 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Agent Coordination via Sheaf-ADMM
May 29, 2026We present a differentiable optimization framework for multi-agent coordination. An input is decomposed into overlapping local views, each processed by an agent that solves a convex subproblem parameterized by a neural encoder. Agents coordinate through the Alternating Direction Method of Multipliers (ADMM) with inter-agent constraints specified by a cellular sheaf. The sheaf specifies which aspects of neighboring solutions must agree, allowing for heterogeneous notions of global consensus. Backpropagating through the unrolled optimization jointly trains all components of the multi-agent system. We evaluate on maze pathfinding, image classification, and Sudoku, where agents with individually insufficient local views learn to coordinate to produce correct global outputs. On MNIST, the local-view decomposition yields improved robustness to distribution shifts relative to a standard CNN. On Sudoku, the optimization-derived structure yields markedly higher solve rates than parameter-matched MPNN baselines. Finally, the ADMM structure exposes distinct primal, consensus, and dual state variables, opening the coordination dynamics to direct analysis and intervention -- a property unavailable in standard message-passing architectures.
Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025



Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024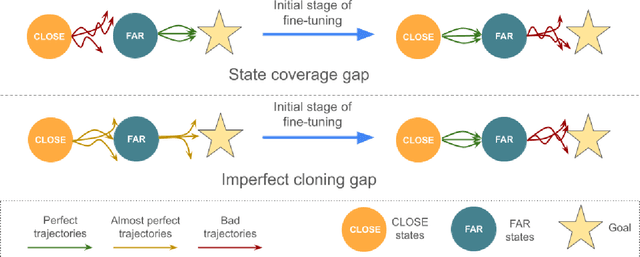
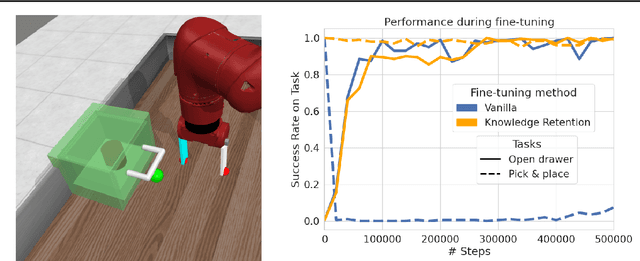
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
MeVGAN: GAN-based Plugin Model for Video Generation with Applications in Colonoscopy
Nov 07, 2023



Video generation is important, especially in medicine, as much data is given in this form. However, video generation of high-resolution data is a very demanding task for generative models, due to the large need for memory. In this paper, we propose Memory Efficient Video GAN (MeVGAN) - a Generative Adversarial Network (GAN) which uses plugin-type architecture. We use a pre-trained 2D-image GAN and only add a simple neural network to construct respective trajectories in the noise space, so that the trajectory forwarded through the GAN model constructs a real-life video. We apply MeVGAN in the task of generating colonoscopy videos. Colonoscopy is an important medical procedure, especially beneficial in screening and managing colorectal cancer. However, because colonoscopy is difficult and time-consuming to learn, colonoscopy simulators are widely used in educating young colonoscopists. We show that MeVGAN can produce good quality synthetic colonoscopy videos, which can be potentially used in virtual simulators.