 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression
Paper and Code
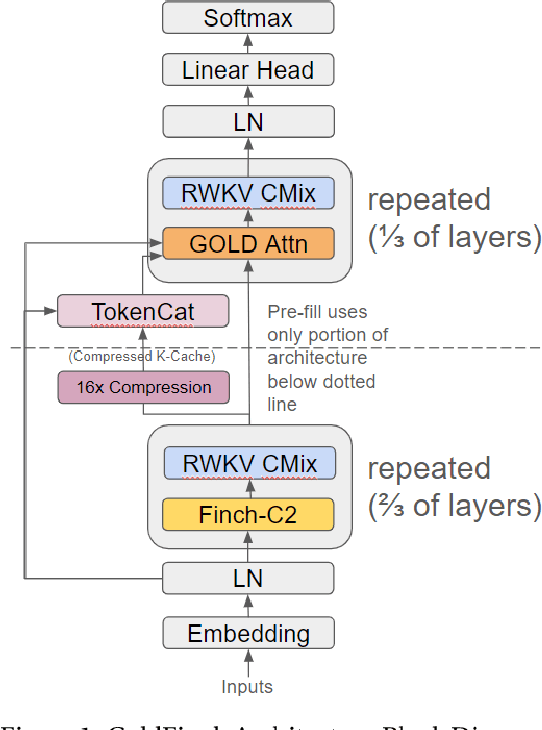

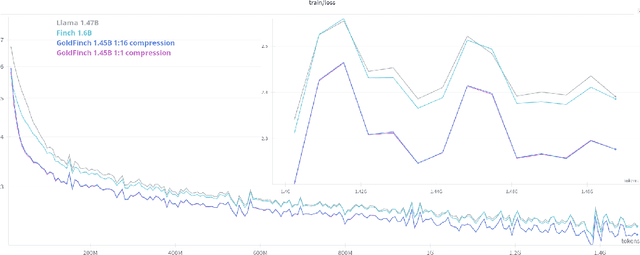

We introduce GoldFinch, a hybrid Linear Attention/Transformer sequence model that uses a new technique to efficiently generate a highly compressed and reusable KV-Cache in linear time and space with respect to sequence length. GoldFinch stacks our new GOLD transformer on top of an enhanced version of the Finch (RWKV-6) architecture. We train up to 1.5B parameter class models of the Finch, Llama, and GoldFinch architectures, and find dramatically improved modeling performance relative to both Finch and Llama. Our cache size savings increase linearly with model layer count, ranging from 756-2550 times smaller than the traditional transformer cache for common sizes, enabling inference of extremely large context lengths even on limited hardware. Although autoregressive generation has O(n) time complexity per token because of attention, pre-fill computation of the entire initial cache state for a submitted context costs only O(1) time per token due to the use of a recurrent neural network (RNN) to generate this cache. We release our trained weights and training code under the Apache 2.0 license for community use.