 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Generators: Generating Diverse Synthetic Personas at Scale
Feb 03, 2026Evaluating AI systems that interact with humans requires understanding their behavior across diverse user populations, but collecting representative human data is often expensive or infeasible, particularly for novel technologies or hypothetical future scenarios. Recent work in Generative Agent-Based Modeling has shown that large language models can simulate human-like synthetic personas with high fidelity, accurately reproducing the beliefs and behaviors of specific individuals. However, most approaches require detailed data about target populations and often prioritize density matching (replicating what is most probable) rather than support coverage (spanning what is possible), leaving long-tail behaviors underexplored. We introduce Persona Generators, functions that can produce diverse synthetic populations tailored to arbitrary contexts. We apply an iterative improvement loop based on AlphaEvolve, using large language models as mutation operators to refine our Persona Generator code over hundreds of iterations. The optimization process produces lightweight Persona Generators that can automatically expand small descriptions into populations of diverse synthetic personas that maximize coverage of opinions and preferences along relevant diversity axes. We demonstrate that evolved generators substantially outperform existing baselines across six diversity metrics on held-out contexts, producing populations that span rare trait combinations difficult to achieve in standard LLM outputs.
FactorSim: Generative Simulation via Factorized Representation
Sep 26, 2024Generating simulations to train intelligent agents in game-playing and robotics from natural language input, from user input or task documentation, remains an open-ended challenge. Existing approaches focus on parts of this challenge, such as generating reward functions or task hyperparameters. Unlike previous work, we introduce FACTORSIM that generates full simulations in code from language input that can be used to train agents. Exploiting the structural modularity specific to coded simulations, we propose to use a factored partially observable Markov decision process representation that allows us to reduce context dependence during each step of the generation. For evaluation, we introduce a generative simulation benchmark that assesses the generated simulation code's accuracy and effectiveness in facilitating zero-shot transfers in reinforcement learning settings. We show that FACTORSIM outperforms existing methods in generating simulations regarding prompt alignment (e.g., accuracy), zero-shot transfer abilities, and human evaluation. We also demonstrate its effectiveness in generating robotic tasks.
Hypothetical Minds: Scaffolding Theory of Mind for Multi-Agent Tasks with Large Language Models
Jul 09, 2024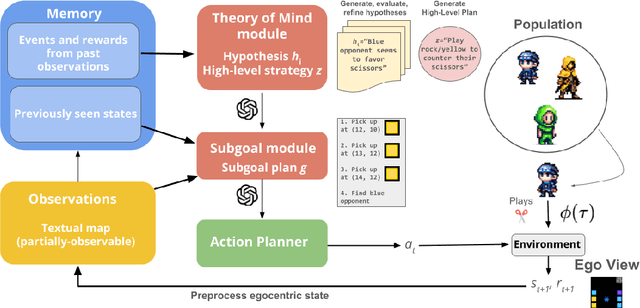
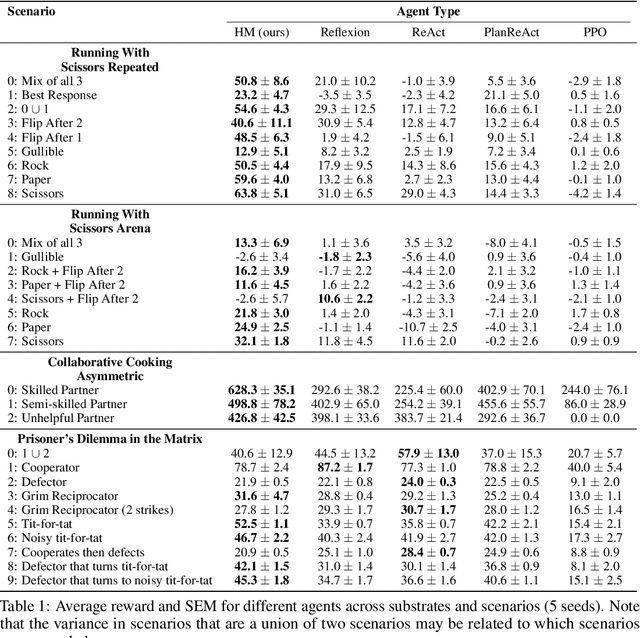
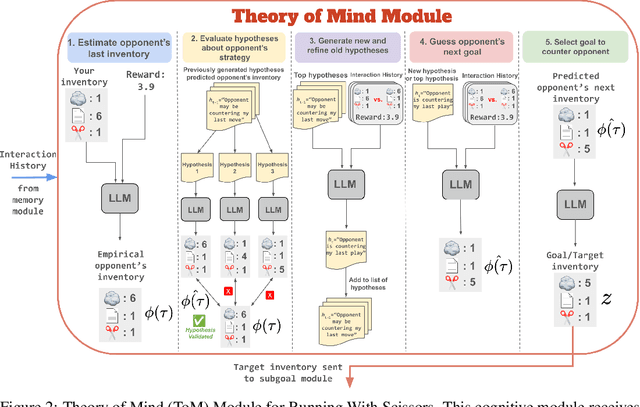
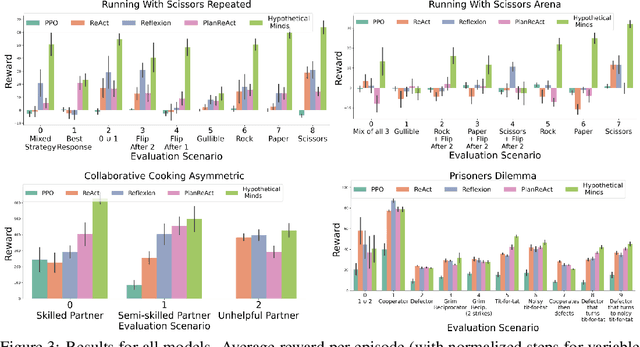
Multi-agent reinforcement learning (MARL) methods struggle with the non-stationarity of multi-agent systems and fail to adaptively learn online when tested with novel agents. Here, we leverage large language models (LLMs) to create an autonomous agent that can handle these challenges. Our agent, Hypothetical Minds, consists of a cognitively-inspired architecture, featuring modular components for perception, memory, and hierarchical planning over two levels of abstraction. We introduce the Theory of Mind module that scaffolds the high-level planning process by generating hypotheses about other agents' strategies in natural language. It then evaluates and iteratively refines these hypotheses by reinforcing hypotheses that make correct predictions about the other agents' behavior. Hypothetical Minds significantly improves performance over previous LLM-agent and RL baselines on a range of competitive, mixed motive, and collaborative domains in the Melting Pot benchmark, including both dyadic and population-based environments. Additionally, comparisons against LLM-agent baselines and ablations reveal the importance of hypothesis evaluation and refinement for succeeding on complex scenarios.