 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOP-GEN: Latent Diffusion Transformer for Copernicus Earth Observation Data -- Generation Stochastic by Design
Mar 03, 2026Earth observation applications increasingly rely on data from multiple sensors, including optical, radar, elevation, and land-cover products. Relationships between these modalities are fundamental for data integration but are inherently non-injective: identical conditioning information can correspond to multiple physically plausible observations. Thus, such conditional mappings should be parametrised as data distributions. As a result, deterministic models tend to collapse toward conditional means and fail to represent the uncertainty and variability required for tasks such as data completion and cross-sensor translation. We introduce COP-GEN, a multimodal latent diffusion transformer that models the joint distribution of heterogeneous Earth Observation modalities at their native spatial resolutions. By parameterising cross-modal mappings as conditional distributions, COP-GEN enables flexible any-to-any conditional generation, including zero-shot modality translation, spectral band infilling, and generation under partial or missing inputs, without task-specific retraining. Experiments on a large-scale global multimodal dataset show that COP-GEN generates diverse yet physically consistent realisations while maintaining strong peak fidelity across optical, radar, and elevation modalities. Qualitative and quantitative analyses demonstrate that the model captures meaningful cross-modal structure and systematically adapts its output uncertainty as conditioning information increases. These results highlight the practical importance of stochastic generative modeling for Earth observation and motivate evaluation protocols that move beyond single-reference, pointwise metrics. Website: https:// miquel-espinosa.github.io/cop-gen
Kalman Linear Attention: Parallel Bayesian Filtering For Efficient Language Modelling and State Tracking
Feb 11, 2026State-space language models such as Mamba and gated linear attention (GLA) offer efficient alternatives to transformers due to their linear complexity and parallel training, but often lack the expressivity and robust state-tracking needed for complex reasoning. We address these limitations by reframing sequence modelling through a probabilistic lens, using Bayesian filters as a core primitive. While classical filters such as Kalman filters provide principled state estimation and uncertainty tracking, they are typically viewed as inherently sequential. We show that reparameterising the Kalman filter in information form enables its updates to be computed via an associative scan, allowing efficient parallel training. Building on this insight, we introduce the Kalman Linear Attention (KLA) layer, a neural sequence-modelling primitive that performs time-parallel probabilistic inference while maintaining explicit belief-state uncertainty. KLA offers strictly more expressive nonlinear updates and gating than GLA variants while retaining their computational advantages. On language modelling tasks, KLA matches or outperforms modern SSMs and GLAs across representative discrete token-manipulation and state-tracking benchmarks.
ONNX-Net: Towards Universal Representations and Instant Performance Prediction for Neural Architectures
Oct 06, 2025



