 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARES: Adaptive Red-Teaming and End-to-End Repair of Policy-Reward System
Apr 20, 2026Reinforcement Learning from Human Feedback (RLHF) is central to aligning Large Language Models (LLMs), yet it introduces a critical vulnerability: an imperfect Reward Model (RM) can become a single point of failure when it fails to penalize unsafe behaviors. While existing red-teaming approaches primarily target policy-level weaknesses, they overlook what we term systemic weaknesses cases where both the core LLM and the RM fail in tandem. We present ARES, a framework that systematically discovers and mitigates such dual vulnerabilities. ARES employs a ``Safety Mentor'' that dynamically composes semantically coherent adversarial prompts by combining structured component types (topics, personas, tactics, goals) and generates corresponding malicious and safe responses. This dual-targeting approach exposes weaknesses in both the core LLM and the RM simultaneously. Using the vulnerabilities gained, ARES implements a two-stage repair process: first fine-tuning the RM to better detect harmful content, then leveraging the improved RM to optimize the core model. Experiments across multiple adversarial safety benchmarks demonstrate that ARES substantially enhances safety robustness while preserving model capabilities, establishing a new paradigm for comprehensive RLHF safety alignment.
From Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025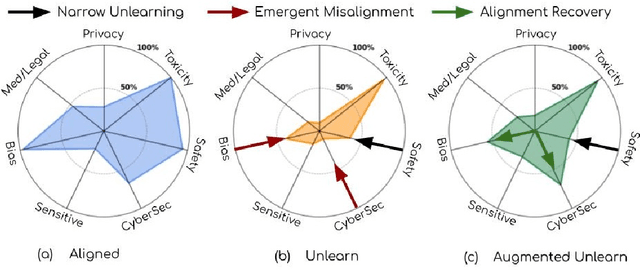
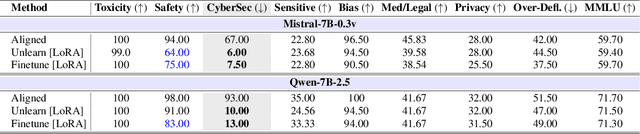
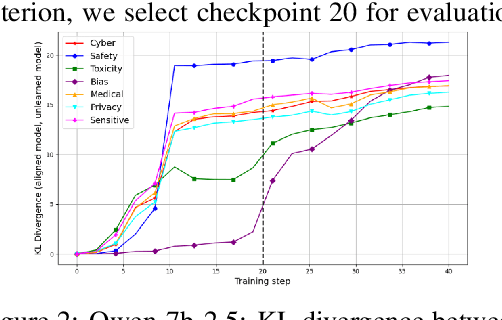
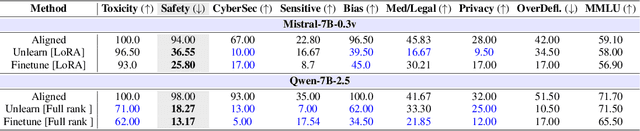
Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
Self-Correcting Large Language Models: Generation vs. Multiple Choice
Nov 12, 2025Large language models have recently demonstrated remarkable abilities to self-correct their responses through iterative refinement, often referred to as self-consistency or self-reflection. However, the dynamics of this self-correction mechanism may differ substantially depending on whether the model is tasked with open-ended text generation or with selecting the most appropriate response from multiple predefined options. In this paper, we conduct a systematic investigation of these two paradigms by comparing performance trends and error-correction behaviors across various natural language understanding and reasoning tasks, covering language models of different scales and families. Our experimental results reveal distinct patterns of improvement and failure modes: \textit{While open-ended generation often benefits from the flexibility of re-interpretation and compositional refinement, multiple-choice selection can leverage clearer solution boundaries but may be limited by the provided options}. This contrast also reflects the dual demands faced by emerging agentic LLM applications: effective agents must not only generate and refine open-ended plans or explanations, but also make reliable discrete choices when operating within constrained action spaces. Our findings, therefore, highlight that the design of self-correction mechanisms should take into account the interaction between task structure and output space, with implications for both knowledge-intensive reasoning and decision-oriented applications of LLMs.
Insights from the Inverse: Reconstructing LLM Training Goals Through Inverse RL
Oct 16, 2024



