 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADLADS: Rapid Attention Distillation to Linear Attention Decoders at Scale
May 07, 2025We present Rapid Attention Distillation to Linear Attention Decoders at Scale (RADLADS), a protocol for rapidly converting softmax attention transformers into linear attention decoder models, along with two new RWKV-variant architectures, and models converted from popular Qwen2.5 open source models in 7B, 32B, and 72B sizes. Our conversion process requires only 350-700M tokens, less than 0.005% of the token count used to train the original teacher models. Converting to our 72B linear attention model costs less than \$2,000 USD at today's prices, yet quality at inference remains close to the original transformer. These models achieve state-of-the-art downstream performance across a set of standard benchmarks for linear attention models of their size. We release all our models on HuggingFace under the Apache 2.0 license, with the exception of our 72B models which are also governed by the Qwen License Agreement. Models at https://huggingface.co/collections/recursal/radlads-6818ee69e99e729ba8a87102 Training Code at https://github.com/recursal/RADLADS-paper
RWKV-7 "Goose" with Expressive Dynamic State Evolution
Mar 18, 2025We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion parameter scale on multilingual tasks, and match current SoTA English language performance despite being trained on dramatically fewer tokens than other top 3B models. Nevertheless, RWKV-7 models require only constant memory usage and constant inference time per token. RWKV-7 introduces a newly generalized formulation of the delta rule with vector-valued gating and in-context learning rates, as well as a relaxed value replacement rule. We show that RWKV-7 can perform state tracking and recognize all regular languages, while retaining parallelizability of training. This exceeds the capabilities of Transformers under standard complexity conjectures, which are limited to $\mathsf{TC}^0$. To demonstrate RWKV-7's language modeling capability, we also present an extended open source 3.1 trillion token multilingual corpus, and train four RWKV-7 models ranging from 0.19 billion to 2.9 billion parameters on this dataset. To foster openness, reproduction, and adoption, we release our models and dataset component listing at https://huggingface.co/RWKV, and our training and inference code at https://github.com/RWKV/RWKV-LM all under the Apache 2.0 License.
GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression
Jul 16, 2024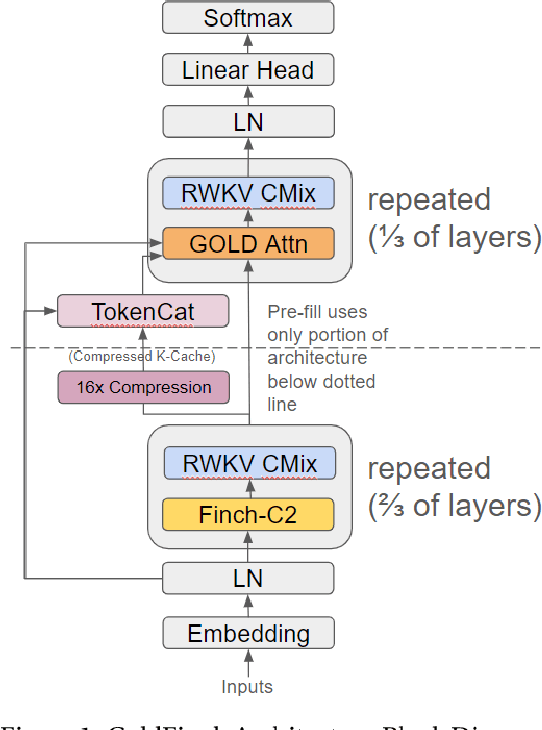

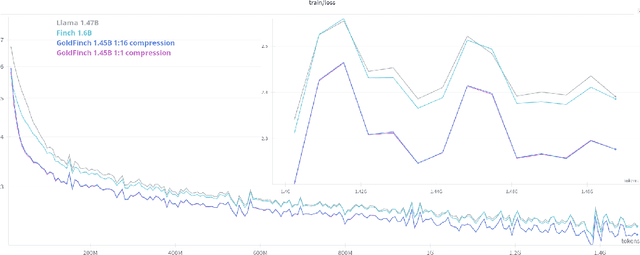

We introduce GoldFinch, a hybrid Linear Attention/Transformer sequence model that uses a new technique to efficiently generate a highly compressed and reusable KV-Cache in linear time and space with respect to sequence length. GoldFinch stacks our new GOLD transformer on top of an enhanced version of the Finch (RWKV-6) architecture. We train up to 1.5B parameter class models of the Finch, Llama, and GoldFinch architectures, and find dramatically improved modeling performance relative to both Finch and Llama. Our cache size savings increase linearly with model layer count, ranging from 756-2550 times smaller than the traditional transformer cache for common sizes, enabling inference of extremely large context lengths even on limited hardware. Although autoregressive generation has O(n) time complexity per token because of attention, pre-fill computation of the entire initial cache state for a submitted context costs only O(1) time per token due to the use of a recurrent neural network (RNN) to generate this cache. We release our trained weights and training code under the Apache 2.0 license for community use.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Apr 10, 2024



We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer