 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAMOND: Directed Inference for Artifact Mitigation in Flow Matching Models
Jan 31, 2026Despite impressive results from recent text-to-image models like FLUX, visual and anatomical artifacts remain a significant hurdle for practical and professional use. Existing methods for artifact reduction, typically work in a post-hoc manner, consequently failing to intervene effectively during the core image formation process. Notably, current techniques require problematic and invasive modifications to the model weights, or depend on a computationally expensive and time-consuming process of regional refinement. To address these limitations, we propose DIAMOND, a training-free method that applies trajectory correction to mitigate artifacts during inference. By reconstructing an estimate of the clean sample at every step of the generative trajectory, DIAMOND actively steers the generation process away from latent states that lead to artifacts. Furthermore, we extend the proposed method to standard Diffusion Models, demonstrating that DIAMOND provides a robust, zero-shot path to high-fidelity, artifact-free image synthesis without the need for additional training or weight modifications in modern generative architectures. Code is available at https://gmum.github.io/DIAMOND/
EPIC: Explanation of Pretrained Image Classification Networks via Prototype
May 19, 2025Explainable AI (XAI) methods generally fall into two categories. Post-hoc approaches generate explanations for pre-trained models and are compatible with various neural network architectures. These methods often use feature importance visualizations, such as saliency maps, to indicate which input regions influenced the model's prediction. Unfortunately, they typically offer a coarse understanding of the model's decision-making process. In contrast, ante-hoc (inherently explainable) methods rely on specially designed model architectures trained from scratch. A notable subclass of these methods provides explanations through prototypes, representative patches extracted from the training data. However, prototype-based approaches have limitations: they require dedicated architectures, involve specialized training procedures, and perform well only on specific datasets. In this work, we propose EPIC (Explanation of Pretrained Image Classification), a novel approach that bridges the gap between these two paradigms. Like post-hoc methods, EPIC operates on pre-trained models without architectural modifications. Simultaneously, it delivers intuitive, prototype-based explanations inspired by ante-hoc techniques. To the best of our knowledge, EPIC is the first post-hoc method capable of fully replicating the core explanatory power of inherently interpretable models. We evaluate EPIC on benchmark datasets commonly used in prototype-based explanations, such as CUB-200-2011 and Stanford Cars, alongside large-scale datasets like ImageNet, typically employed by post-hoc methods. EPIC uses prototypes to explain model decisions, providing a flexible and easy-to-understand tool for creating clear, high-quality explanations.
ZEUS: Zero-shot Embeddings for Unsupervised Separation of Tabular Data
May 15, 2025Clustering tabular data remains a significant open challenge in data analysis and machine learning. Unlike for image data, similarity between tabular records often varies across datasets, making the definition of clusters highly dataset-dependent. Furthermore, the absence of supervised signals complicates hyperparameter tuning in deep learning clustering methods, frequently resulting in unstable performance. To address these issues and reduce the need for per-dataset tuning, we adopt an emerging approach in deep learning: zero-shot learning. We propose ZEUS, a self-contained model capable of clustering new datasets without any additional training or fine-tuning. It operates by decomposing complex datasets into meaningful components that can then be clustered effectively. Thanks to pre-training on synthetic datasets generated from a latent-variable prior, it generalizes across various datasets without requiring user intervention. To the best of our knowledge, ZEUS is the first zero-shot method capable of generating embeddings for tabular data in a fully unsupervised manner. Experimental results demonstrate that it performs on par with or better than traditional clustering algorithms and recent deep learning-based methods, while being significantly faster and more user-friendly.
CEC-MMR: Cross-Entropy Clustering Approach to Multi-Modal Regression
Apr 09, 2025In practical applications of regression analysis, it is not uncommon to encounter a multitude of values for each attribute. In such a situation, the univariate distribution, which is typically Gaussian, is suboptimal because the mean may be situated between modes, resulting in a predicted value that differs significantly from the actual data. Consequently, to address this issue, a mixture distribution with parameters learned by a neural network, known as a Mixture Density Network (MDN), is typically employed. However, this approach has an important inherent limitation, in that it is not feasible to ascertain the precise number of components with a reasonable degree of accuracy. In this paper, we introduce CEC-MMR, a novel approach based on Cross-Entropy Clustering (CEC), which allows for the automatic detection of the number of components in a regression problem. Furthermore, given an attribute and its value, our method is capable of uniquely identifying it with the underlying component. The experimental results demonstrate that CEC-MMR yields superior outcomes compared to classical MDNs.
FeNeC: Enhancing Continual Learning via Feature Clustering with Neighbor- or Logit-Based Classification
Mar 18, 2025The ability of deep learning models to learn continuously is essential for adapting to new data categories and evolving data distributions. In recent years, approaches leveraging frozen feature extractors after an initial learning phase have been extensively studied. Many of these methods estimate per-class covariance matrices and prototypes based on backbone-derived feature representations. Within this paradigm, we introduce FeNeC (Feature Neighborhood Classifier) and FeNeC-Log, its variant based on the log-likelihood function. Our approach generalizes the existing concept by incorporating data clustering to capture greater intra-class variability. Utilizing the Mahalanobis distance, our models classify samples either through a nearest neighbor approach or trainable logit values assigned to consecutive classes. Our proposition may be reduced to the existing approaches in a special case while extending them with the ability of more flexible adaptation to data. We demonstrate that two FeNeC variants achieve competitive performance in scenarios where task identities are unknown and establish state-of-the-art results on several benchmarks.
LapSum -- One Method to Differentiate Them All: Ranking, Sorting and Top-k Selection
Mar 08, 2025We present a novel technique for constructing differentiable order-type operations, including soft ranking, soft top-k selection, and soft permutations. Our approach leverages an efficient closed-form formula for the inverse of the function LapSum, defined as the sum of Laplace distributions. This formulation ensures low computational and memory complexity in selecting the highest activations, enabling losses and gradients to be computed in $O(n\log{}n)$ time. Through extensive experiments, we demonstrate that our method outperforms state-of-the-art techniques for high-dimensional vectors and large $k$ values. Furthermore, we provide efficient implementations for both CPU and CUDA environments, underscoring the practicality and scalability of our method for large-scale ranking and differentiable ordering problems.
Minimal Ranks, Maximum Confidence: Parameter-efficient Uncertainty Quantification for LoRA
Feb 17, 2025Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning of large language models by decomposing weight updates into low-rank matrices, significantly reducing storage and computational overhead. While effective, standard LoRA lacks mechanisms for uncertainty quantification, leading to overconfident and poorly calibrated models. Bayesian variants of LoRA address this limitation, but at the cost of a significantly increased number of trainable parameters, partially offsetting the original efficiency gains. Additionally, these models are harder to train and may suffer from unstable convergence. In this work, we propose a novel parameter-efficient Bayesian LoRA, demonstrating that effective uncertainty quantification can be achieved in very low-dimensional parameter spaces. The proposed method achieves strong performance with improved calibration and generalization while maintaining computational efficiency. Our empirical findings show that, with the appropriate projection of the weight space: (1) uncertainty can be effectively modeled in a low-dimensional space, and (2) weight covariances exhibit low ranks.
SEMU: Singular Value Decomposition for Efficient Machine Unlearning
Feb 11, 2025While the capabilities of generative foundational models have advanced rapidly in recent years, methods to prevent harmful and unsafe behaviors remain underdeveloped. Among the pressing challenges in AI safety, machine unlearning (MU) has become increasingly critical to meet upcoming safety regulations. Most existing MU approaches focus on altering the most significant parameters of the model. However, these methods often require fine-tuning substantial portions of the model, resulting in high computational costs and training instabilities, which are typically mitigated by access to the original training dataset. In this work, we address these limitations by leveraging Singular Value Decomposition (SVD) to create a compact, low-dimensional projection that enables the selective forgetting of specific data points. We propose Singular Value Decomposition for Efficient Machine Unlearning (SEMU), a novel approach designed to optimize MU in two key aspects. First, SEMU minimizes the number of model parameters that need to be modified, effectively removing unwanted knowledge while making only minimal changes to the model's weights. Second, SEMU eliminates the dependency on the original training dataset, preserving the model's previously acquired knowledge without additional data requirements. Extensive experiments demonstrate that SEMU achieves competitive performance while significantly improving efficiency in terms of both data usage and the number of modified parameters.
RaySplats: Ray Tracing based Gaussian Splatting
Jan 31, 2025
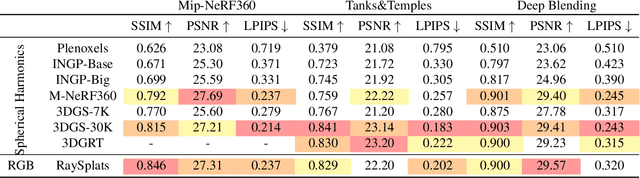
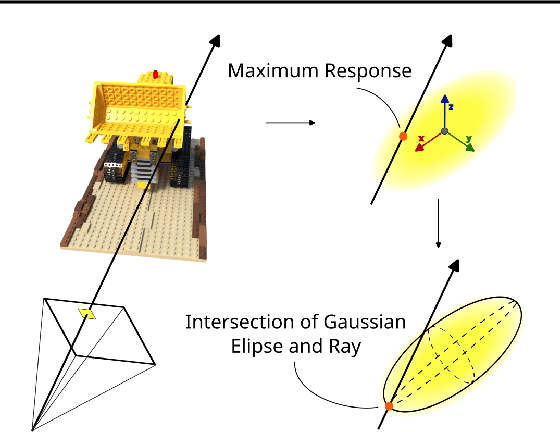

3D Gaussian Splatting (3DGS) is a process that enables the direct creation of 3D objects from 2D images. This representation offers numerous advantages, including rapid training and rendering. However, a significant limitation of 3DGS is the challenge of incorporating light and shadow reflections, primarily due to the utilization of rasterization rather than ray tracing for rendering. This paper introduces RaySplats, a model that employs ray-tracing based Gaussian Splatting. Rather than utilizing the projection of Gaussians, our method employs a ray-tracing mechanism, operating directly on Gaussian primitives represented by confidence ellipses with RGB colors. In practice, we compute the intersection between ellipses and rays to construct ray-tracing algorithms, facilitating the incorporation of meshes with Gaussian Splatting models and the addition of lights, shadows, and other related effects.
VisTabNet: Adapting Vision Transformers for Tabular Data
Dec 28, 2024Although deep learning models have had great success in natural language processing and computer vision, we do not observe comparable improvements in the case of tabular data, which is still the most common data type used in biological, industrial and financial applications. In particular, it is challenging to transfer large-scale pre-trained models to downstream tasks defined on small tabular datasets. To address this, we propose VisTabNet -- a cross-modal transfer learning method, which allows for adapting Vision Transformer (ViT) with pre-trained weights to process tabular data. By projecting tabular inputs to patch embeddings acceptable by ViT, we can directly apply a pre-trained Transformer Encoder to tabular inputs. This approach eliminates the conceptual cost of designing a suitable architecture for processing tabular data, while reducing the computational cost of training the model from scratch. Experimental results on multiple small tabular datasets (less than 1k samples) demonstrate VisTabNet's superiority, outperforming both traditional ensemble methods and recent deep learning models. The proposed method goes beyond conventional transfer learning practice and shows that pre-trained image models can be transferred to solve tabular problems, extending the boundaries of transfer learning.