 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPIC: Explanation of Pretrained Image Classification Networks via Prototype
May 19, 2025



Explainable AI (XAI) methods generally fall into two categories. Post-hoc approaches generate explanations for pre-trained models and are compatible with various neural network architectures. These methods often use feature importance visualizations, such as saliency maps, to indicate which input regions influenced the model's prediction. Unfortunately, they typically offer a coarse understanding of the model's decision-making process. In contrast, ante-hoc (inherently explainable) methods rely on specially designed model architectures trained from scratch. A notable subclass of these methods provides explanations through prototypes, representative patches extracted from the training data. However, prototype-based approaches have limitations: they require dedicated architectures, involve specialized training procedures, and perform well only on specific datasets. In this work, we propose EPIC (Explanation of Pretrained Image Classification), a novel approach that bridges the gap between these two paradigms. Like post-hoc methods, EPIC operates on pre-trained models without architectural modifications. Simultaneously, it delivers intuitive, prototype-based explanations inspired by ante-hoc techniques. To the best of our knowledge, EPIC is the first post-hoc method capable of fully replicating the core explanatory power of inherently interpretable models. We evaluate EPIC on benchmark datasets commonly used in prototype-based explanations, such as CUB-200-2011 and Stanford Cars, alongside large-scale datasets like ImageNet, typically employed by post-hoc methods. EPIC uses prototypes to explain model decisions, providing a flexible and easy-to-understand tool for creating clear, high-quality explanations.
LapSum -- One Method to Differentiate Them All: Ranking, Sorting and Top-k Selection
Mar 08, 2025



We present a novel technique for constructing differentiable order-type operations, including soft ranking, soft top-k selection, and soft permutations. Our approach leverages an efficient closed-form formula for the inverse of the function LapSum, defined as the sum of Laplace distributions. This formulation ensures low computational and memory complexity in selecting the highest activations, enabling losses and gradients to be computed in $O(n\log{}n)$ time. Through extensive experiments, we demonstrate that our method outperforms state-of-the-art techniques for high-dimensional vectors and large $k$ values. Furthermore, we provide efficient implementations for both CPU and CUDA environments, underscoring the practicality and scalability of our method for large-scale ranking and differentiable ordering problems.
SEMU: Singular Value Decomposition for Efficient Machine Unlearning
Feb 11, 2025



While the capabilities of generative foundational models have advanced rapidly in recent years, methods to prevent harmful and unsafe behaviors remain underdeveloped. Among the pressing challenges in AI safety, machine unlearning (MU) has become increasingly critical to meet upcoming safety regulations. Most existing MU approaches focus on altering the most significant parameters of the model. However, these methods often require fine-tuning substantial portions of the model, resulting in high computational costs and training instabilities, which are typically mitigated by access to the original training dataset. In this work, we address these limitations by leveraging Singular Value Decomposition (SVD) to create a compact, low-dimensional projection that enables the selective forgetting of specific data points. We propose Singular Value Decomposition for Efficient Machine Unlearning (SEMU), a novel approach designed to optimize MU in two key aspects. First, SEMU minimizes the number of model parameters that need to be modified, effectively removing unwanted knowledge while making only minimal changes to the model's weights. Second, SEMU eliminates the dependency on the original training dataset, preserving the model's previously acquired knowledge without additional data requirements. Extensive experiments demonstrate that SEMU achieves competitive performance while significantly improving efficiency in terms of both data usage and the number of modified parameters.
Tight Bounds on Jensen's Gap: Novel Approach with Applications in Generative Modeling
Feb 06, 2025Among various mathematical tools of particular interest are those that provide a common basis for researchers in different scientific fields. One of them is Jensen's inequality, which states that the expectation of a convex function is greater than or equal to the function evaluated at the expectation. The resulting difference, known as Jensen's gap, became the subject of investigation by both the statistical and machine learning communities. Among many related topics, finding lower and upper bounds on Jensen's gap (under different assumptions on the underlying function and distribution) has recently become a problem of particular interest. In our paper, we take another step in this direction by providing a novel general and mathematically rigorous technique, motivated by the recent results of Struski et al. (2023). In addition, by studying in detail the case of the logarithmic function and the log-normal distribution, we explore a method for tightly estimating the log-likelihood of generative models trained on real-world datasets. Furthermore, we present both analytical and experimental arguments in support of the superiority of our approach in comparison to existing state-of-the-art solutions, contingent upon fulfillment of the criteria set forth by theoretical studies and corresponding experiments on synthetic data.
InfoDisent: Explainability of Image Classification Models by Information Disentanglement
Sep 16, 2024

