 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Unstructured Sparsity in Fully Homomorphic Encrypted DNNs
Mar 12, 2025



The deployment of deep neural networks (DNNs) in privacy-sensitive environments is constrained by computational overheads in fully homomorphic encryption (FHE). This paper explores unstructured sparsity in FHE matrix multiplication schemes as a means of reducing this burden while maintaining model accuracy requirements. We demonstrate that sparsity can be exploited in arbitrary matrix multiplication, providing runtime benefits compared to a baseline naive algorithm at all sparsity levels. This is a notable departure from the plaintext domain, where there is a trade-off between sparsity and the overhead of the sparse multiplication algorithm. In addition, we propose three sparse multiplication schemes in FHE based on common plaintext sparse encodings. We demonstrate the performance gain is scheme-invariant; however, some sparse schemes vastly reduce the memory storage requirements of the encrypted matrix at high sparsity values. Our proposed sparse schemes yield an average performance gain of 2.5x at 50% unstructured sparsity, with our multi-threading scheme providing a 32.5x performance increase over the equivalent single-threaded sparse computation when utilizing 64 cores.
Fix-Con: Automatic Fault Localization and Repair of Deep Learning Model Conversions
Dec 22, 2023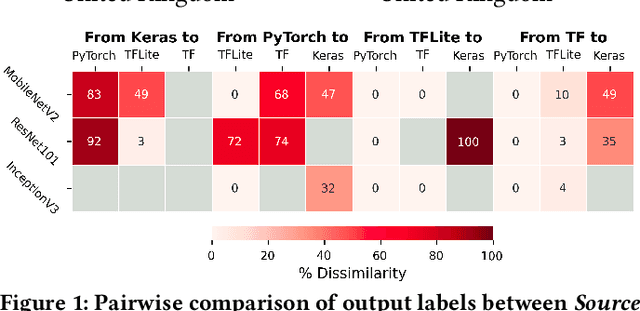
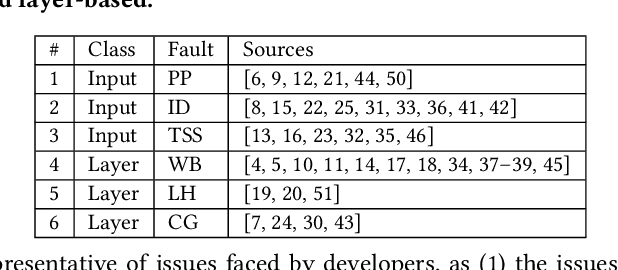
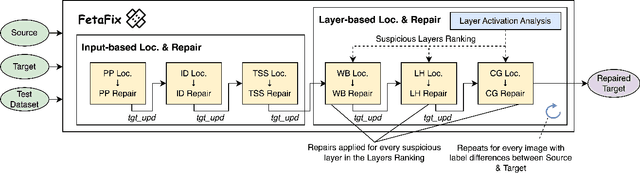
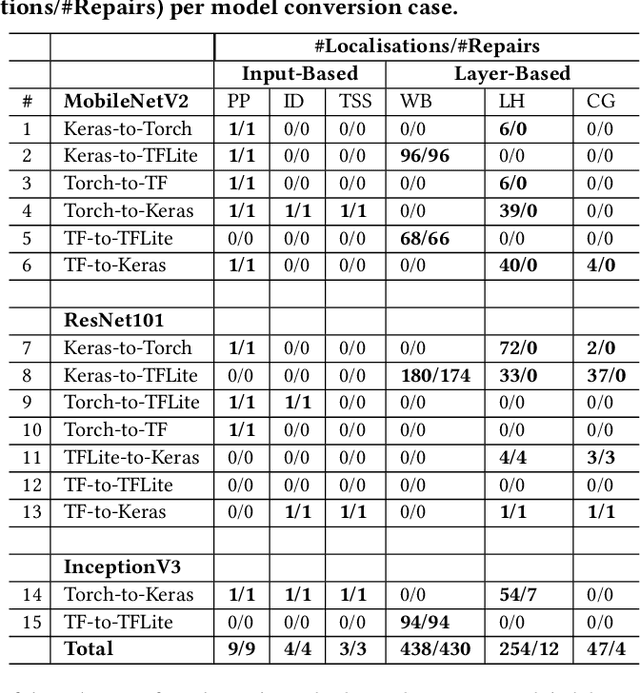
Converting deep learning models between frameworks is a common step to maximize model compatibility across devices and leverage optimization features that may be exclusively provided in one deep learning framework. However, this conversion process may be riddled with bugs, making the converted models either undeployable or problematic, considerably degrading their prediction correctness. We propose an automated approach for fault localization and repair, Fix-Con, during model conversion between deep learning frameworks. Fix-Con is capable of detecting and fixing faults introduced in model input, parameters, hyperparameters, and the model graph during conversion. Fix-Con uses a set of fault types mined from surveying conversion issues raised to localize potential conversion faults in the converted target model, and then repairs them appropriately, e.g. replacing the parameters of the target model with those from the source model. This is done iteratively for every image in the dataset with output label differences between the source model and the converted target model until all differences are resolved. We evaluate the effectiveness of Fix-Con in fixing model conversion bugs of three widely used image recognition models converted across four different deep learning frameworks. Overall, Fix-Con was able to either completely repair, or significantly improve the performance of 14 out of the 15 erroneous conversion cases.
DLAS: An Exploration and Assessment of the Deep Learning Acceleration Stack
Nov 15, 2023