Large language models (LLMs) trained with Reinforcement Learning from Human Feedback (RLHF) have demonstrated remarkable capabilities, but their underlying reward functions and decision-making processes remain opaque. This paper introduces a novel approach to interpreting LLMs by applying inverse reinforcement learning (IRL) to recover their implicit reward functions. We conduct experiments on toxicity-aligned LLMs of varying sizes, extracting reward models that achieve up to 80.40% accuracy in predicting human preferences. Our analysis reveals key insights into the non-identifiability of reward functions, the relationship between model size and interpretability, and potential pitfalls in the RLHF process. We demonstrate that IRL-derived reward models can be used to fine-tune new LLMs, resulting in comparable or improved performance on toxicity benchmarks. This work provides a new lens for understanding and improving LLM alignment, with implications for the responsible development and deployment of these powerful systems.
Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Jul 20, 2024
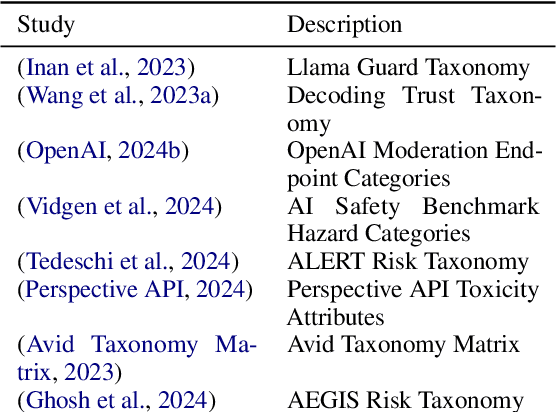

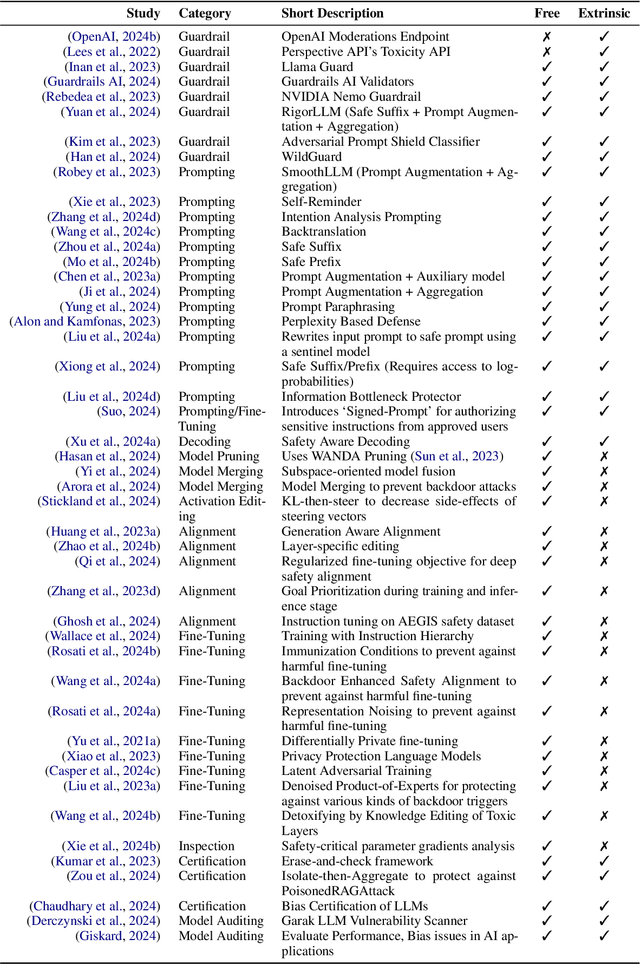
Creating secure and resilient applications with large language models (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness
Apr 29, 2024

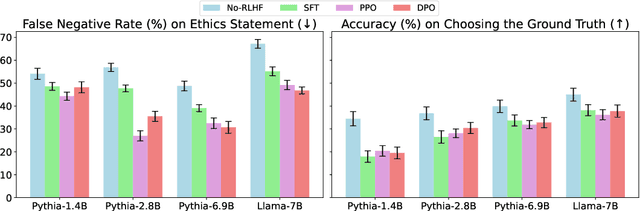

The surge in Large Language Models (LLMs) development has led to improved performance on cognitive tasks as well as an urgent need to align these models with human values in order to safely exploit their power. Despite the effectiveness of preference learning algorithms like Reinforcement Learning From Human Feedback (RLHF) in aligning human preferences, their assumed improvements on model trustworthiness haven't been thoroughly testified. Toward this end, this study investigates how models that have been aligned with general-purpose preference data on helpfulness and harmlessness perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. For model alignment, we focus on three widely used RLHF variants: Supervised Finetuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Through extensive empirical investigations, we discover that the improvement in trustworthiness by RLHF is far from guaranteed, and there exists a complex interplay between preference data, alignment algorithms, and specific trustworthiness aspects. Together, our results underscore the need for more nuanced approaches for model alignment. By shedding light on the intricate dynamics of these components within model alignment, we hope this research will guide the community towards developing language models that are both capable and trustworthy.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Apr 10, 2024



