 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpRL: Exploratory RL for LLM Mid-Training
Jun 15, 2026Sparse reward reinforcement learning (RL) has become a standard tool for improving LLM reasoning, but its success depends critically on the coverage present in the base model. In practice, models are often primed for RL through \emph{mid-training} on curated reasoning traces that teach useful primitive skills such as decomposition, verification, or self-correction. Although effective, this strategy requires manually specifying what the model should learn, and it remains unclear whether such primitive coverage is enough for much harder problems, which require combining these skills into broader solution strategies. We study a more automated approach: \emph{RL-based mid-training} using large corpora of human-written question-answer data. Rather than treating reference solutions as targets to imitate, our method, ExpRL, uses them as \emph{reward scaffolds}: references are hidden from the policy and used only to construct problem-specific grading rubrics for judging on-policy reasoning traces. The policy samples from the original problem prompt, while an LLM judge compares the sampled reasoning trace against the reference solution and assigns outcome-level or process-level dense rewards. This lets ExpRL reinforce partial progress, useful intermediate reductions, and productive reasoning behaviors that sparse final-answer rewards often fail to upweight. On challenging math reasoning tasks, ExpRL yields stronger RL priming than SFT, sparse-reward GRPO, and self-distillation, and provides a better initialization for subsequent sparse-reward RL. Additional mixed-domain experiments further suggest that ExpRL can extend beyond the original math-only setting.
Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning
Jun 06, 2025Large reasoning models (LRMs) achieve higher performance on challenging reasoning tasks by generating more tokens at inference time, but this verbosity often wastes computation on easy problems. Existing solutions, including supervised finetuning on shorter traces, user-controlled budgets, or RL with uniform penalties, either require data curation, manual configuration, or treat all problems alike regardless of difficulty. We introduce Adaptive Length Penalty (ALP), a reinforcement