 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOL: Transductive Few-Shot Open-Set Recognition by Enhancing Outlier Logits
Aug 04, 2024



In Few-Shot Learning (FSL), models are trained to recognise unseen objects from a query set, given a few labelled examples from a support set. In standard FSL, models are evaluated on query instances sampled from the same class distribution of the support set. In this work, we explore the more nuanced and practical challenge of Open-Set Few-Shot Recognition (OSFSL). Unlike standard FSL, OSFSL incorporates unknown classes into the query set, thereby requiring the model not only to classify known classes but also to identify outliers. Building on the groundwork laid by previous studies, we define a novel transductive inference technique that leverages the InfoMax principle to exploit the unlabelled query set. We called our approach the Enhanced Outlier Logit (EOL) method. EOL refines class prototype representations through model calibration, effectively balancing the inlier-outlier ratio. This calibration enhances pseudo-label accuracy for the query set and improves the optimisation objective within the transductive inference process. We provide a comprehensive empirical evaluation demonstrating that EOL consistently surpasses traditional methods, recording performance improvements ranging from approximately $+1.3%$ to $+6.3%$ across a variety of classification and outlier detection metrics and benchmarks, even in the presence of inlier-outlier imbalance.
Transformer Neural Autoregressive Flows
Jan 03, 2024



Density estimation, a central problem in machine learning, can be performed using Normalizing Flows (NFs). NFs comprise a sequence of invertible transformations, that turn a complex target distribution into a simple one, by exploiting the change of variables theorem. Neural Autoregressive Flows (NAFs) and Block Neural Autoregressive Flows (B-NAFs) are arguably the most perfomant members of the NF family. However, they suffer scalability issues and training instability due to the constraints imposed on the network structure. In this paper, we propose a novel solution to these challenges by exploiting transformers to define a new class of neural flows called Transformer Neural Autoregressive Flows (T-NAFs). T-NAFs treat each dimension of a random variable as a separate input token, using attention masking to enforce an autoregressive constraint. We take an amortization-inspired approach where the transformer outputs the parameters of an invertible transformation. The experimental results demonstrate that T-NAFs consistently match or outperform NAFs and B-NAFs across multiple datasets from the UCI benchmark. Remarkably, T-NAFs achieve these results using an order of magnitude fewer parameters than previous approaches, without composing multiple flows.
Comparing the Efficacy of Fine-Tuning and Meta-Learning for Few-Shot Policy Imitation
Jun 23, 2023In this paper we explore few-shot imitation learning for control problems, which involves learning to imitate a target policy by accessing a limited set of offline rollouts. This setting has been relatively under-explored despite its relevance to robotics and control applications. State-of-the-art methods developed to tackle few-shot imitation rely on meta-learning, which is expensive to train as it requires access to a distribution over tasks (rollouts from many target policies and variations of the base environment). Given this limitation we investigate an alternative approach, fine-tuning, a family of methods that pretrain on a single dataset and then fine-tune on unseen domain-specific data. Recent work has shown that fine-tuners outperform meta-learners in few-shot image classification tasks, especially when the data is out-of-domain. Here we evaluate to what extent this is true for control problems, proposing a simple yet effective baseline which relies on two stages: (i) training a base policy online via reinforcement learning (e.g. Soft Actor-Critic) on a single base environment, (ii) fine-tuning the base policy via behavioral cloning on a few offline rollouts of the target policy. Despite its simplicity this baseline is competitive with meta-learning methods on a variety of conditions and is able to imitate target policies trained on unseen variations of the original environment. Importantly, the proposed approach is practical and easy to implement, as it does not need any complex meta-training protocol. As a further contribution, we release an open source dataset called iMuJoCo (iMitation MuJoCo) consisting of 154 variants of popular OpenAI-Gym MuJoCo environments with associated pretrained target policies and rollouts, which can be used by the community to study few-shot imitation learning and offline reinforcement learning.
Contextual Squeeze-and-Excitation for Efficient Few-Shot Image Classification
Jun 20, 2022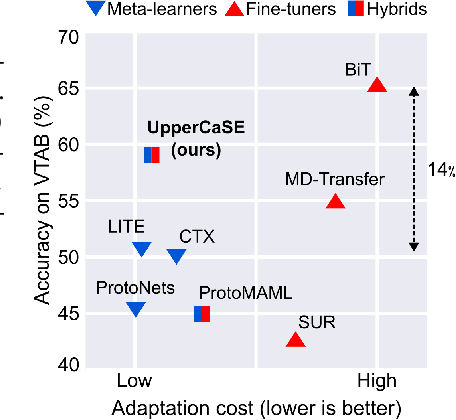
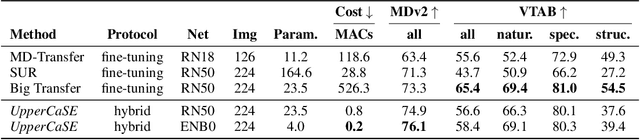
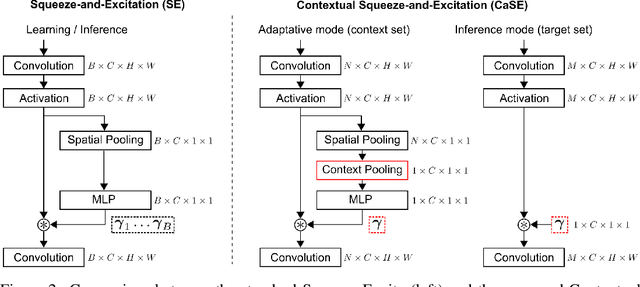
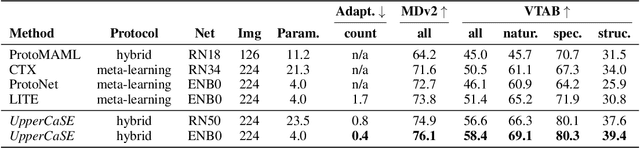
Recent years have seen a growth in user-centric applications that require effective knowledge transfer across tasks in the low-data regime. An example is personalization, where a pretrained system is adapted by learning on small amounts of labeled data belonging to a specific user. This setting requires high accuracy under low computational complexity, therefore the Pareto frontier of accuracy vs.~adaptation cost plays a crucial role. In this paper we push this Pareto frontier in the few-shot image classification setting with two key contributions: (i) a new adaptive block called Contextual Squeeze-and-Excitation (CaSE) that adjusts a pretrained neural network on a new task to significantly improve performance with a single forward pass of the user data (context), and (ii) a hybrid training protocol based on Coordinate-Descent called UpperCaSE that exploits meta-trained CaSE blocks and fine-tuning routines for efficient adaptation. UpperCaSE achieves a new state-of-the-art accuracy relative to meta-learners on the 26 datasets of VTAB+MD and on a challenging real-world personalization benchmark (ORBIT), narrowing the gap with leading fine-tuning methods with the benefit of orders of magnitude lower adaptation cost.
FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification
Jun 17, 2022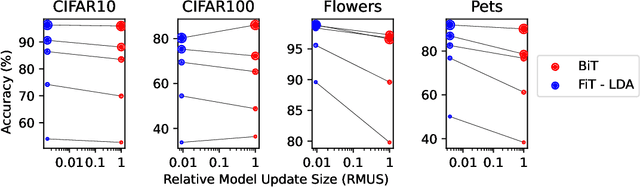
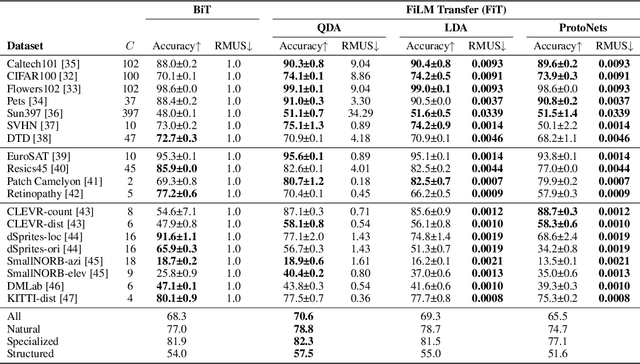

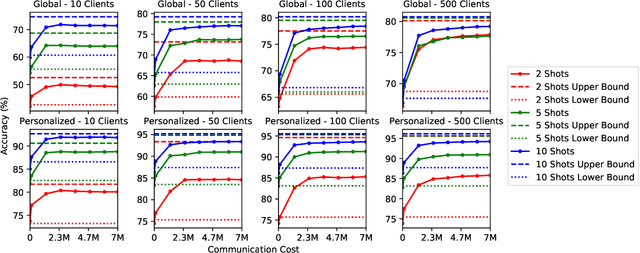
Modern deep learning systems are increasingly deployed in situations such as personalization and federated learning where it is necessary to support i) learning on small amounts of data, and ii) communication efficient distributed training protocols. In this work we develop FiLM Transfer (FiT) which fulfills these requirements in the image classification setting. FiT uses an automatically configured Naive Bayes classifier on top of a fixed backbone that has been pretrained on large image datasets. Parameter efficient FiLM layers are used to modulate the backbone, shaping the representation for the downstream task. The network is trained via an episodic fine-tuning protocol. The approach is parameter efficient which is key for enabling few-shot learning, inexpensive model updates for personalization, and communication efficient federated learning. We experiment with FiT on a wide range of downstream datasets and show that it achieves better classification accuracy than the state-of-the-art Big Transfer (BiT) algorithm at low-shot and on the challenging VTAB-1k benchmark, with fewer than 1% of the updateable parameters. Finally, we demonstrate the parameter efficiency of FiT in distributed low-shot applications including model personalization and federated learning where model update size is an important performance metric.
Non-Gaussian Gaussian Processes for Few-Shot Regression
Oct 26, 2021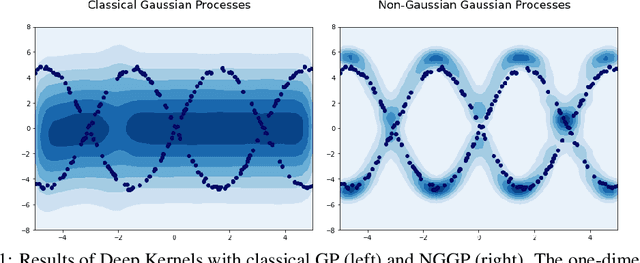
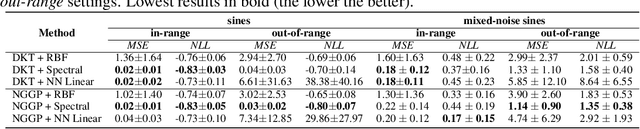
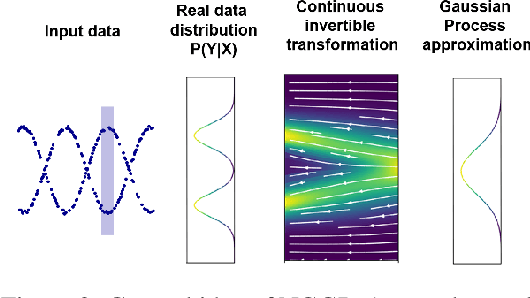
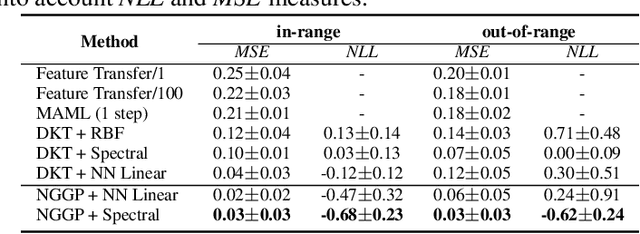
Gaussian Processes (GPs) have been widely used in machine learning to model distributions over functions, with applications including multi-modal regression, time-series prediction, and few-shot learning. GPs are particularly useful in the last application since they rely on Normal distributions and enable closed-form computation of the posterior probability function. Unfortunately, because the resulting posterior is not flexible enough to capture complex distributions, GPs assume high similarity between subsequent tasks - a requirement rarely met in real-world conditions. In this work, we address this limitation by leveraging the flexibility of Normalizing Flows to modulate the posterior predictive distribution of the GP. This makes the GP posterior locally non-Gaussian, therefore we name our method Non-Gaussian Gaussian Processes (NGGPs). More precisely, we propose an invertible ODE-based mapping that operates on each component of the random variable vectors and shares the parameters across all of them. We empirically tested the flexibility of NGGPs on various few-shot learning regression datasets, showing that the mapping can incorporate context embedding information to model different noise levels for periodic functions. As a result, our method shares the structure of the problem between subsequent tasks, but the contextualization allows for adaptation to dissimilarities. NGGPs outperform the competing state-of-the-art approaches on a diversified set of benchmarks and applications.