We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer
Understanding the Effects of Iterative Prompting on Truthfulness
Feb 09, 2024The development of Large Language Models (LLMs) has notably transformed numerous sectors, offering impressive text generation capabilities. Yet, the reliability and truthfulness of these models remain pressing concerns. To this end, we investigate iterative prompting, a strategy hypothesized to refine LLM responses, assessing its impact on LLM truthfulness, an area which has not been thoroughly explored. Our extensive experiments delve into the intricacies of iterative prompting variants, examining their influence on the accuracy and calibration of model responses. Our findings reveal that naive prompting methods significantly undermine truthfulness, leading to exacerbated calibration errors. In response to these challenges, we introduce several prompting variants designed to address the identified issues. These variants demonstrate marked improvements over existing baselines, signaling a promising direction for future research. Our work provides a nuanced understanding of iterative prompting and introduces novel approaches to enhance the truthfulness of LLMs, thereby contributing to the development of more accurate and trustworthy AI systems.
Black-Box Access is Insufficient for Rigorous AI Audits
Jan 25, 2024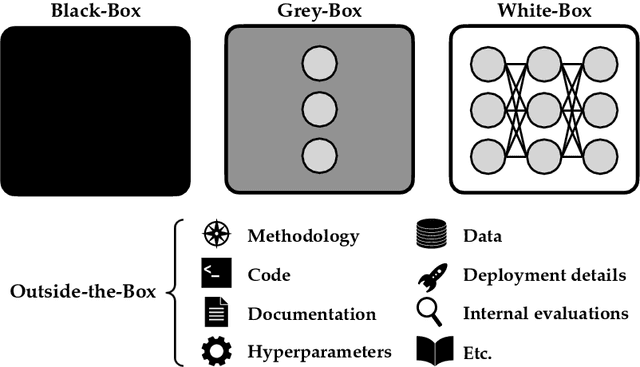
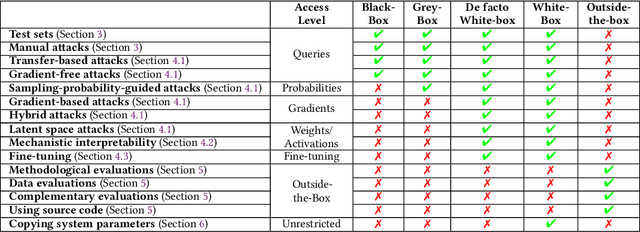
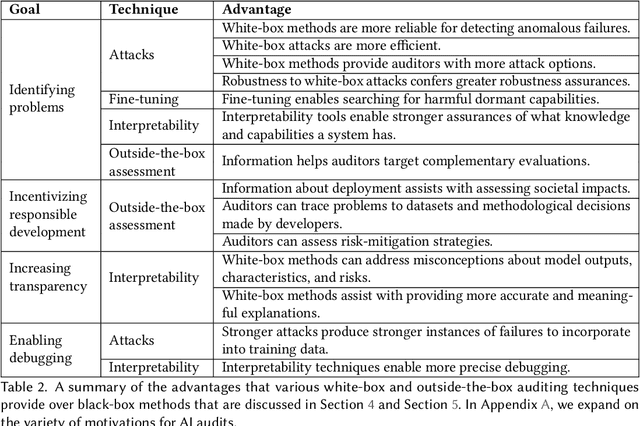
External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of system access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to its training and deployment information (e.g., methodology, code, documentation, hyperparameters, data, deployment details, findings from internal evaluations) allows for auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.
On the Intersection of Self-Correction and Trust in Language Models
Nov 06, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in performing complex cognitive tasks. However, their complexity and lack of transparency have raised several trustworthiness concerns, including the propagation of misinformation and toxicity. Recent research has explored the self-correction capabilities of LLMs to enhance their performance. In this work, we investigate whether these self-correction capabilities can be harnessed to improve the trustworthiness of LLMs. We conduct experiments focusing on two key aspects of trustworthiness: truthfulness and toxicity. Our findings reveal that self-correction can lead to improvements in toxicity and truthfulness, but the extent of these improvements varies depending on the specific aspect of trustworthiness and the nature of the task. Interestingly, our study also uncovers instances of "self-doubt" in LLMs during the self-correction process, introducing a new set of challenges that need to be addressed.