 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Generators: Generating Diverse Synthetic Personas at Scale
Feb 03, 2026Evaluating AI systems that interact with humans requires understanding their behavior across diverse user populations, but collecting representative human data is often expensive or infeasible, particularly for novel technologies or hypothetical future scenarios. Recent work in Generative Agent-Based Modeling has shown that large language models can simulate human-like synthetic personas with high fidelity, accurately reproducing the beliefs and behaviors of specific individuals. However, most approaches require detailed data about target populations and often prioritize density matching (replicating what is most probable) rather than support coverage (spanning what is possible), leaving long-tail behaviors underexplored. We introduce Persona Generators, functions that can produce diverse synthetic populations tailored to arbitrary contexts. We apply an iterative improvement loop based on AlphaEvolve, using large language models as mutation operators to refine our Persona Generator code over hundreds of iterations. The optimization process produces lightweight Persona Generators that can automatically expand small descriptions into populations of diverse synthetic personas that maximize coverage of opinions and preferences along relevant diversity axes. We demonstrate that evolved generators substantially outperform existing baselines across six diversity metrics on held-out contexts, producing populations that span rare trait combinations difficult to achieve in standard LLM outputs.
Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025



Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
D3PO: Preference-Based Alignment of Discrete Diffusion Models
Mar 11, 2025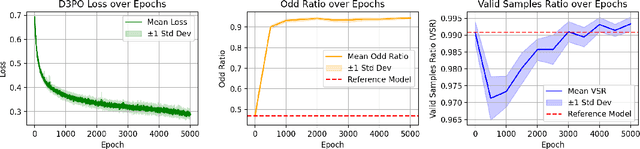
Diffusion models have achieved state-of-the-art performance across multiple domains, with recent advancements extending their applicability to discrete data. However, aligning discrete diffusion models with task-specific preferences remains challenging, particularly in scenarios where explicit reward functions are unavailable. In this work, we introduce Discrete Diffusion DPO (D3PO), the first adaptation of Direct Preference Optimization (DPO) to discrete diffusion models formulated as continuous-time Markov chains. Our approach derives a novel loss function that directly fine-tunes the generative process using preference data while preserving fidelity to a reference distribution. We validate D3PO on a structured binary sequence generation task, demonstrating that the method effectively aligns model outputs with preferences while maintaining structural validity. Our results highlight that D3PO enables controlled fine-tuning without requiring explicit reward models, making it a practical alternative to reinforcement learning-based approaches. Future research will explore extending D3PO to more complex generative tasks, including language modeling and protein sequence generation, as well as investigating alternative noise schedules, such as uniform noising, to enhance flexibility across different applications.
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs
Jun 03, 2024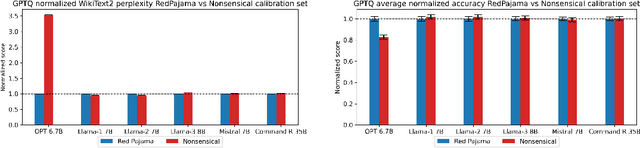
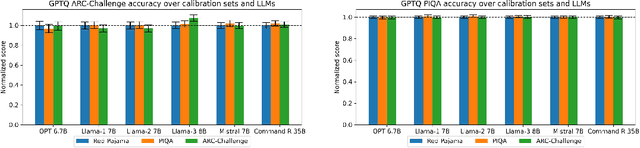
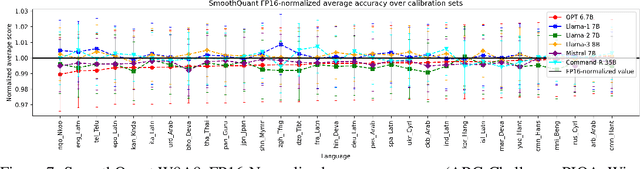
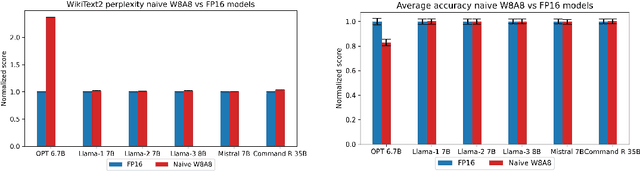
Post-Training Quantization (PTQ) enhances the efficiency of Large Language Models (LLMs) by enabling faster operation and compatibility with more accessible hardware through reduced memory usage, at the cost of small performance drops. We explore the role of calibration sets in PTQ, specifically their effect on hidden activations in various notable open-source LLMs. Calibration sets are crucial for evaluating activation magnitudes and identifying outliers, which can distort the quantization range and negatively impact performance. Our analysis reveals a marked contrast in quantization effectiveness across models. The older OPT model, upon which much of the quantization literature is based, shows significant performance deterioration and high susceptibility to outliers with varying calibration sets. In contrast, newer models like Llama-2 7B, Llama-3 8B, Command-R 35B, and Mistral 7B demonstrate strong robustness, with Mistral 7B showing near-immunity to outliers and stable activations. These findings suggest a shift in PTQ strategies might be needed. As advancements in pre-training methods reduce the relevance of outliers, there is an emerging need to reassess the fundamentals of current quantization literature. The emphasis should pivot towards optimizing inference speed, rather than primarily focusing on outlier preservation, to align with the evolving characteristics of state-of-the-art LLMs.
Multi-Agent Diagnostics for Robustness via Illuminated Diversity
Jan 24, 2024In the rapidly advancing field of multi-agent systems, ensuring robustness in unfamiliar and adversarial settings is crucial. Notwithstanding their outstanding performance in familiar environments, these systems often falter in new situations due to overfitting during the training phase. This is especially pronounced in settings where both cooperative and competitive behaviours are present, encapsulating a dual nature of overfitting and generalisation challenges. To address this issue, we present Multi-Agent Diagnostics for Robustness via Illuminated Diversity (MADRID), a novel approach for generating diverse adversarial scenarios that expose strategic vulnerabilities in pre-trained multi-agent policies. Leveraging the concepts from open-ended learning, MADRID navigates the vast space of adversarial settings, employing a target policy's regret to gauge the vulnerabilities of these settings. We evaluate the effectiveness of MADRID on the 11vs11 version of Google Research Football, one of the most complex environments for multi-agent reinforcement learning. Specifically, we employ MADRID for generating a diverse array of adversarial settings for TiZero, the state-of-the-art approach which "masters" the game through 45 days of training on a large-scale distributed infrastructure. We expose key shortcomings in TiZero's tactical decision-making, underlining the crucial importance of rigorous evaluation in multi-agent systems.