 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying with Words, Improving with Rewards: Training Language Models for Creative Association
May 27, 2026Large Language Models (LLMs) are being applied to increasingly difficult problems and use cases. To navigate their vast solution spaces effectively, LLMs need to be creative. Yet the subjective nature of creativity and the limits of human judgment make training LLMs for creativity especially challenging. As a solution, we train LLMs on Codenames, a word-association game that exercises the two central axes of creativity, divergent and convergent thinking, while yielding objectively verifiable outcomes. This verifiability lets us bypass human judgment and train with Reinforcement Learning with Verifiable Rewards (RLVR). We train Qwen3-1.7B, 4B, and 8B models and evaluate them on ten creativity and four reasoning benchmarks. We find that the precision-diversity trade-off is scale-dependent: the 8B model prioritizes creativity over precision, while the 1.7B and 4B models gain reasoning precision at the cost of creativity. Concretely, the 8B model shows modest but consistent creativity gains (8 of 10 benchmarks) with only minor reasoning degradation, whereas the smaller models achieve substantial gains on reasoning tasks. Our study presents a scalable and effective solution to train LLMs for creativity.
ProtoDA: Efficient Transfer Learning for Few-Shot Intent Classification
Jan 28, 2021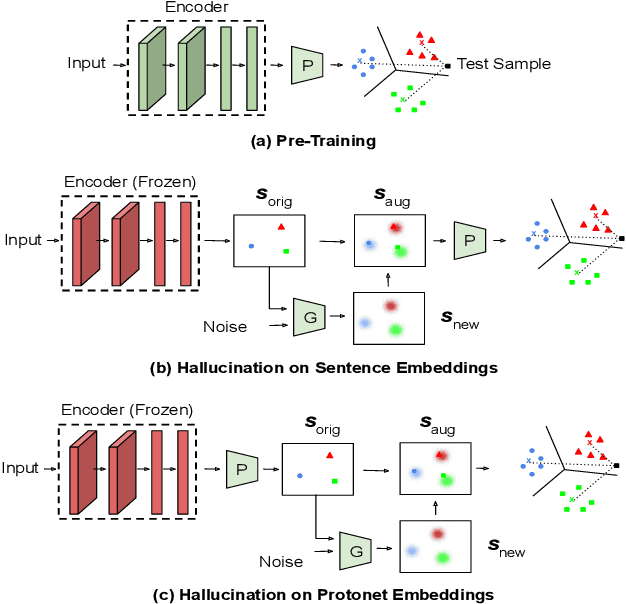


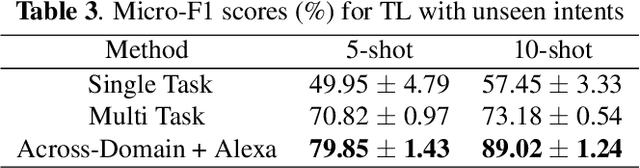
Practical sequence classification tasks in natural language processing often suffer from low training data availability for target classes. Recent works towards mitigating this problem have focused on transfer learning using embeddings pre-trained on often unrelated tasks, for instance, language modeling. We adopt an alternative approach by transfer learning on an ensemble of related tasks using prototypical networks under the meta-learning paradigm. Using intent classification as a case study, we demonstrate that increasing variability in training tasks can significantly improve classification performance. Further, we apply data augmentation in conjunction with meta-learning to reduce sampling bias. We make use of a conditional generator for data augmentation that is trained directly using the meta-learning objective and simultaneously with prototypical networks, hence ensuring that data augmentation is customized to the task. We explore augmentation in the sentence embedding space as well as prototypical embedding space. Combining meta-learning with augmentation provides upto 6.49% and 8.53% relative F1-score improvements over the best performing systems in the 5-shot and 10-shot learning, respectively.
