 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoDA: Efficient Transfer Learning for Few-Shot Intent Classification
Jan 28, 2021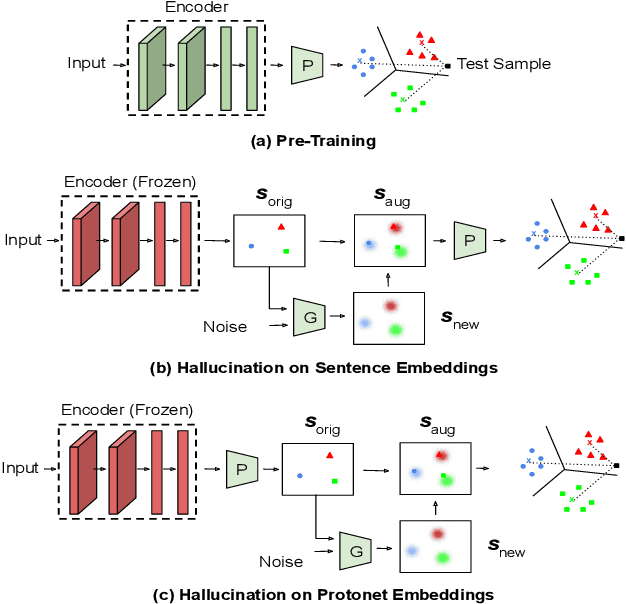


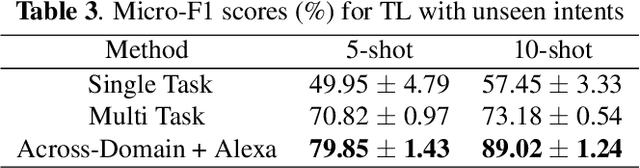
Practical sequence classification tasks in natural language processing often suffer from low training data availability for target classes. Recent works towards mitigating this problem have focused on transfer learning using embeddings pre-trained on often unrelated tasks, for instance, language modeling. We adopt an alternative approach by transfer learning on an ensemble of related tasks using prototypical networks under the meta-learning paradigm. Using intent classification as a case study, we demonstrate that increasing variability in training tasks can significantly improve classification performance. Further, we apply data augmentation in conjunction with meta-learning to reduce sampling bias. We make use of a conditional generator for data augmentation that is trained directly using the meta-learning objective and simultaneously with prototypical networks, hence ensuring that data augmentation is customized to the task. We explore augmentation in the sentence embedding space as well as prototypical embedding space. Combining meta-learning with augmentation provides upto 6.49% and 8.53% relative F1-score improvements over the best performing systems in the 5-shot and 10-shot learning, respectively.