 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOL: Transductive Few-Shot Open-Set Recognition by Enhancing Outlier Logits
Aug 04, 2024



In Few-Shot Learning (FSL), models are trained to recognise unseen objects from a query set, given a few labelled examples from a support set. In standard FSL, models are evaluated on query instances sampled from the same class distribution of the support set. In this work, we explore the more nuanced and practical challenge of Open-Set Few-Shot Recognition (OSFSL). Unlike standard FSL, OSFSL incorporates unknown classes into the query set, thereby requiring the model not only to classify known classes but also to identify outliers. Building on the groundwork laid by previous studies, we define a novel transductive inference technique that leverages the InfoMax principle to exploit the unlabelled query set. We called our approach the Enhanced Outlier Logit (EOL) method. EOL refines class prototype representations through model calibration, effectively balancing the inlier-outlier ratio. This calibration enhances pseudo-label accuracy for the query set and improves the optimisation objective within the transductive inference process. We provide a comprehensive empirical evaluation demonstrating that EOL consistently surpasses traditional methods, recording performance improvements ranging from approximately $+1.3%$ to $+6.3%$ across a variety of classification and outlier detection metrics and benchmarks, even in the presence of inlier-outlier imbalance.
Prediction-Guided Distillation for Dense Object Detection
Mar 10, 2022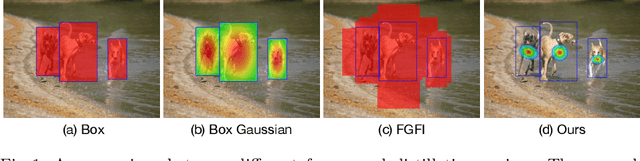
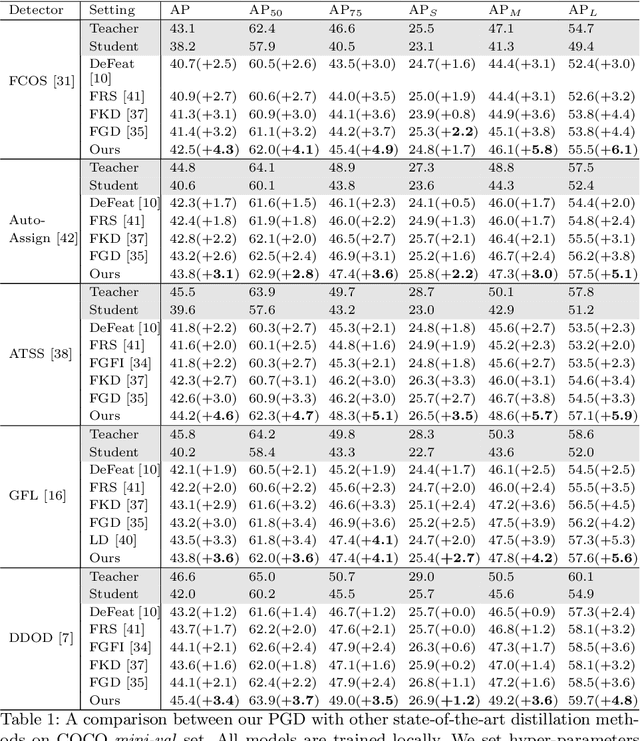

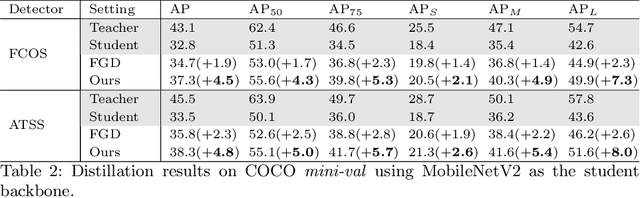
Real-world object detection models should be cheap and accurate. Knowledge distillation (KD) can boost the accuracy of a small, cheap detection model by leveraging useful information from a larger teacher model. However, a key challenge is identifying the most informative features produced by the teacher for distillation. In this work, we show that only a very small fraction of features within a ground-truth bounding box are responsible for a teacher's high detection performance. Based on this, we propose Prediction-Guided Distillation (PGD), which focuses distillation on these key predictive regions of the teacher and yields considerable gains in performance over many existing KD baselines. In addition, we propose an adaptive weighting scheme over the key regions to smooth out their influence and achieve even better performance. Our proposed approach outperforms current state-of-the-art KD baselines on a variety of advanced one-stage detection architectures. Specifically, on the COCO dataset, our method achieves between +3.1% and +4.6% AP improvement using ResNet-101 and ResNet-50 as the teacher and student backbones, respectively. On the CrowdHuman dataset, we achieve +3.2% and +2.0% improvements in MR and AP, also using these backbones. Our code is available at https://github.com/ChenhongyiYang/PGD.
How Sensitive are Meta-Learners to Dataset Imbalance?
Apr 12, 2021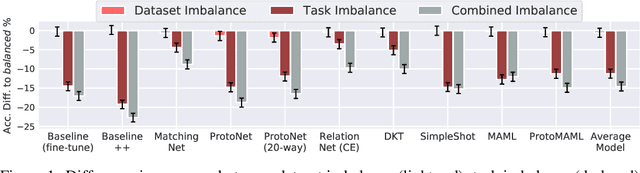
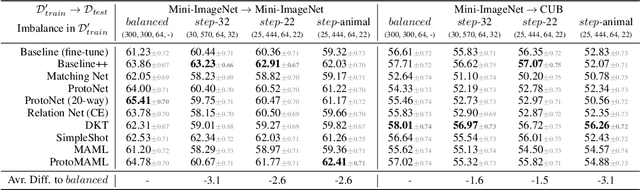
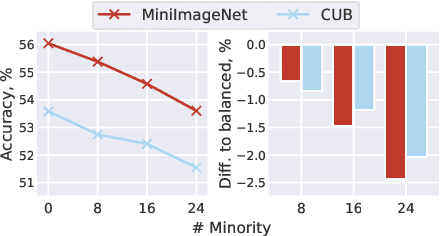
Meta-Learning (ML) has proven to be a useful tool for training Few-Shot Learning (FSL) algorithms by exposure to batches of tasks sampled from a meta-dataset. However, the standard training procedure overlooks the dynamic nature of the real-world where object classes are likely to occur at different frequencies. While it is generally understood that imbalanced tasks harm the performance of supervised methods, there is no significant research examining the impact of imbalanced meta-datasets on the FSL evaluation task. This study exposes the magnitude and extent of this problem. Our results show that ML methods are more robust against meta-dataset imbalance than imbalance at the task-level with a similar imbalance ratio ($\rho<20$), with the effect holding even in long-tail datasets under a larger imbalance ($\rho=65$). Overall, these results highlight an implicit strength of ML algorithms, capable of learning generalizable features under dataset imbalance and domain-shift. The code to reproduce the experiments is released under an open-source license.
Few-Shot Learning with Class Imbalance
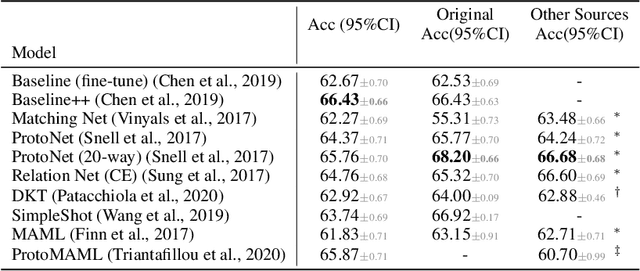
Jan 07, 2021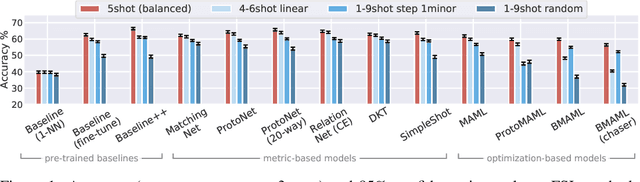
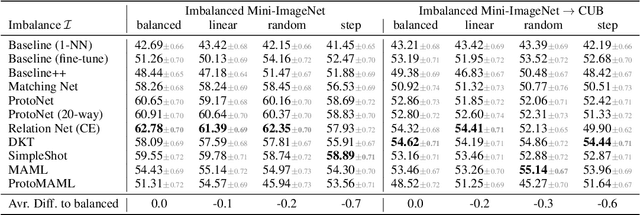
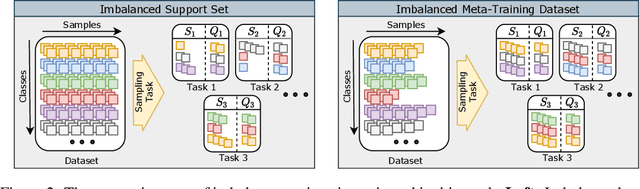
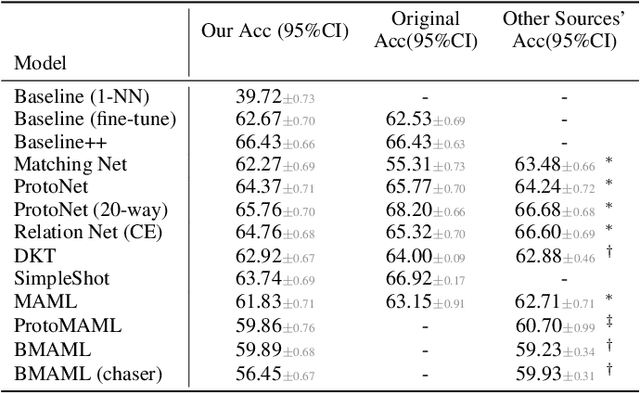
Few-shot learning aims to train models on a limited number of labeled samples given in a support set in order to generalize to unseen samples from a query set. In the standard setup, the support set contains an equal amount of data points for each class. However, this assumption overlooks many practical considerations arising from the dynamic nature of the real world, such as class-imbalance. In this paper, we present a detailed study of few-shot class-imbalance along three axes: meta-dataset vs. task imbalance, effect of different imbalance distributions (linear, step, random), and effect of rebalancing techniques. We extensively compare over 10 state-of-the-art few-shot learning and meta-learning