A Closer Look At Feature Space Data Augmentation For Few-Shot Intent Classification
Oct 09, 2019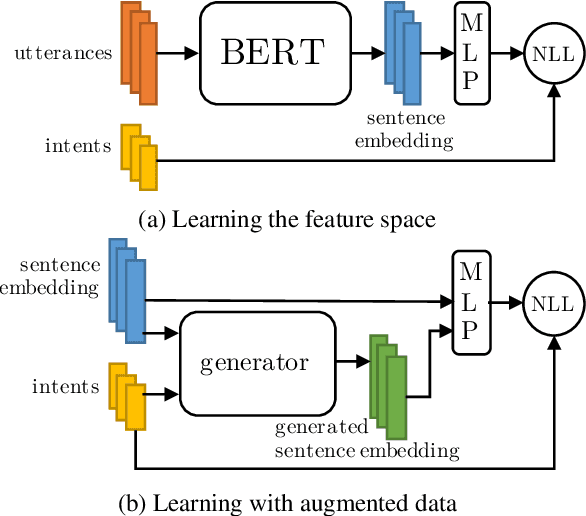
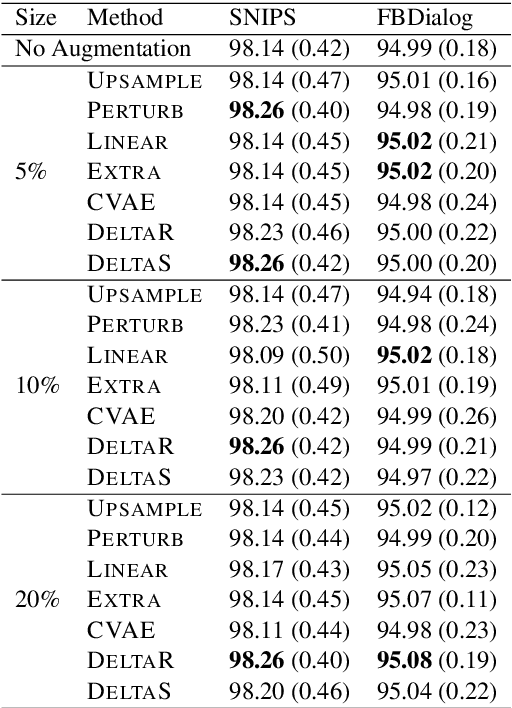
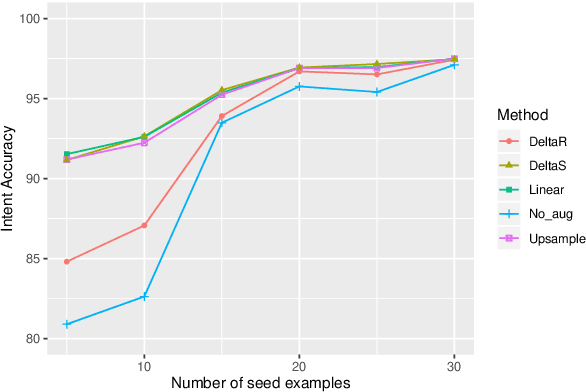

New conversation topics and functionalities are constantly being added to conversational AI agents like Amazon Alexa and Apple Siri. As data collection and annotation is not scalable and is often costly, only a handful of examples for the new functionalities are available, which results in poor generalization performance. We formulate it as a Few-Shot Integration (FSI) problem where a few examples are used to introduce a new intent. In this paper, we study six feature space data augmentation methods to improve classification performance in FSI setting in combination with both supervised and unsupervised representation learning methods such as BERT. Through realistic experiments on two public conversational datasets, SNIPS, and the Facebook Dialog corpus, we show that data augmentation in feature space provides an effective way to improve intent classification performance in few-shot setting beyond traditional transfer learning approaches. In particular, we show that (a) upsampling in latent space is a competitive baseline for feature space augmentation (b) adding the difference between two examples to a new example is a simple yet effective data augmentation method.