 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-Objective Statistically Fair Federated Learning
Jan 24, 2022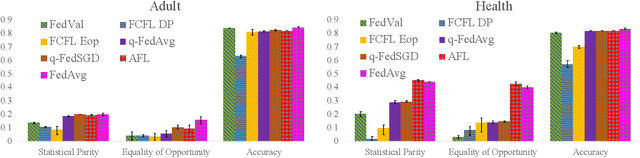

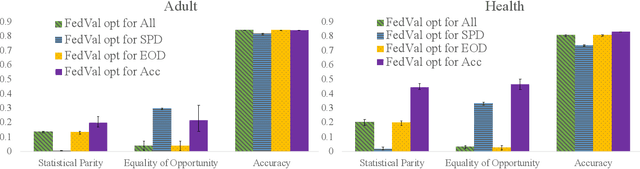
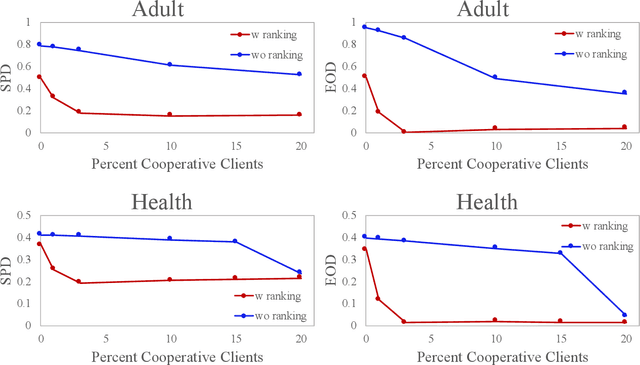
Federated Learning (FL) has emerged as a result of data ownership and privacy concerns to prevent data from being shared between multiple parties included in a training procedure. Although issues, such as privacy, have gained significant attention in this domain, not much attention has been given to satisfying statistical fairness measures in the FL setting. With this goal in mind, we conduct studies to show that FL is able to satisfy different fairness metrics under different data regimes consisting of different types of clients. More specifically, uncooperative or adversarial clients might contaminate the global FL model by injecting biased or poisoned models due to existing biases in their training datasets. Those biases might be a result of imbalanced training set (Zhang and Zhou 2019), historical biases (Mehrabi et al. 2021a), or poisoned data-points from data poisoning attacks against fairness (Mehrabi et al. 2021b; Solans, Biggio, and Castillo 2020). Thus, we propose a new FL framework that is able to satisfy multiple objectives including various statistical fairness metrics. Through experimentation, we then show the effectiveness of this method comparing it with various baselines, its ability in satisfying different objectives collectively and individually, and its ability in identifying uncooperative or adversarial clients and down-weighing their effect
A Closer Look At Feature Space Data Augmentation For Few-Shot Intent Classification
Oct 09, 2019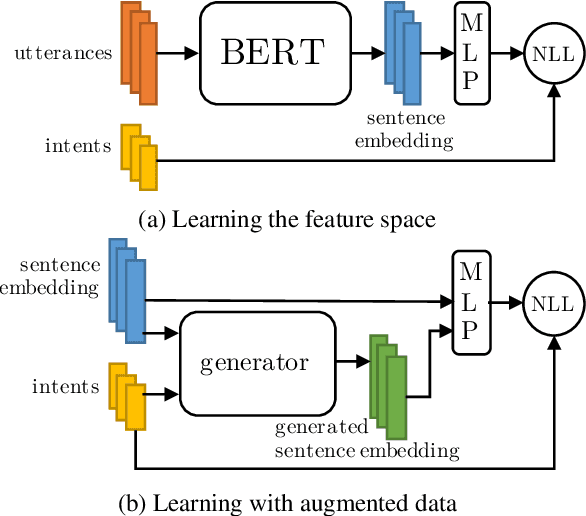
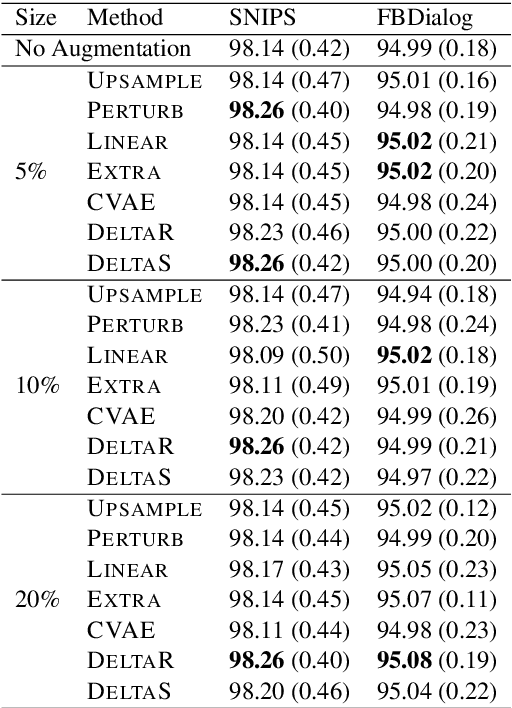
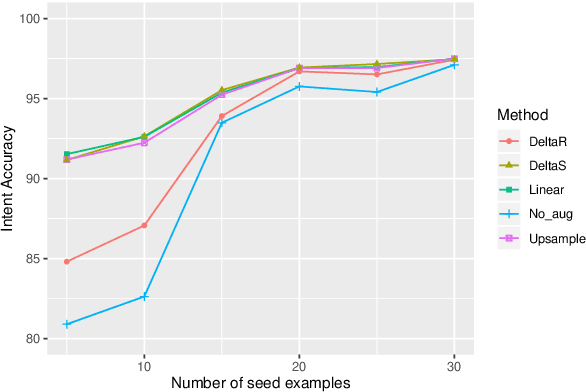

New conversation topics and functionalities are constantly being added to conversational AI agents like Amazon Alexa and Apple Siri. As data collection and annotation is not scalable and is often costly, only a handful of examples for the new functionalities are available, which results in poor generalization performance. We formulate it as a Few-Shot Integration (FSI) problem where a few examples are used to introduce a new intent. In this paper, we study six feature space data augmentation methods to improve classification performance in FSI setting in combination with both supervised and unsupervised representation learning methods such as BERT. Through realistic experiments on two public conversational datasets, SNIPS, and the Facebook Dialog corpus, we show that data augmentation in feature space provides an effective way to improve intent classification performance in few-shot setting beyond traditional transfer learning approaches. In particular, we show that (a) upsampling in latent space is a competitive baseline for feature space augmentation (b) adding the difference between two examples to a new example is a simple yet effective data augmentation method.