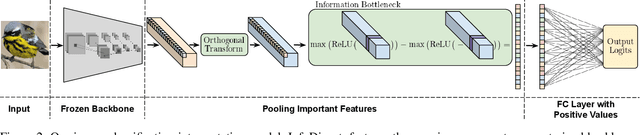

Understanding the decisions made by image classification networks is a critical area of research in deep learning. This task is traditionally divided into two distinct approaches: post-hoc methods and intrinsic methods. Post-hoc methods, such as GradCam, aim to interpret the decisions of pre-trained models by identifying regions of the image where the network focuses its attention. However, these methods provide only a high-level overview, making it difficult to fully understand the network's decision-making process. Conversely, intrinsic methods, like prototypical parts models, offer a more detailed understanding of network predictions but are constrained by specific architectures, training methods, and datasets. In this paper, we introduce InfoDisent, a hybrid model that combines the advantages of both approaches. By utilizing an information bottleneck, InfoDisent disentangles the information in the final layer of a pre-trained deep network, enabling the breakdown of classification decisions into basic, understandable atomic components. Unlike standard prototypical parts approaches, InfoDisent can interpret the decisions of pre-trained classification networks and be used for making classification decisions, similar to intrinsic models. We validate the effectiveness of InfoDisent on benchmark datasets such as ImageNet, CUB-200-2011, Stanford Cars, and Stanford Dogs for both convolutional and transformer backbones.
PrAViC: Probabilistic Adaptation Framework for Real-Time Video Classification
Jun 17, 2024Video processing is generally divided into two main categories: processing of the entire video, which typically yields optimal classification outcomes, and real-time processing, where the objective is to make a decision as promptly as possible. The latter is often driven by the need to identify rapidly potential critical or dangerous situations. These could include machine failure, traffic accidents, heart problems, or dangerous behavior. Although the models dedicated to the processing of entire videos are typically well-defined and clearly presented in the literature, this is not the case for online processing, where a plethora of hand-devised methods exist. To address this, we present \our{}, a novel, unified, and theoretically-based adaptation framework for dealing with the online classification problem for video data. The initial phase of our study is to establish a robust mathematical foundation for the theory of classification of sequential data, with the potential to make a decision at an early stage. This allows us to construct a natural function that encourages the model to return an outcome much faster. The subsequent phase is to demonstrate a straightforward and readily implementable method for adapting offline models to online and recurrent operations. Finally, by comparing the proposed approach to the non-online state-of-the-art baseline, it is demonstrated that the use of \our{} encourages the network to make earlier classification decisions without compromising accuracy.
ProPML: Probability Partial Multi-label Learning
Mar 12, 2024Partial Multi-label Learning (PML) is a type of weakly supervised learning where each training instance corresponds to a set of candidate labels, among which only some are true. In this paper, we introduce \our{}, a novel probabilistic approach to this problem that extends the binary cross entropy to the PML setup. In contrast to existing methods, it does not require suboptimal disambiguation and, as such, can be applied to any deep architecture. Furthermore, experiments conducted on artificial and real-world datasets indicate that \our{} outperforms existing approaches, especially for high noise in a candidate set.
MeVGAN: GAN-based Plugin Model for Video Generation with Applications in Colonoscopy
Nov 07, 2023