Memory Efficient Meta-Learning with Large Images
Jul 02, 2021
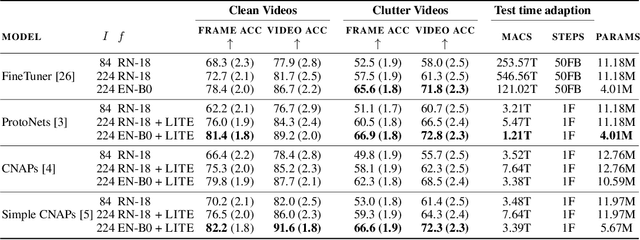
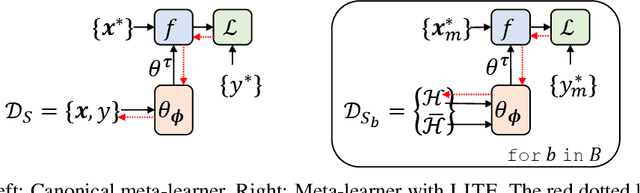
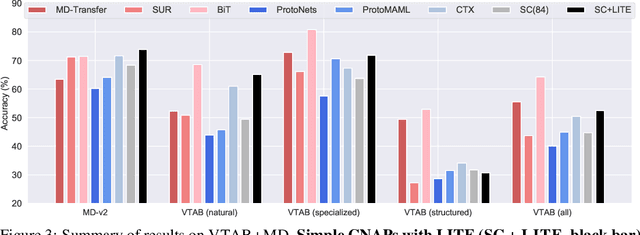
Meta learning approaches to few-shot classification are computationally efficient at test time requiring just a few optimization steps or single forward pass to learn a new task, but they remain highly memory-intensive to train. This limitation arises because a task's entire support set, which can contain up to 1000 images, must be processed before an optimization step can be taken. Harnessing the performance gains offered by large images thus requires either parallelizing the meta-learner across multiple GPUs, which may not be available, or trade-offs between task and image size when memory constraints apply. We improve on both options by proposing LITE, a general and memory efficient episodic training scheme that enables meta-training on large tasks composed of large images on a single GPU. We achieve this by observing that the gradients for a task can be decomposed into a sum of gradients over the task's training images. This enables us to perform a forward pass on a task's entire training set but realize significant memory savings by back-propagating only a random subset of these images which we show is an unbiased approximation of the full gradient. We use LITE to train meta-learners and demonstrate new state-of-the-art accuracy on the real-world ORBIT benchmark and 3 of the 4 parts of the challenging VTAB+MD benchmark relative to leading meta-learners. LITE also enables meta-learners to be competitive with transfer learning approaches but at a fraction of the test-time computational cost, thus serving as a counterpoint to the recent narrative that transfer learning is all you need for few-shot classification.
How Sensitive are Meta-Learners to Dataset Imbalance?