methods using unbalanced tasks and meta-datasets. Our analysis using Mini-ImageNet reveals that 1) compared to the balanced task, the performances on class-imbalance tasks counterparts always drop, by up to $18.0\%$ for optimization-based methods, and up to $8.4$ for metric-based methods, 2) contrary to popular belief, meta-learning algorithms, such as MAML, do not automatically learn to balance by being exposed to imbalanced tasks during (meta-)training time, 3) strategies used to mitigate imbalance in supervised learning, such as oversampling, can offer a stronger solution to the class imbalance problem, 4) the effect of imbalance at the meta-dataset level is less significant than the effect at the task level with similar imbalance magnitude. The code to reproduce the experiments is released under an open-source license.
A Comparison of Few-Shot Learning Methods for Underwater Optical and Sonar Image Classification
May 10, 2020
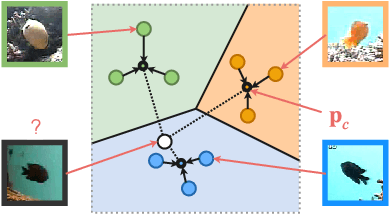
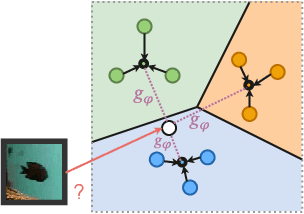
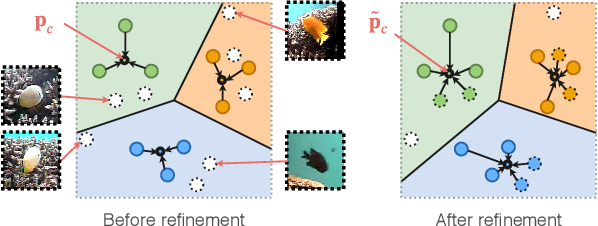
Deep convolutional neural networks have shown to perform well in underwater object recognition tasks, on both optical and sonar images. However, many such methods require hundreds, if not thousands, of images per class to generalize well to unseen examples. This is restricting in situations where obtaining and labeling larger volumes of data is impractical, such as observing a rare object, performing real-time operations, or operating in new underwater environments. Finding an algorithm capable of learning from only a few samples could reduce the time spent obtaining and labeling datasets, and accelerate the training of deep-learning models. To the best of our knowledge, this is the first paper to evaluate and compare several Few-Shot Learning (FSL) methods using underwater optical and side-scan sonar imagery. Our results show that FSL methods offer a significant advantage over the traditional transfer learning methods that employ fine-tuning of pre-trained models. Our findings show that FSL methods are not too far from being used on real-world robotics scenarios and expanding the capabilities of autonomous underwater systems.