Video generation is important, especially in medicine, as much data is given in this form. However, video generation of high-resolution data is a very demanding task for generative models, due to the large need for memory. In this paper, we propose Memory Efficient Video GAN (MeVGAN) - a Generative Adversarial Network (GAN) which uses plugin-type architecture. We use a pre-trained 2D-image GAN and only add a simple neural network to construct respective trajectories in the noise space, so that the trajectory forwarded through the GAN model constructs a real-life video. We apply MeVGAN in the task of generating colonoscopy videos. Colonoscopy is an important medical procedure, especially beneficial in screening and managing colorectal cancer. However, because colonoscopy is difficult and time-consuming to learn, colonoscopy simulators are widely used in educating young colonoscopists. We show that MeVGAN can produce good quality synthetic colonoscopy videos, which can be potentially used in virtual simulators.
Interpretability Benchmark for Evaluating Spatial Misalignment of Prototypical Parts Explanations
Aug 16, 2023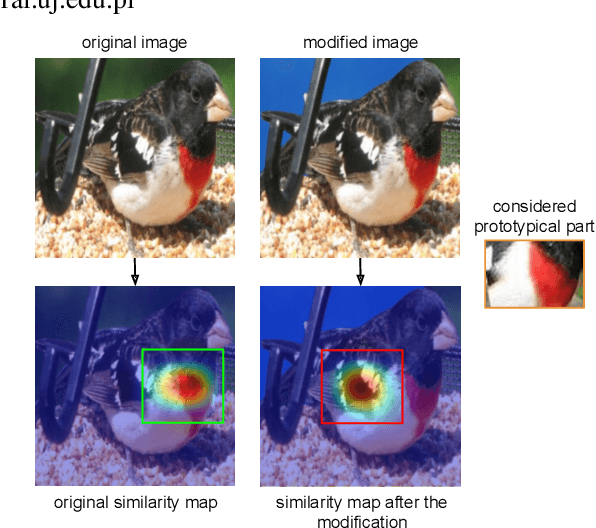
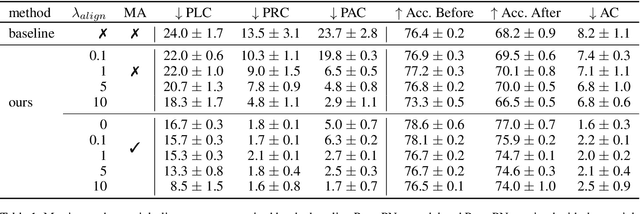
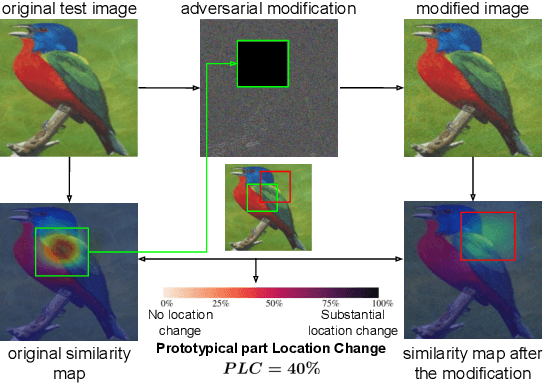

Prototypical parts-based networks are becoming increasingly popular due to their faithful self-explanations. However, their similarity maps are calculated in the penultimate network layer. Therefore, the receptive field of the prototype activation region often depends on parts of the image outside this region, which can lead to misleading interpretations. We name this undesired behavior a spatial explanation misalignment and introduce an interpretability benchmark with a set of dedicated metrics for quantifying this phenomenon. In addition, we propose a method for misalignment compensation and apply it to existing state-of-the-art models. We show the expressiveness of our benchmark and the effectiveness of the proposed compensation methodology through extensive empirical studies.
ProMIL: Probabilistic Multiple Instance Learning for Medical Imaging
Jun 18, 2023Multiple Instance Learning (MIL) is a weakly-supervised problem in which one label is assigned to the whole bag of instances. An important class of MIL models is instance-based, where we first classify instances and then aggregate those predictions to obtain a bag label. The most common MIL model is when we consider a bag as positive if at least one of its instances has a positive label. However, this reasoning does not hold in many real-life scenarios, where the positive bag label is often a consequence of a certain percentage of positive instances. To address this issue, we introduce a dedicated instance-based method called ProMIL, based on deep neural networks and Bernstein polynomial estimation. An important advantage of ProMIL is that it can automatically detect the optimal percentage level for decision-making. We show that ProMIL outperforms standard instance-based MIL in real-world medical applications. We make the code available.