.5% FRR @ 4.6% FAR), with the best performing systems using all the available features. We argue that while either of the rejection schemes can be chosen over the other, they carry some inherent differences which need to be considered while making this choice. Additionally, we incorporate ASR features in the rejection module (obtaining an 1.9% FRR @ 3.8% FAR) and analyze the improvements.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


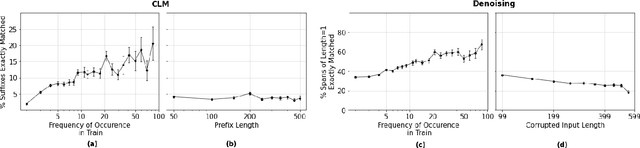
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022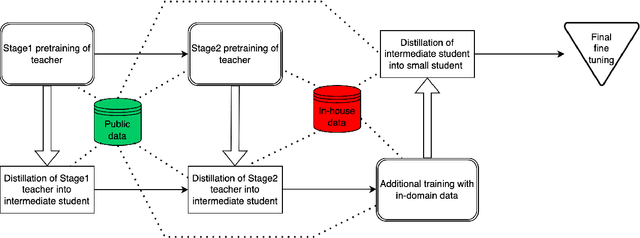
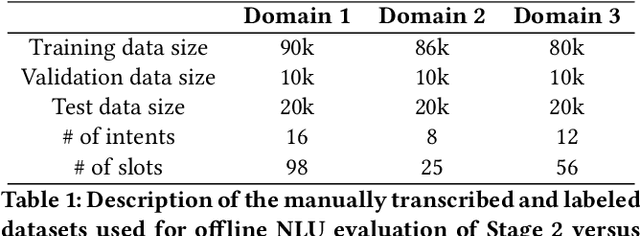
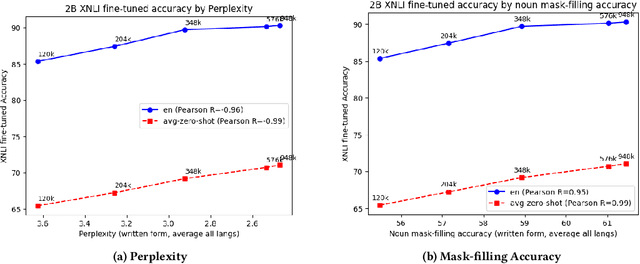
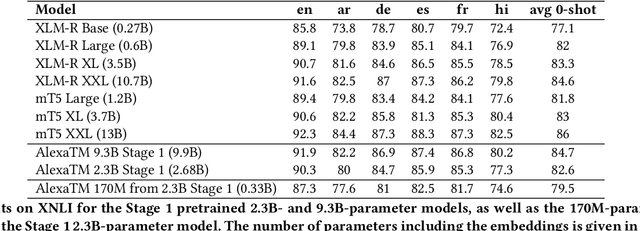
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
One-vs-All Models for Asynchronous Training: An Empirical Analysis
Jun 20, 2019

Any given classification problem can be modeled using multi-class or One-vs-All (OVA) architecture. An OVA system consists of as many OVA models as the number of classes, providing the advantage of asynchrony, where each OVA model can be re-trained independent of other models. This is particularly advantageous in settings where scalable model training is a consideration (for instance in an industrial environment where multiple and frequent updates need to be made to the classification system). In this paper, we conduct empirical analysis on realizing independent updates to OVA models and its impact on the accuracy of the overall OVA system. Given that asynchronous updates lead to differences in training datasets for OVA models, we first define a metric to quantify the differences in datasets. Thereafter, using Natural Language Understanding as a task of interest, we estimate the impact of three factors: (i) number of classes, (ii) number of data points and, (iii) divergences in training datasets across OVA models; on the OVA system accuracy. Finally, we observe the accuracy impact of increased asynchrony in a Spoken Language Understanding system. We analyze the results and establish that the proposed metric correlates strongly with the model performances in both the experimental settings.
A Re-ranker Scheme for Integrating Large Scale NLU models
Sep 25, 2018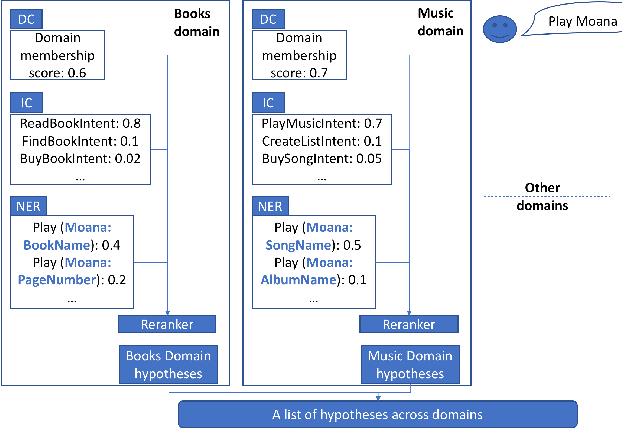


Large scale Natural Language Understanding (NLU) systems are typically trained on large quantities of data, requiring a fast and scalable training strategy. A typical design for NLU systems consists of domain-level NLU modules (domain classifier, intent classifier and named entity recognizer). Hypotheses (NLU interpretations consisting of various intent+slot combinations) from these domain specific modules are typically aggregated with another downstream component. The re-ranker integrates outputs from domain-level recognizers, returning a scored list of cross domain hypotheses. An ideal re-ranker will exhibit the following two properties: (a) it should prefer the most relevant hypothesis for the given input as the top hypothesis and, (b) the interpretation scores corresponding to each hypothesis produced by the re-ranker should be calibrated. Calibration allows the final NLU interpretation score to be comparable across domains. We propose a novel re-ranker strategy that addresses these aspects, while also maintaining domain specific modularity. We design optimization loss functions for such a modularized re-ranker and present results on decreasing the top hypothesis error rate as well as maintaining the model calibration. We also experiment with an extension involving training the domain specific re-rankers on datasets curated independently by each domain to allow further asynchronization. %The proposed re-ranker design showcases the following: (i) improved NLU performance over an unweighted aggregation strategy, (ii) cross-domain calibrated performance and, (iii) support for use cases involving training each re-ranker on datasets curated by each domain independently.
Play Duration based User-Entity Affinity Modeling in Spoken Dialog System
Jun 29, 2018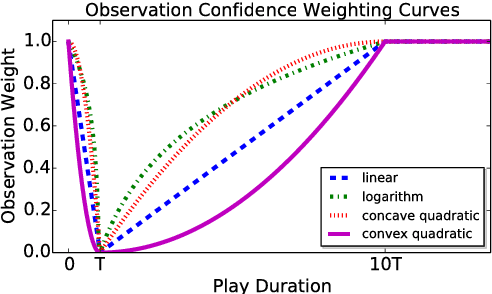

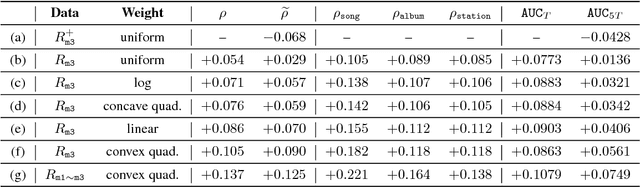
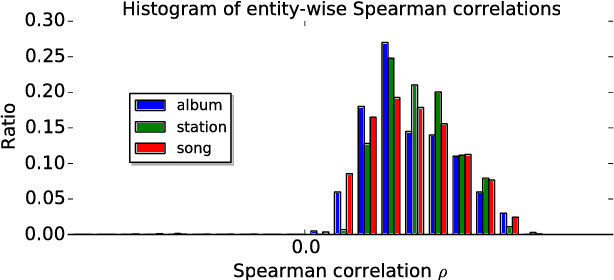
Multimedia streaming services over spoken dialog systems have become ubiquitous. User-entity affinity modeling is critical for the system to understand and disambiguate user intents and personalize user experiences. However, fully voice-based interaction demands quantification of novel behavioral cues to determine user affinities. In this work, we propose using play duration cues to learn a matrix factorization based collaborative filtering model. We first binarize play durations to obtain implicit positive and negative affinity labels. The Bayesian Personalized Ranking objective and learning algorithm are employed in our low-rank matrix factorization approach. To cope with uncertainties in the implicit affinity labels, we propose to apply a weighting function that emphasizes the importance of high confidence samples. Based on a large-scale database of Alexa music service records, we evaluate the affinity models by computing Spearman correlation between play durations and predicted affinities. Comparing different data utilizations and weighting functions, we find that employing both positive and negative affinity samples with a convex weighting function yields the best performance. Further analysis demonstrates the model's effectiveness on individual entity level and provides insights on the temporal dynamics of observed affinities.