 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Pruning Adapters
Nov 21, 2022We propose Structured Pruning Adapters (SPAs), a family of compressing, task-switching network adapters, that accelerate and specialize networks using tiny parameter sets. Specifically, we propose a channel- and a block-based SPA and evaluate them with a suite of pruning methods on both computer vision and natural language processing benchmarks. Compared to regular structured pruning with fine-tuning, our channel-SPA improves accuracy by 6.9% on average while using half the parameters at 90% pruned weights. Alternatively, it can learn adaptations with 17x fewer parameters at 70% pruning with 1.6% lower accuracy. Similarly, our block-SPA requires far fewer parameters than pruning with fine-tuning. Our experimental code and Python library of adapters are available at github.com/lukashedegaard/structured-pruning-adapters.
Design Considerations For Hypothesis Rejection Modules In Spoken Language Understanding Systems
Oct 31, 2022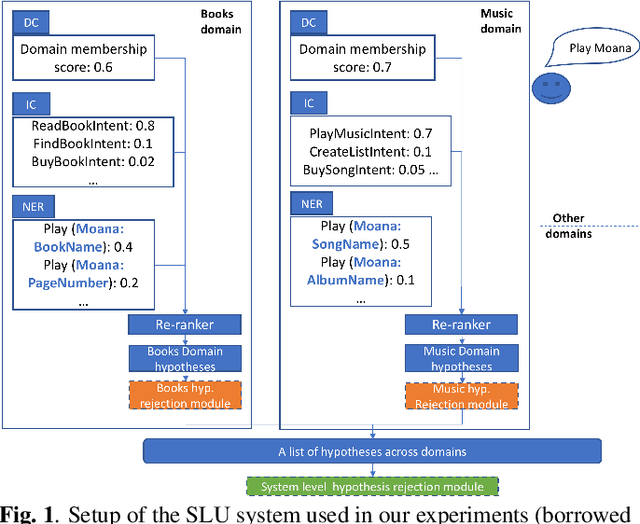



Spoken Language Understanding (SLU) systems typically consist of a set of machine learning models that operate in conjunction to produce an SLU hypothesis. The generated hypothesis is then sent to downstream components for further action. However, it is desirable to discard an incorrect hypothesis before sending it downstream. In this work, we present two designs for SLU hypothesis rejection modules: (i) scheme R1 that performs rejection on domain specific SLU hypothesis and, (ii) scheme R2 that performs rejection on hypothesis generated from the overall SLU system. Hypothesis rejection modules in both schemes reject/accept a hypothesis based on features drawn from the utterance directed to the SLU system, the associated SLU hypothesis and SLU confidence score. Our experiments suggest that both the schemes yield similar results (scheme R1: 2.5% FRR @ 4.5% FAR, scheme R2: 2.5% FRR @ 4.6% FAR), with the best performing systems using all the available features. We argue that while either of the rejection schemes can be chosen over the other, they carry some inherent differences which need to be considered while making this choice. Additionally, we incorporate ASR features in the rejection module (obtaining an 1.9% FRR @ 3.8% FAR) and analyze the improvements.
ProtoDA: Efficient Transfer Learning for Few-Shot Intent Classification
Jan 28, 2021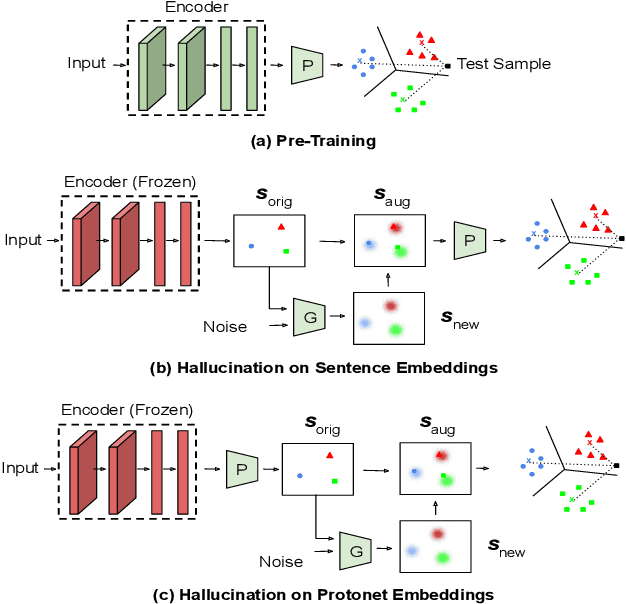


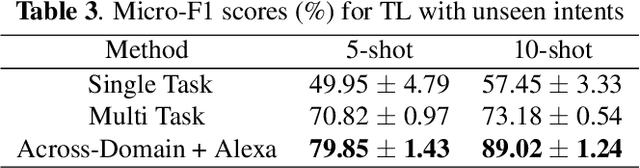
Practical sequence classification tasks in natural language processing often suffer from low training data availability for target classes. Recent works towards mitigating this problem have focused on transfer learning using embeddings pre-trained on often unrelated tasks, for instance, language modeling. We adopt an alternative approach by transfer learning on an ensemble of related tasks using prototypical networks under the meta-learning paradigm. Using intent classification as a case study, we demonstrate that increasing variability in training tasks can significantly improve classification performance. Further, we apply data augmentation in conjunction with meta-learning to reduce sampling bias. We make use of a conditional generator for data augmentation that is trained directly using the meta-learning objective and simultaneously with prototypical networks, hence ensuring that data augmentation is customized to the task. We explore augmentation in the sentence embedding space as well as prototypical embedding space. Combining meta-learning with augmentation provides upto 6.49% and 8.53% relative F1-score improvements over the best performing systems in the 5-shot and 10-shot learning, respectively.
Automatic Discovery of Novel Intents & Domains from Text Utterances
May 22, 2020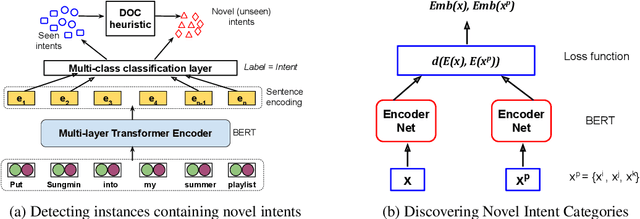

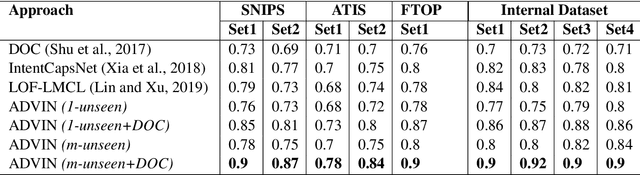
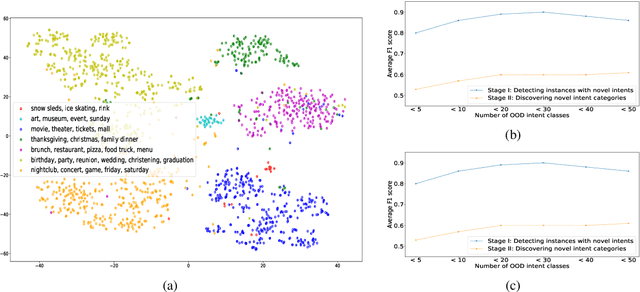
One of the primary tasks in Natural Language Understanding (NLU) is to recognize the intents as well as domains of users' spoken and written language utterances. Most existing research formulates this as a supervised classification problem with a closed-world assumption, i.e. the domains or intents to be identified are pre-defined or known beforehand. Real-world applications however increasingly encounter dynamic, rapidly evolving environments with newly emerging intents and domains, about which no information is known during model training. We propose a novel framework, ADVIN, to automatically discover novel domains and intents from large volumes of unlabeled data. We first employ an open classification model to identify all utterances potentially consisting of a novel intent. Next, we build a knowledge transfer component with a pairwise margin loss function. It learns discriminative deep features to group together utterances and discover multiple latent intent categories within them in an unsupervised manner. We finally hierarchically link mutually related intents into domains, forming an intent-domain taxonomy. ADVIN significantly outperforms baselines on three benchmark datasets, and real user utterances from a commercial voice-powered agent.
Towards classification parity across cohorts
May 16, 2020
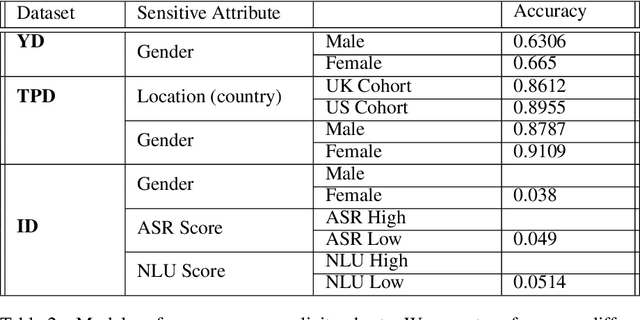
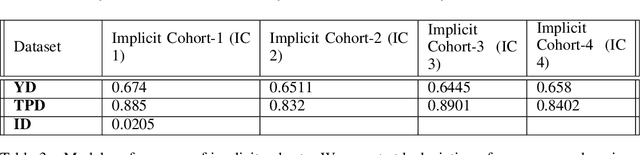
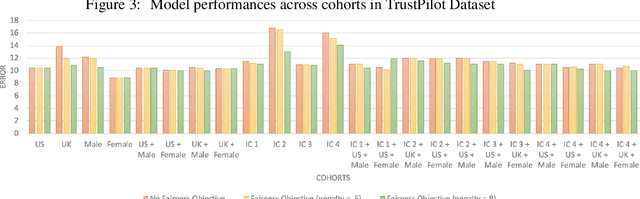
Recently, there has been a lot of interest in ensuring algorithmic fairness in machine learning where the central question is how to prevent sensitive information (e.g. knowledge about the ethnic group of an individual) from adding "unfair" bias to a learning algorithm (Feldman et al. (2015), Zemel et al. (2013)). This has led to several debiasing algorithms on word embeddings (Qian et al. (2019) , Bolukbasi et al. (2016)), coreference resolution (Zhao et al. (2018a)), semantic role labeling (Zhao et al. (2017)), etc. Most of these existing work deals with explicit sensitive features such as gender, occupations or race which doesn't work with data where such features are not captured due to privacy concerns. In this research work, we aim to achieve classification parity across explicit as well as implicit sensitive features. We define explicit cohorts as groups of people based on explicit sensitive attributes provided in the data (age, gender, race) whereas implicit cohorts are defined as groups of people with similar language usage. We obtain implicit cohorts by clustering embeddings of each individual trained on the language generated by them using a language model. We achieve two primary objectives in this work : [1.] We experimented and discovered classification performance differences across cohorts based on implicit and explicit features , [2] We improved classification parity by introducing modification to the loss function aimed to minimize the range of model performances across cohorts.
One-vs-All Models for Asynchronous Training: An Empirical Analysis
Jun 20, 2019

Any given classification problem can be modeled using multi-class or One-vs-All (OVA) architecture. An OVA system consists of as many OVA models as the number of classes, providing the advantage of asynchrony, where each OVA model can be re-trained independent of other models. This is particularly advantageous in settings where scalable model training is a consideration (for instance in an industrial environment where multiple and frequent updates need to be made to the classification system). In this paper, we conduct empirical analysis on realizing independent updates to OVA models and its impact on the accuracy of the overall OVA system. Given that asynchronous updates lead to differences in training datasets for OVA models, we first define a metric to quantify the differences in datasets. Thereafter, using Natural Language Understanding as a task of interest, we estimate the impact of three factors: (i) number of classes, (ii) number of data points and, (iii) divergences in training datasets across OVA models; on the OVA system accuracy. Finally, we observe the accuracy impact of increased asynchrony in a Spoken Language Understanding system. We analyze the results and establish that the proposed metric correlates strongly with the model performances in both the experimental settings.