learning objective tailoring generation length to per-prompt solve rate. During training, ALP monitors each prompt's online solve rate through multiple rollouts and adds a differentiable penalty whose magnitude scales inversely with that rate, so confident (easy) prompts incur a high cost for extra tokens while hard prompts remain unhindered. Posttraining DeepScaleR-1.5B with ALP cuts average token usage by 50\% without significantly dropping performance. Relative to fixed-budget and uniform penalty baselines, ALP redistributes its reduced budget more intelligently by cutting compute on easy prompts and reallocating saved tokens to difficult ones, delivering higher accuracy on the hardest problems with higher cost.
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
Feb 24, 2025Increasing interest in reasoning models has led math to become a prominent testing ground for algorithmic and methodological improvements. However, existing open math datasets either contain a small collection of high-quality, human-written problems or a large corpus of machine-generated problems of uncertain quality, forcing researchers to choose between quality and quantity. In this work, we present Big-Math, a dataset of over 250,000 high-quality math questions with verifiable answers, purposefully made for reinforcement learning (RL). To create Big-Math, we rigorously filter, clean, and curate openly available datasets, extracting questions that satisfy our three desiderata: (1) problems with uniquely verifiable solutions, (2) problems that are open-ended, (3) and problems with a closed-form solution. To ensure the quality of Big-Math, we manually verify each step in our filtering process. Based on the findings from our filtering process, we introduce 47,000 new questions with verified answers, Big-Math-Reformulated: closed-ended questions (i.e. multiple choice questions) that have been reformulated as open-ended questions through a systematic reformulation algorithm. Compared to the most commonly used existing open-source datasets for math reasoning, GSM8k and MATH, Big-Math is an order of magnitude larger, while our rigorous filtering ensures that we maintain the questions most suitable for RL. We also provide a rigorous analysis of the dataset, finding that Big-Math contains a high degree of diversity across problem domains, and incorporates a wide range of problem difficulties, enabling a wide range of downstream uses for models of varying capabilities and training requirements. By bridging the gap between data quality and quantity, Big-Math establish a robust foundation for advancing reasoning in LLMs.