Neural architecture search (NAS) automates the design process of high-performing architectures, but remains bottlenecked by expensive performance evaluation. Most existing studies that achieve faster evaluation are mostly tied to cell-based search spaces and graph encodings tailored to those individual search spaces, limiting their flexibility and scalability when applied to more expressive search spaces. In this work, we aim to close the gap of individual search space restrictions and search space dependent network representations. We present ONNX-Bench, a benchmark consisting of a collection of neural networks in a unified format based on ONNX files. ONNX-Bench includes all open-source NAS-bench-based neural networks, resulting in a total size of more than 600k {architecture, accuracy} pairs. This benchmark allows creating a shared neural network representation, ONNX-Net, able to represent any neural architecture using natural language descriptions acting as an input to a performance predictor. This text-based encoding can accommodate arbitrary layer types, operation parameters, and heterogeneous topologies, enabling a single surrogate to generalise across all neural architectures rather than being confined to cell-based search spaces. Experiments show strong zero-shot performance across disparate search spaces using only a small amount of pretraining samples, enabling the unprecedented ability to evaluate any neural network architecture instantly.
No time to train! Training-Free Reference-Based Instance Segmentation
Jul 03, 2025The performance of image segmentation models has historically been constrained by the high cost of collecting large-scale annotated data. The Segment Anything Model (SAM) alleviates this original problem through a promptable, semantics-agnostic, segmentation paradigm and yet still requires manual visual-prompts or complex domain-dependent prompt-generation rules to process a new image. Towards reducing this new burden, our work investigates the task of object segmentation when provided with, alternatively, only a small set of reference images. Our key insight is to leverage strong semantic priors, as learned by foundation models, to identify corresponding regions between a reference and a target image. We find that correspondences enable automatic generation of instance-level segmentation masks for downstream tasks and instantiate our ideas via a multi-stage, training-free method incorporating (1) memory bank construction; (2) representation aggregation and (3) semantic-aware feature matching. Our experiments show significant improvements on segmentation metrics, leading to state-of-the-art performance on COCO FSOD (36.8% nAP), PASCAL VOC Few-Shot (71.2% nAP50) and outperforming existing training-free approaches on the Cross-Domain FSOD benchmark (22.4% nAP).
Transferrable Surrogates in Expressive Neural Architecture Search Spaces
Apr 18, 2025Neural architecture search (NAS) faces a challenge in balancing the exploration of expressive, broad search spaces that enable architectural innovation with the need for efficient evaluation of architectures to effectively search such spaces. We investigate surrogate model training for improving search in highly expressive NAS search spaces based on context-free grammars. We show that i) surrogate models trained either using zero-cost-proxy metrics and neural graph features (GRAF) or by fine-tuning an off-the-shelf LM have high predictive power for the performance of architectures both within and across datasets, ii) these surrogates can be used to filter out bad architectures when searching on novel datasets, thereby significantly speeding up search and achieving better final performances, and iii) the surrogates can be further used directly as the search objective for huge speed-ups.
COP-GEN-Beta: Unified Generative Modelling of COPernicus Imagery Thumbnails
Apr 14, 2025In remote sensing, multi-modal data from various sensors capturing the same scene offers rich opportunities, but learning a unified representation across these modalities remains a significant challenge. Traditional methods have often been limited to single or dual-modality approaches. In this paper, we introduce COP-GEN-Beta, a generative diffusion model trained on optical, radar, and elevation data from the Major TOM dataset. What sets COP-GEN-Beta apart is its ability to map any subset of modalities to any other, enabling zero-shot modality translation after training. This is achieved through a sequence-based diffusion transformer, where each modality is controlled by its own timestep embedding. We extensively evaluate COP-GEN-Beta on thumbnail images from the Major TOM dataset, demonstrating its effectiveness in generating high-quality samples. Qualitative and quantitative evaluations validate the model's performance, highlighting its potential as a powerful pre-trained model for future remote sensing tasks.
There is no SAMantics! Exploring SAM as a Backbone for Visual Understanding Tasks
Nov 22, 2024The Segment Anything Model (SAM) was originally designed for label-agnostic mask generation. Does this model also possess inherent semantic understanding, of value to broader visual tasks? In this work we follow a multi-staged approach towards exploring this question. We firstly quantify SAM's semantic capabilities by comparing base image encoder efficacy under classification tasks, in comparison with established models (CLIP and DINOv2). Our findings reveal a significant lack of semantic discriminability in SAM feature representations, limiting potential for tasks that require class differentiation. This initial result motivates our exploratory study that attempts to enable semantic information via in-context learning with lightweight fine-tuning where we observe that generalisability to unseen classes remains limited. Our observations culminate in the proposal of a training-free approach that leverages DINOv2 features, towards better endowing SAM with semantic understanding and achieving instance-level class differentiation through feature-based similarity. Our study suggests that incorporation of external semantic sources provides a promising direction for the enhancement of SAM's utility with respect to complex visual tasks that require semantic understanding.
einspace: Searching for Neural Architectures from Fundamental Operations
May 31, 2024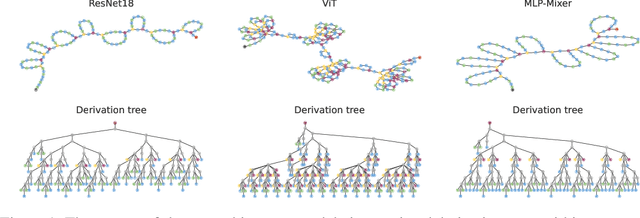
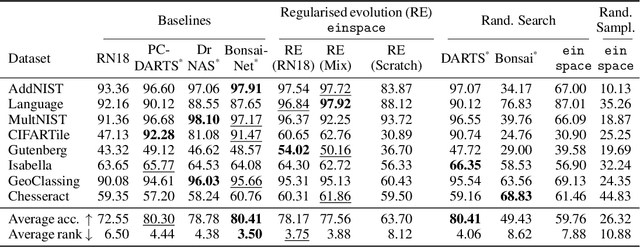

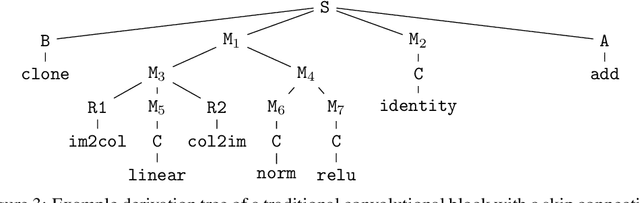
Neural architecture search (NAS) finds high performing networks for a given task. Yet the results of NAS are fairly prosaic; they did not e.g. create a shift from convolutional structures to transformers. This is not least because the search spaces in NAS often aren't diverse enough to include such transformations a priori. Instead, for NAS to provide greater potential for fundamental design shifts, we need a novel expressive search space design which is built from more fundamental operations. To this end, we introduce einspace, a search space based on a parameterised probabilistic context-free grammar. Our space is versatile, supporting architectures of various sizes and complexities, while also containing diverse network operations which allow it to model convolutions, attention components and more. It contains many existing competitive architectures, and provides flexibility for discovering new ones. Using this search space, we perform experiments to find novel architectures as well as improvements on existing ones on the diverse Unseen NAS datasets. We show that competitive architectures can be obtained by searching from scratch, and we consistently find large improvements when initialising the search with strong baselines. We believe that this work is an important advancement towards a transformative NAS paradigm where search space expressivity and strategic search initialisation play key roles.
Hyperparameter Selection in Continual Learning
Apr 09, 2024



In continual learning (CL) -- where a learner trains on a stream of data -- standard hyperparameter optimisation (HPO) cannot be applied, as a learner does not have access to all of the data at the same time. This has prompted the development of CL-specific HPO frameworks. The most popular way to tune hyperparameters in CL is to repeatedly train over the whole data stream with different hyperparameter settings. However, this end-of-training HPO is unrealistic as in practice a learner can only see the stream once. Hence, there is an open question: what HPO framework should a practitioner use for a CL problem in reality? This paper answers this question by evaluating several realistic HPO frameworks. We find that all the HPO frameworks considered, including end-of-training HPO, perform similarly. We therefore advocate using the realistic and most computationally efficient method: fitting the hyperparameters on the first task and then fixing them throughout training.
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Mar 26, 2024



We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a deformable stereo operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training techniques, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs.