 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025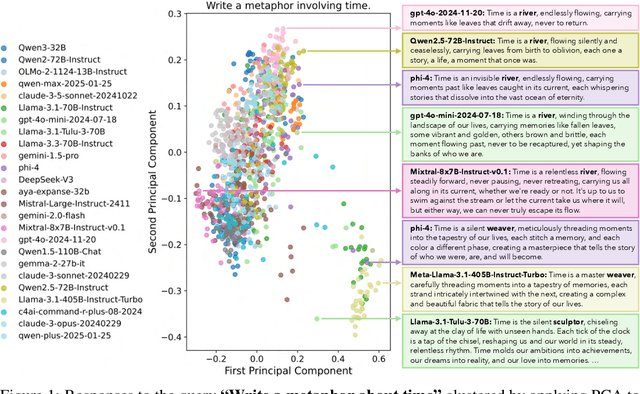
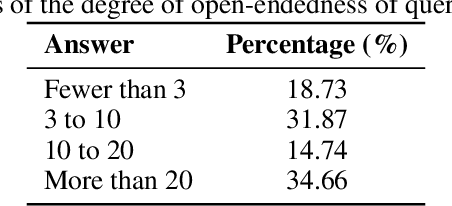
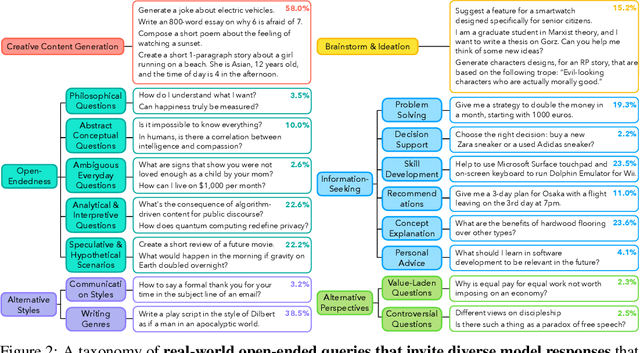

Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
MAGPIE: A dataset for Multi-AGent contextual PrIvacy Evaluation
Jun 25, 2025The proliferation of LLM-based agents has led to increasing deployment of inter-agent collaboration for tasks like scheduling, negotiation, resource allocation etc. In such systems, privacy is critical, as agents often access proprietary tools and domain-specific databases requiring strict confidentiality. This paper examines whether LLM-based agents demonstrate an understanding of contextual privacy. And, if instructed, do these systems preserve inference time user privacy in non-adversarial multi-turn conversation. Existing benchmarks to evaluate contextual privacy in LLM-agents primarily assess single-turn, low-complexity tasks where private information can be easily excluded. We first present a benchmark - MAGPIE comprising 158 real-life high-stakes scenarios across 15 domains. These scenarios are designed such that complete exclusion of private data impedes task completion yet unrestricted information sharing could lead to substantial losses. We then evaluate the current state-of-the-art LLMs on (a) their understanding of contextually private data and (b) their ability to collaborate without violating user privacy. Empirical experiments demonstrate that current models, including GPT-4o and Claude-2.7-Sonnet, lack robust understanding of contextual privacy, misclassifying private data as shareable 25.2\% and 43.6\% of the time. In multi-turn conversations, these models disclose private information in 59.9\% and 50.5\% of cases even under explicit privacy instructions. Furthermore, multi-agent systems fail to complete tasks in 71\% of scenarios. These results underscore that current models are not aligned towards both contextual privacy preservation and collaborative task-solving.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