Defining Benchmarks for Continual Few-Shot Learning
Apr 15, 2020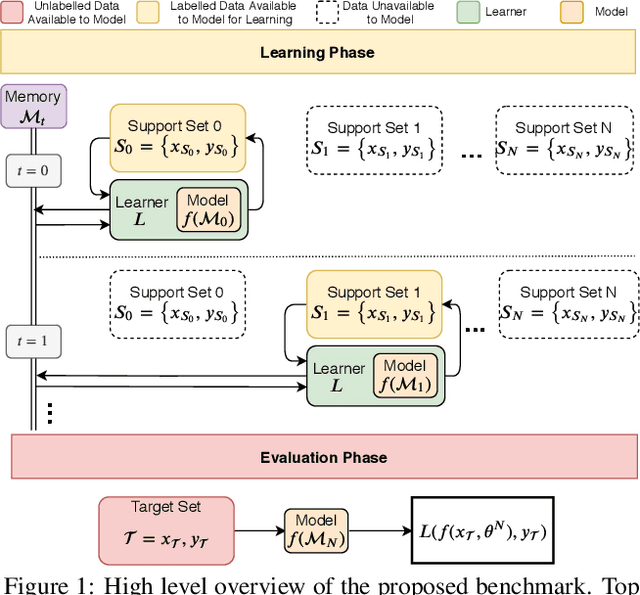
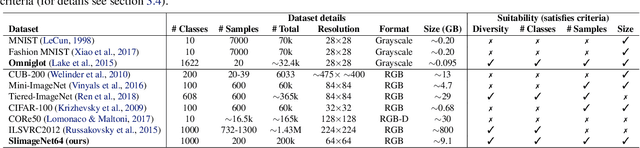
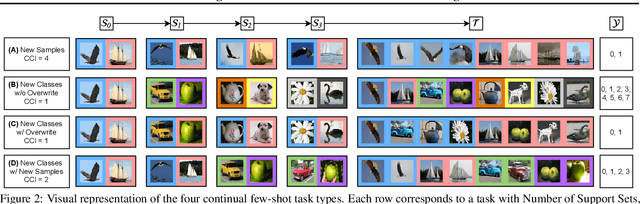
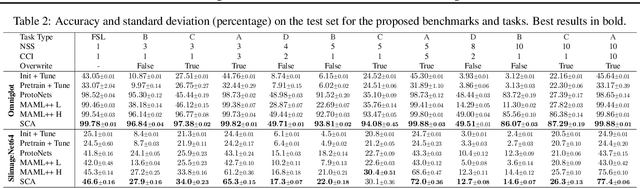
Both few-shot and continual learning have seen substantial progress in the last years due to the introduction of proper benchmarks. That being said, the field has still to frame a suite of benchmarks for the highly desirable setting of continual few-shot learning, where the learner is presented a number of few-shot tasks, one after the other, and then asked to perform well on a validation set stemming from all previously seen tasks. Continual few-shot learning has a small computational footprint and is thus an excellent setting for efficient investigation and experimentation. In this paper we first define a theoretical framework for continual few-shot learning, taking into account recent literature, then we propose a range of flexible benchmarks that unify the evaluation criteria and allows exploring the problem from multiple perspectives. As part of the benchmark, we introduce a compact variant of ImageNet, called SlimageNet64, which retains all original 1000 classes but only contains 200 instances of each one (a total of 200K data-points) downscaled to 64 x 64 pixels. We provide baselines for the proposed benchmarks using a number of popular few-shot learning algorithms, as a result, exposing previously unknown strengths and weaknesses of those algorithms in continual and data-limited settings.