Apr 12, 2021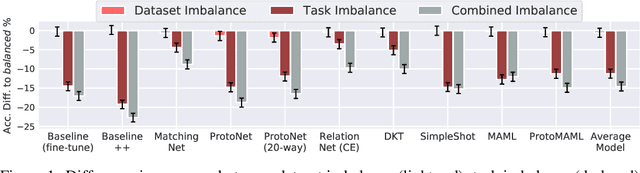
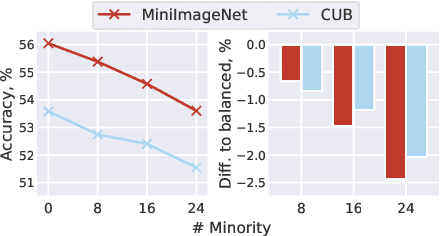
Meta-Learning (ML) has proven to be a useful tool for training Few-Shot Learning (FSL) algorithms by exposure to batches of tasks sampled from a meta-dataset. However, the standard training procedure overlooks the dynamic nature of the real-world where object classes are likely to occur at different frequencies. While it is generally understood that imbalanced tasks harm the performance of supervised methods, there is no significant research examining the impact of imbalanced meta-datasets on the FSL evaluation task. This study exposes the magnitude and extent of this problem. Our results show that ML methods are more robust against meta-dataset imbalance than imbalance at the task-level with a similar imbalance ratio ($\rho<20$), with the effect holding even in long-tail datasets under a larger imbalance ($\rho=65$). Overall, these results highlight an implicit strength of ML algorithms, capable of learning generalizable features under dataset imbalance and domain-shift. The code to reproduce the experiments is released under an open-source license.
Few-Shot Learning with Class Imbalance
Jan 07, 2021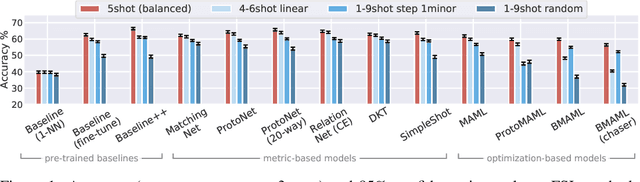
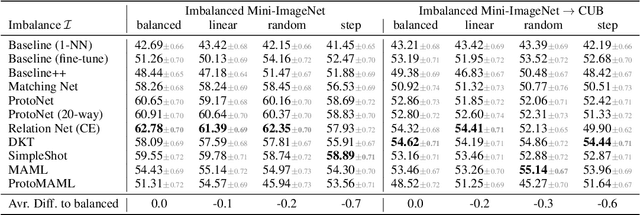
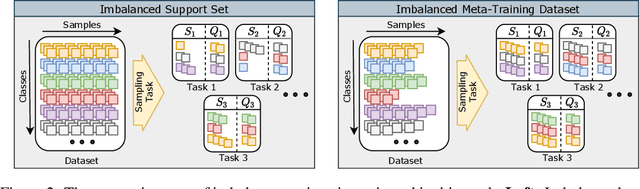
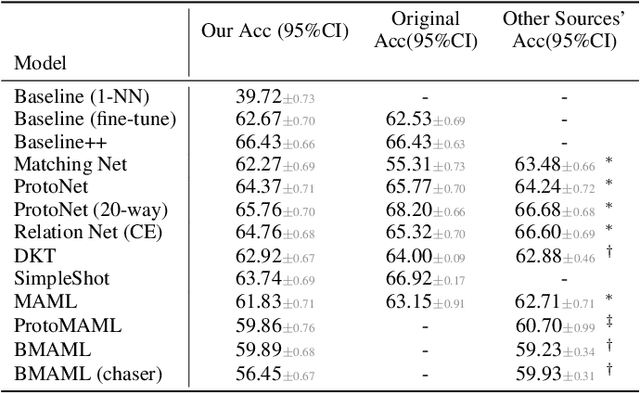
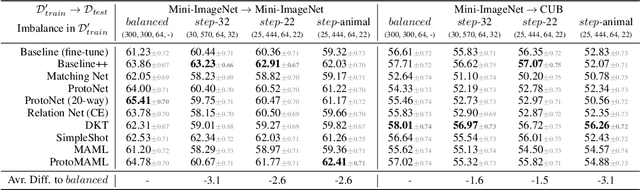
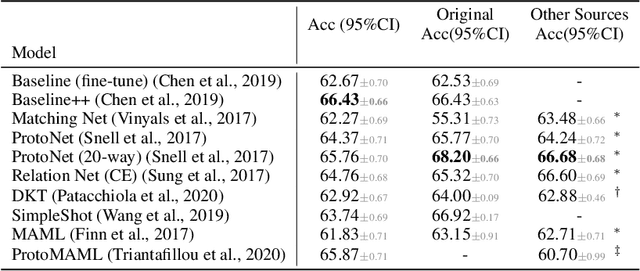
Few-shot learning aims to train models on a limited number of labeled samples given in a support set in order to generalize to unseen samples from a query set. In the standard setup, the support set contains an equal amount of data points for each class. However, this assumption overlooks many practical considerations arising from the dynamic nature of the real world, such as class-imbalance. In this paper, we present a detailed study of few-shot class-imbalance along three axes: meta-dataset vs. task imbalance, effect of different imbalance distributions (linear, step, random), and effect of rebalancing techniques. We extensively compare over 10 state-of-the-art few-shot learning and meta-learning methods using unbalanced tasks and meta-datasets. Our analysis using Mini-ImageNet