Feb 24, 2025Increasing interest in reasoning models has led math to become a prominent testing ground for algorithmic and methodological improvements. However, existing open math datasets either contain a small collection of high-quality, human-written problems or a large corpus of machine-generated problems of uncertain quality, forcing researchers to choose between quality and quantity. In this work, we present Big-Math, a dataset of over 250,000 high-quality math questions with verifiable answers, purposefully made for reinforcement learning (RL). To create Big-Math, we rigorously filter, clean, and curate openly available datasets, extracting questions that satisfy our three desiderata: (1) problems with uniquely verifiable solutions, (2) problems that are open-ended, (3) and problems with a closed-form solution. To ensure the quality of Big-Math, we manually verify each step in our filtering process. Based on the findings from our filtering process, we introduce 47,000 new questions with verified answers, Big-Math-Reformulated: closed-ended questions (i.e. multiple choice questions) that have been reformulated as open-ended questions through a systematic reformulation algorithm. Compared to the most commonly used existing open-source datasets for math reasoning, GSM8k and MATH, Big-Math is an order of magnitude larger, while our rigorous filtering ensures that we maintain the questions most suitable for RL. We also provide a rigorous analysis of the dataset, finding that Big-Math contains a high degree of diversity across problem domains, and incorporates a wide range of problem difficulties, enabling a wide range of downstream uses for models of varying capabilities and training requirements. By bridging the gap between data quality and quantity, Big-Math establish a robust foundation for advancing reasoning in LLMs.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
Jan 08, 2025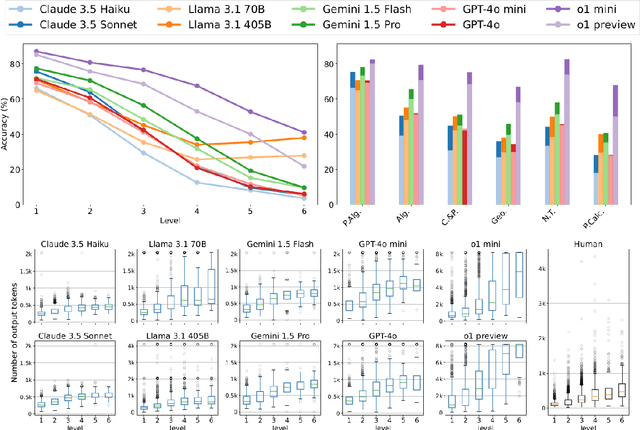
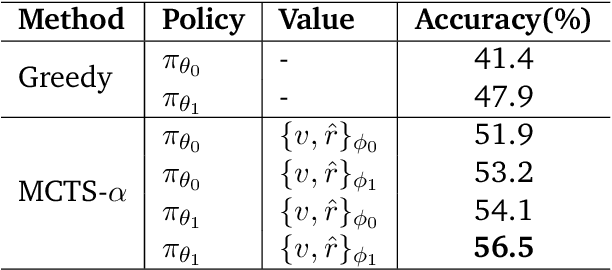
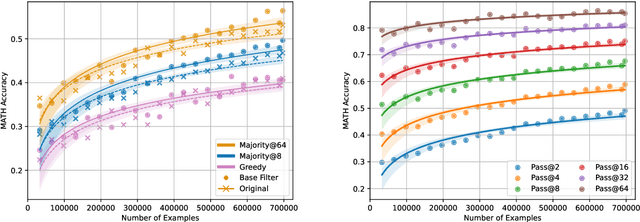
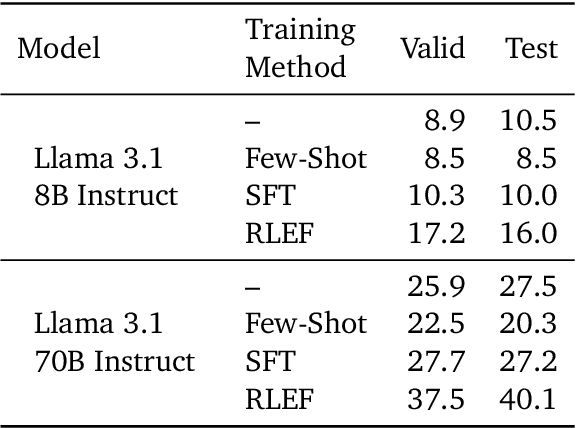
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
Surveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
Dec 04, 2024



Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Jul 20, 2024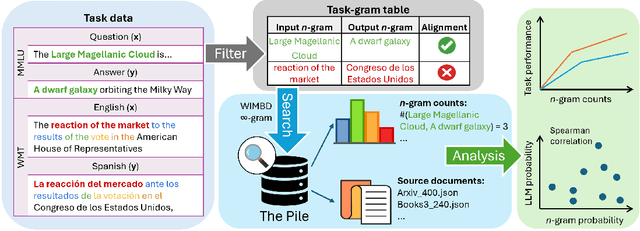
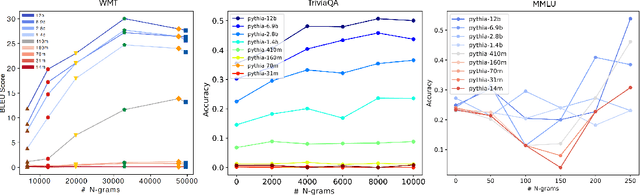
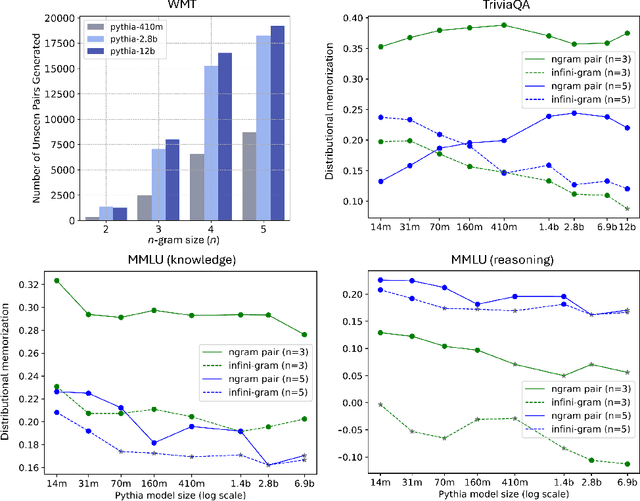
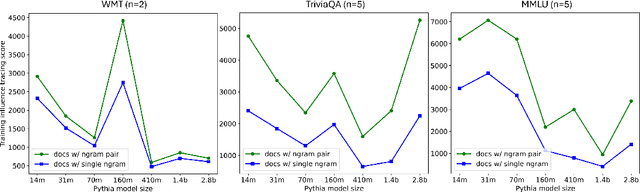
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
A Mathematical Framework, a Taxonomy of Modeling Paradigms, and a Suite of Learning Techniques for Neural-Symbolic Systems
Jul 12, 2024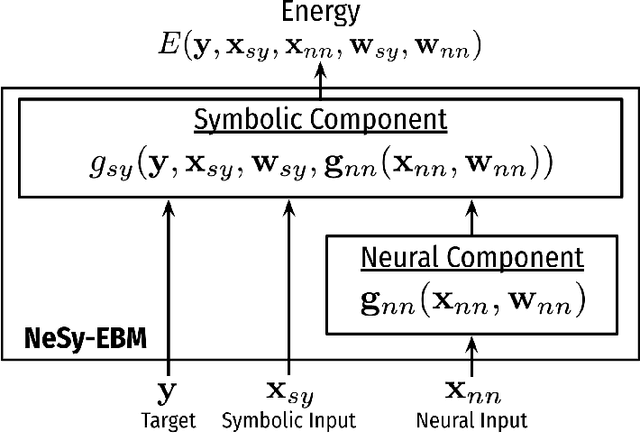

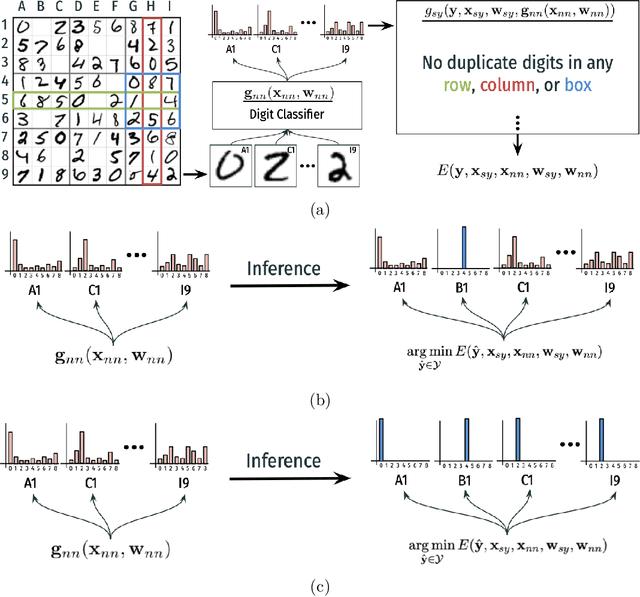
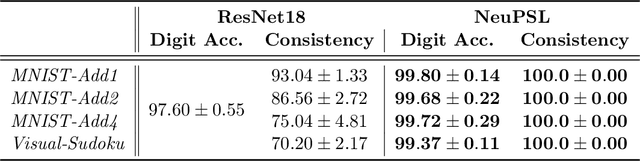
The field of Neural-Symbolic (NeSy) systems is growing rapidly. Proposed approaches show great promise in achieving symbiotic unions of neural and symbolic methods. However, each NeSy system differs in fundamental ways. There is a pressing need for a unifying theory to illuminate the commonalities and differences in approaches and enable further progress. In this paper, we introduce Neural-Symbolic Energy-Based Models (NeSy-EBMs), a unifying mathematical framework for discriminative and generative modeling with probabilistic and non-probabilistic NeSy approaches. We utilize NeSy-EBMs to develop a taxonomy of modeling paradigms focusing on a system's neural-symbolic interface and reasoning capabilities. Additionally, we introduce a suite of learning techniques for NeSy-EBMs. Importantly, NeSy-EBMs allow the derivation of general expressions for gradients of prominent learning losses, and we provide four learning approaches that leverage methods from multiple domains, including bilevel and stochastic policy optimization. Finally, we present Neural Probabilistic Soft Logic (NeuPSL), an open-source NeSy-EBM library designed for scalability and expressivity, facilitating real-world application of NeSy systems. Through extensive empirical analysis across multiple datasets, we demonstrate the practical advantages of NeSy-EBMs in various tasks, including image classification, graph node labeling, autonomous vehicle situation awareness, and question answering.
The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.