 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleAutoEncoder for manipulating image attributes using pre-trained StyleGAN
Dec 28, 2024Deep conditional generative models are excellent tools for creating high-quality images and editing their attributes. However, training modern generative models from scratch is very expensive and requires large computational resources. In this paper, we introduce StyleAutoEncoder (StyleAE), a lightweight AutoEncoder module, which works as a plugin for pre-trained generative models and allows for manipulating the requested attributes of images. The proposed method offers a cost-effective solution for training deep generative models with limited computational resources, making it a promising technique for a wide range of applications. We evaluate StyleAutoEncoder by combining it with StyleGAN, which is currently one of the top generative models. Our experiments demonstrate that StyleAutoEncoder is at least as effective in manipulating image attributes as the state-of-the-art algorithms based on invertible normalizing flows. However, it is simpler, faster, and gives more freedom in designing neural
Non-Gaussian Gaussian Processes for Few-Shot Regression
Oct 26, 2021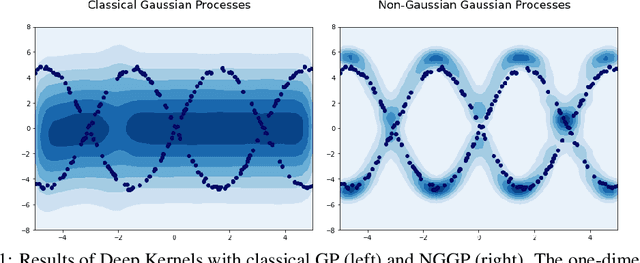
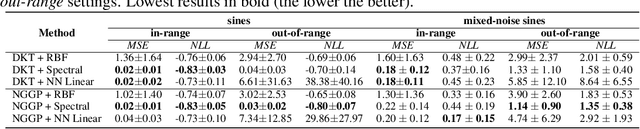
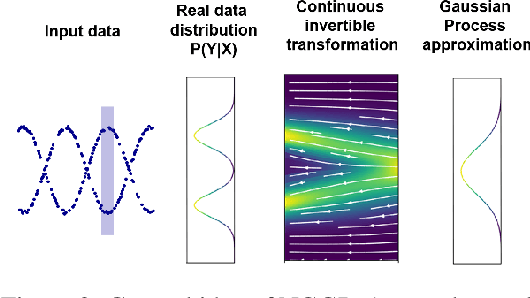
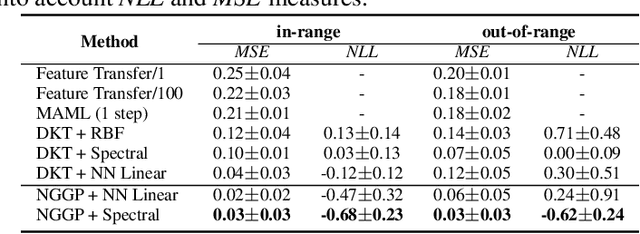
Gaussian Processes (GPs) have been widely used in machine learning to model distributions over functions, with applications including multi-modal regression, time-series prediction, and few-shot learning. GPs are particularly useful in the last application since they rely on Normal distributions and enable closed-form computation of the posterior probability function. Unfortunately, because the resulting posterior is not flexible enough to capture complex distributions, GPs assume high similarity between subsequent tasks - a requirement rarely met in real-world conditions. In this work, we address this limitation by leveraging the flexibility of Normalizing Flows to modulate the posterior predictive distribution of the GP. This makes the GP posterior locally non-Gaussian, therefore we name our method Non-Gaussian Gaussian Processes (NGGPs). More precisely, we propose an invertible ODE-based mapping that operates on each component of the random variable vectors and shares the parameters across all of them. We empirically tested the flexibility of NGGPs on various few-shot learning regression datasets, showing that the mapping can incorporate context embedding information to model different noise levels for periodic functions. As a result, our method shares the structure of the problem between subsequent tasks, but the contextualization allows for adaptation to dissimilarities. NGGPs outperform the competing state-of-the-art approaches on a diversified set of benchmarks and applications.
On the relationship between disentanglement and multi-task learning
Oct 07, 2021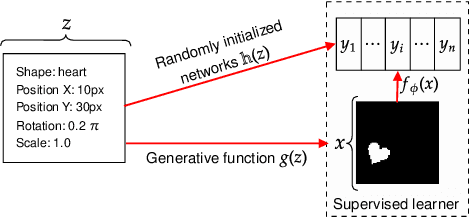

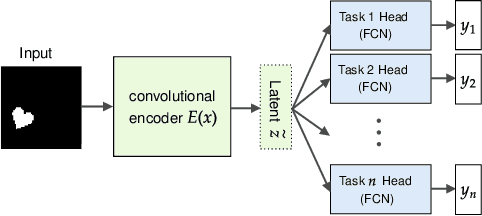
One of the main arguments behind studying disentangled representations is the assumption that they can be easily reused in different tasks. At the same time finding a joint, adaptable representation of data is one of the key challenges in the multi-task learning setting. In this paper, we take a closer look at the relationship between disentanglement and multi-task learning based on hard parameter sharing. We perform a thorough empirical study of the representations obtained by neural networks trained on automatically generated supervised tasks. Using a set of standard metrics we show that disentanglement appears naturally during the process of multi-task neural network training.