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
Jan 08, 2025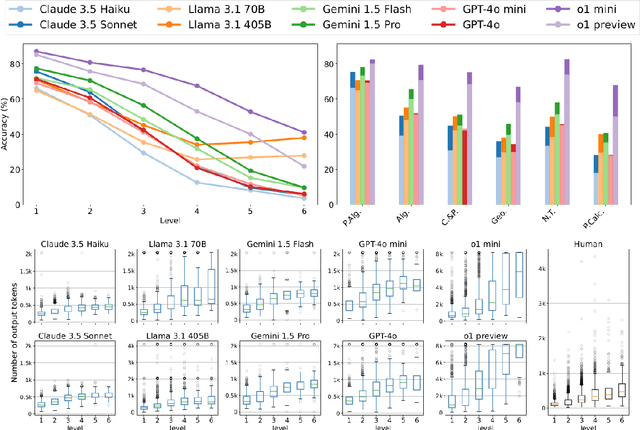
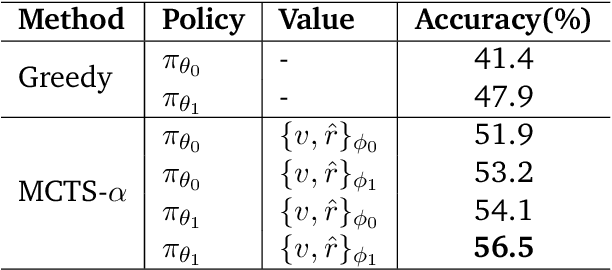
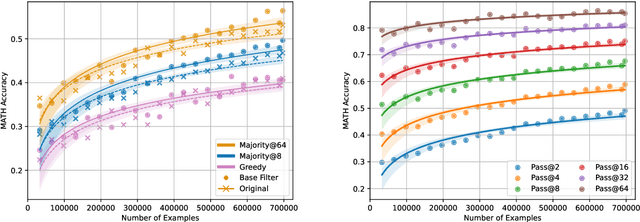
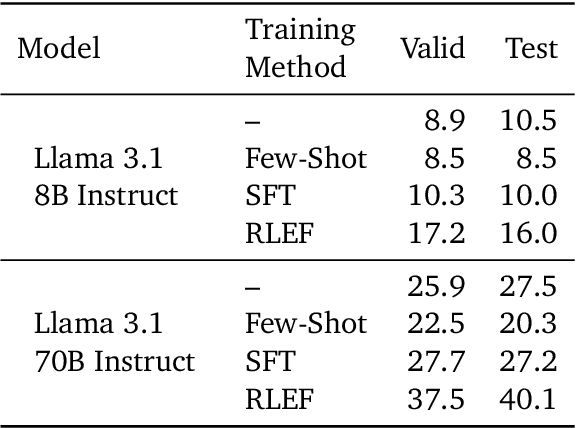
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
Hypothetical Minds: Scaffolding Theory of Mind for Multi-Agent Tasks with Large Language Models
Jul 09, 2024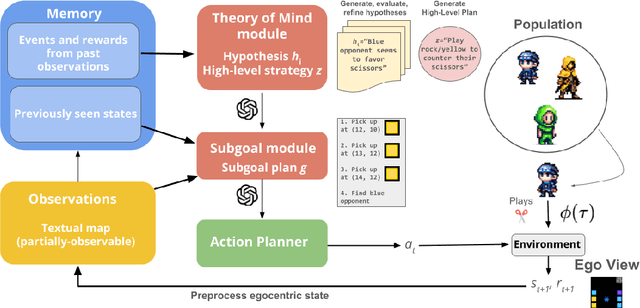
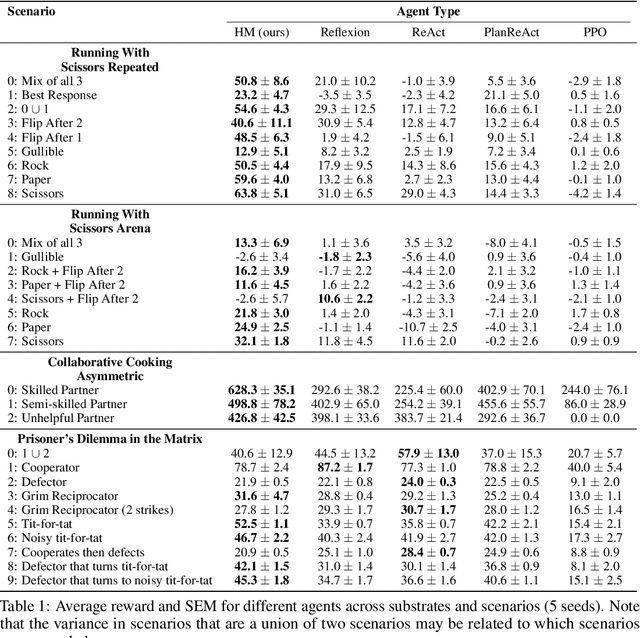
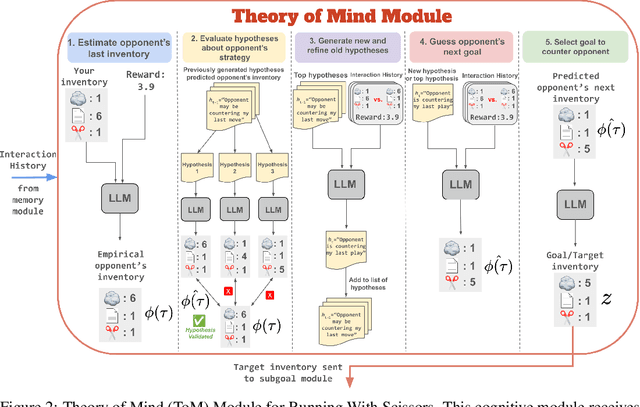
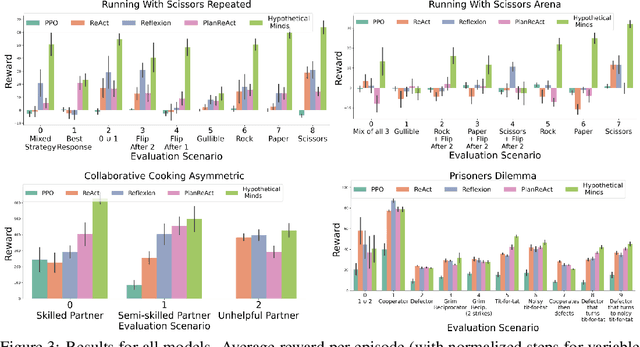
Multi-agent reinforcement learning (MARL) methods struggle with the non-stationarity of multi-agent systems and fail to adaptively learn online when tested with novel agents. Here, we leverage large language models (LLMs) to create an autonomous agent that can handle these challenges. Our agent, Hypothetical Minds, consists of a cognitively-inspired architecture, featuring modular components for perception, memory, and hierarchical planning over two levels of abstraction. We introduce the Theory of Mind module that scaffolds the high-level planning process by generating hypotheses about other agents' strategies in natural language. It then evaluates and iteratively refines these hypotheses by reinforcing hypotheses that make correct predictions about the other agents' behavior. Hypothetical Minds significantly improves performance over previous LLM-agent and RL baselines on a range of competitive, mixed motive, and collaborative domains in the Melting Pot benchmark, including both dyadic and population-based environments. Additionally, comparisons against LLM-agent baselines and ablations reveal the importance of hypothesis evaluation and refinement for succeeding on complex scenarios.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024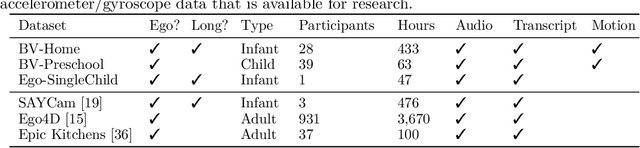
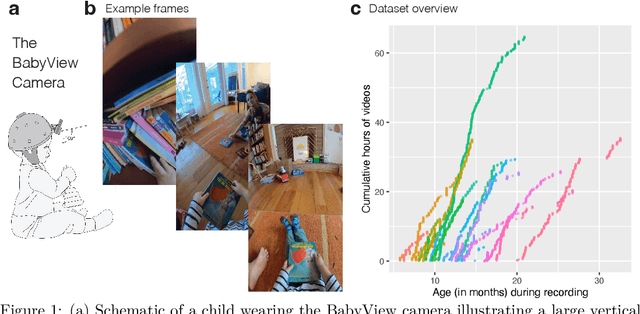
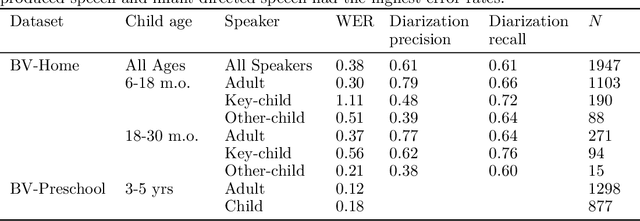
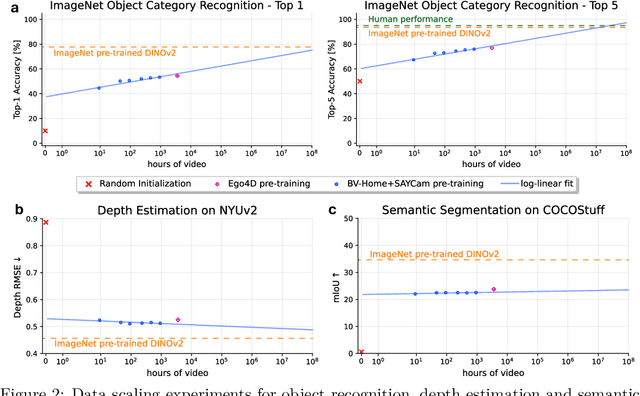
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?