reveals that 1) compared to the balanced task, the performances on class-imbalance tasks counterparts always drop, by up to $18.0\%$ for optimization-based methods, and up to $8.4$ for metric-based methods, 2) contrary to popular belief, meta-learning algorithms, such as MAML, do not automatically learn to balance by being exposed to imbalanced tasks during (meta-)training time, 3) strategies used to mitigate imbalance in supervised learning, such as oversampling, can offer a stronger solution to the class imbalance problem, 4) the effect of imbalance at the meta-dataset level is less significant than the effect at the task level with similar imbalance magnitude. The code to reproduce the experiments is released under an open-source license.
Self-Supervised Relational Reasoning for Representation Learning
Jun 10, 2020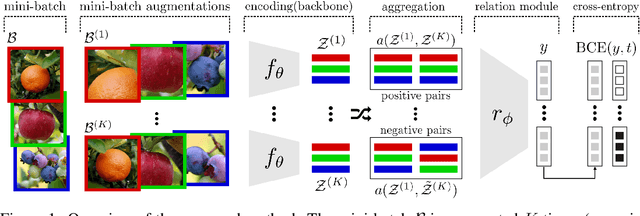
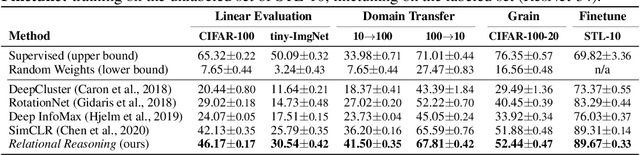
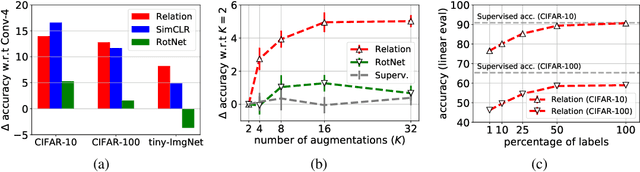

In self-supervised learning, a system is tasked with achieving a surrogate objective by defining alternative targets on a set of unlabeled data. The aim is to build useful representations that can be used in downstream tasks, without costly manual annotation. In this work, we propose a novel self-supervised formulation of relational reasoning that allows a learner to bootstrap a signal from information implicit in unlabeled data. Training a relation head to discriminate how entities relate to themselves (intra-reasoning) and other entities (inter-reasoning), results in rich and descriptive representations in the underlying neural network backbone, which can be used in downstream tasks such as classification and image retrieval. We evaluate the proposed method following a rigorous experimental procedure, using standard datasets, protocols, and backbones. Self-supervised relational reasoning outperforms the best competitor in all conditions by an average 14% in accuracy, and the most recent state-of-the-art model by 3%. We link the effectiveness of the method to the maximization of a Bernoulli log-likelihood, which can be considered as a proxy for maximizing the mutual information, resulting in a more efficient objective with respect to the commonly used contrastive losses.