WICA: nonlinear weighted ICA
Jan 13, 2020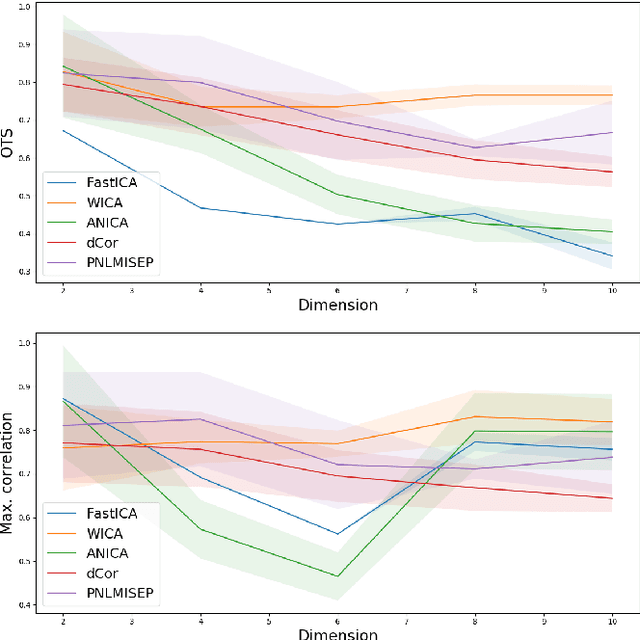
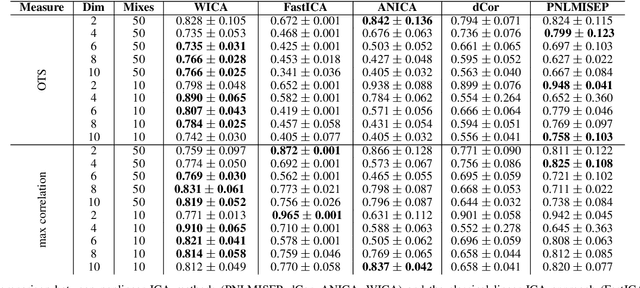

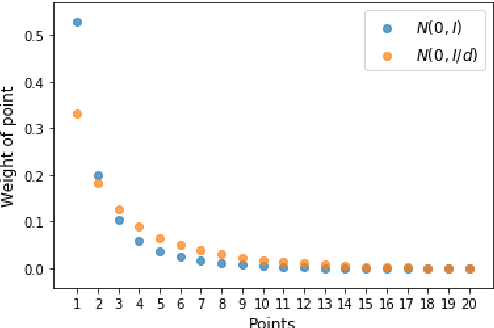
Independent Component Analysis (ICA) aims to find a coordinate system in which the components of the data are independent. In this paper we construct a new nonlinear ICA model, called WICA, which obtains better and more stable results than other algorithms. A crucial tool is given by a new efficient method of verifying nonlinear dependence with the use of computation of correlation coefficients for normally weighted data.
Independent Component Analysis based on multiple data-weighting
May 31, 2019
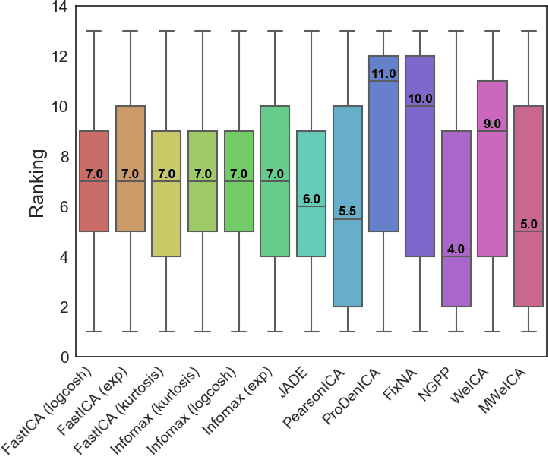
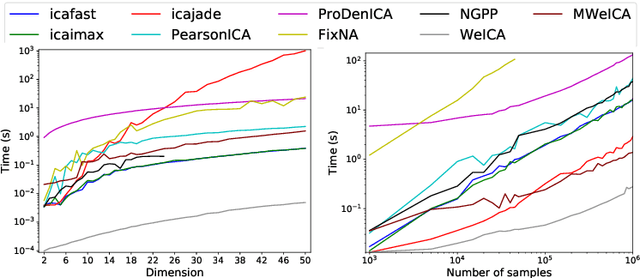
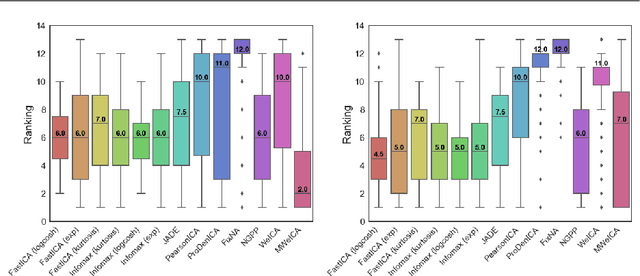
Independent Component Analysis (ICA) - one of the basic tools in data analysis - aims to find a coordinate system in which the components of the data are independent. In this paper we present Multiple-weighted Independent Component Analysis (MWeICA) algorithm, a new ICA method which is based on approximate diagonalization of weighted covariance matrices. Our idea is based on theoretical result, which says that linear independence of weighted data (for gaussian weights) guarantees independence. Experiments show that MWeICA achieves better results to most state-of-the-art ICA methods, with similar computational time.