 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards classification parity across cohorts
May 16, 2020
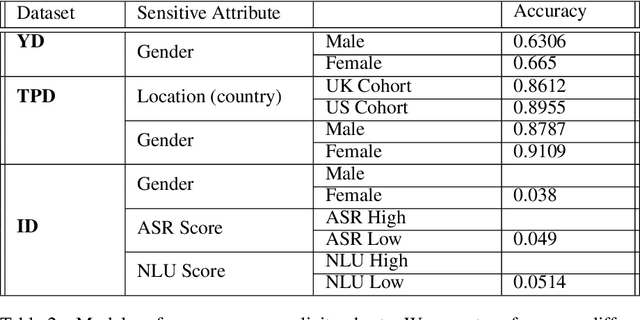
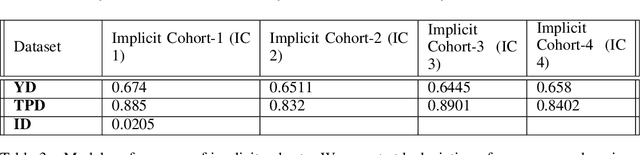
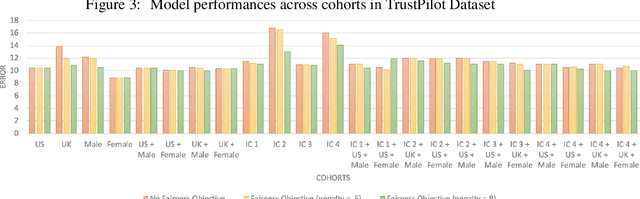
Recently, there has been a lot of interest in ensuring algorithmic fairness in machine learning where the central question is how to prevent sensitive information (e.g. knowledge about the ethnic group of an individual) from adding "unfair" bias to a learning algorithm (Feldman et al. (2015), Zemel et al. (2013)). This has led to several debiasing algorithms on word embeddings (Qian et al. (2019) , Bolukbasi et al. (2016)), coreference resolution (Zhao et al. (2018a)), semantic role labeling (Zhao et al. (2017)), etc. Most of these existing work deals with explicit sensitive features such as gender, occupations or race which doesn't work with data where such features are not captured due to privacy concerns. In this research work, we aim to achieve classification parity across explicit as well as implicit sensitive features. We define explicit cohorts as groups of people based on explicit sensitive attributes provided in the data (age, gender, race) whereas implicit cohorts are defined as groups of people with similar language usage. We obtain implicit cohorts by clustering embeddings of each individual trained on the language generated by them using a language model. We achieve two primary objectives in this work : [1.] We experimented and discovered classification performance differences across cohorts based on implicit and explicit features , [2] We improved classification parity by introducing modification to the loss function aimed to minimize the range of model performances across cohorts.