Deep Neural Networks (DNNs) are extremely computationally demanding, which presents a large barrier to their deployment on resource-constrained devices. Since such devices are where many emerging deep learning applications lie (e.g., drones, vision-based medical technology), significant bodies of work from both the machine learning and systems communities have attempted to provide optimizations to accelerate DNNs. To help unify these two perspectives, in this paper we combine machine learning and systems techniques within the Deep Learning Acceleration Stack (DLAS), and demonstrate how these layers can be tightly dependent on each other with an across-stack perturbation study. We evaluate the impact on accuracy and inference time when varying different parameters of DLAS across two datasets, seven popular DNN architectures, four DNN compression techniques, three algorithmic primitives with sparse and dense variants, untuned and auto-scheduled code generation, and four hardware platforms. Our evaluation highlights how perturbations across DLAS parameters can cause significant variation and across-stack interactions. The highest level observation from our evaluation is that the model size, accuracy, and inference time are not guaranteed to be correlated. Overall we make 13 key observations, including that speedups provided by compression techniques are very hardware dependent, and that compiler auto-tuning can significantly alter what the best algorithm to use for a given configuration is. With DLAS, we aim to provide a reference framework to aid machine learning and systems practitioners in reasoning about the context in which their respective DNN acceleration solutions exist in. With our evaluation strongly motivating the need for co-design, we believe that DLAS can be a valuable concept for exploring the next generation of co-designed accelerated deep learning solutions.
MutateNN: Mutation Testing of Image Recognition Models Deployed on Hardware Accelerators
Jun 21, 2023With the research advancement of Artificial Intelligence in the last years, there are new opportunities to mitigate real-world problems and advance technologically. Image recognition models in particular, are assigned with perception tasks to mitigate complex real-world challenges and lead to new solutions. Furthermore, the computational complexity and demand for resources of such models has also increased. To mitigate this, model optimization and hardware acceleration has come into play, but effectively integrating such concepts is a challenging and error-prone process. In order to allow developers and researchers to explore the robustness of deep learning image recognition models deployed on different hardware acceleration devices, we propose MutateNN, a tool that provides mutation testing and analysis capabilities for that purpose. To showcase its capabilities, we utilized 21 mutations for 7 widely-known pre-trained deep neural network models. We deployed our mutants on 4 different devices of varying computational capabilities and observed discrepancies in mutants related to conditional operations, as well as some unstable behaviour with those related to arithmetic types.
Fault Localization for Framework Conversions of Image Recognition Models
Jun 10, 2023



When deploying Deep Neural Networks (DNNs), developers often convert models from one deep learning framework to another (e.g., TensorFlow to PyTorch). However, this process is error-prone and can impact target model accuracy. To identify the extent of such impact, we perform and briefly present a differential analysis against three DNNs used for image recognition (MobileNetV2, ResNet101, and InceptionV3), converted across four well-known deep learning frameworks (PyTorch, Keras, TensorFlow (TF), and TFLite), which revealed numerous model crashes and output label discrepancies of up to 100%. To mitigate such errors, we present a novel approach towards fault localization and repair of buggy deep learning framework conversions, focusing on pre-trained image recognition models. Our technique consists of four primary stages of analysis: 1) conversion tools, 2) model parameters, 3) model hyperparameters, and 4) graph representation. In addition, we propose a number of strategies towards fault repair of the faults detected. We implement our technique on top of Apache TVM deep learning compiler, and we test it by conducting a preliminary fault localization analysis for the conversion of InceptionV3, from TF to TFLite. Our approach detected that the tf2onnx tool used in the conversion process introduced precision errors to model weights for convolutional layers in particular, which negatively affected the model accuracy. We then repaired the target model by replacing the affected weights with those from source model.
A Differential Testing Framework to Evaluate Image Recognition Model Robustness
Jun 05, 2023



Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and TPUs for fast, timely processing. Failure in real-time image recognition tasks can occur due to sub-optimal mapping on hardware accelerators during model deployment, which may lead to timing uncertainty and erroneous behavior. Mapping on hardware accelerators is done through multiple software components like deep learning frameworks, compilers, device libraries, that we refer to as the computational environment. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment, as the impact of parameters like deep learning frameworks, compiler optimizations, and hardware devices on model performance and correctness is not well understood. In this paper we present a differential testing framework, which allows deep learning model variant generation, execution, differential analysis and testing for a number of computational environment parameters. Using our framework, we conduct an empirical study of robustness analysis of three popular image recognition models using the ImageNet dataset, assessing the impact of changing deep learning frameworks, compiler optimizations, and hardware devices. We report the impact in terms of misclassifications and inference time differences across different settings. In total, we observed up to 72% output label differences across deep learning frameworks, and up to 82% unexpected performance degradation in terms of inference time, when applying compiler optimizations. Using the analysis tools in our framework, we also perform fault analysis to understand the reasons for the observed differences.
Exploring Effects of Computational Parameter Changes to Image Recognition Systems
Nov 02, 2022Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and FPGAs for fast, timely processing. Failure in real-time image recognition tasks can occur due to incorrect mapping on hardware accelerators, which may lead to timing uncertainty and incorrect behavior. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment as parameters like deep learning frameworks, compiler optimizations for code generation, and hardware devices are not regulated with varying impact on model performance and correctness. In this paper we conduct robustness analysis of four popular image recognition models (MobileNetV2, ResNet101V2, DenseNet121 and InceptionV3) with the ImageNet dataset, assessing the impact of the following parameters in the model's computational environment: (1) deep learning frameworks; (2) compiler optimizations; and (3) hardware devices. We report sensitivity of model performance in terms of output label and inference time for changes in each of these environment parameters. We find that output label predictions for all four models are sensitive to choice of deep learning framework (by up to 57%) and insensitive to other parameters. On the other hand, model inference time was affected by all environment parameters with changes in hardware device having the most effect. The extent of effect was not uniform across models.
Productive Reproducible Workflows for DNNs: A Case Study for Industrial Defect Detection
Jun 19, 2022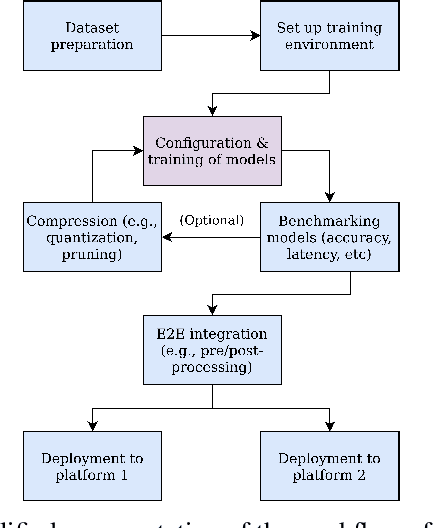
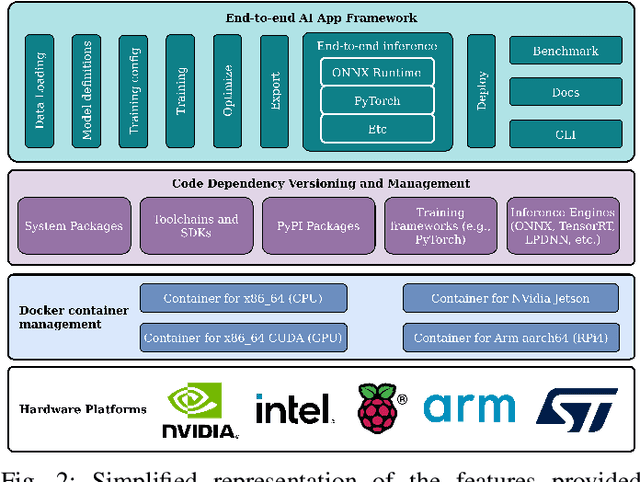

As Deep Neural Networks (DNNs) have become an increasingly ubiquitous workload, the range of libraries and tooling available to aid in their development and deployment has grown significantly. Scalable, production quality tools are freely available under permissive licenses, and are accessible enough to enable even small teams to be very productive. However within the research community, awareness and usage of said tools is not necessarily widespread, and researchers may be missing out on potential productivity gains from exploiting the latest tools and workflows. This paper presents a case study where we discuss our recent experience producing an end-to-end artificial intelligence application for industrial defect detection. We detail the high level deep learning libraries, containerized workflows, continuous integration/deployment pipelines, and open source code templates we leveraged to produce a competitive result, matching the performance of other ranked solutions to our three target datasets. We highlight the value that exploiting such systems can bring, even for research, and detail our solution and present our best results in terms of accuracy and inference time on a server class GPU, as well as inference times on a server class CPU, and a Raspberry Pi 4.
Bifrost: End-to-End Evaluation and Optimization of Reconfigurable DNN Accelerators
Apr 26, 2022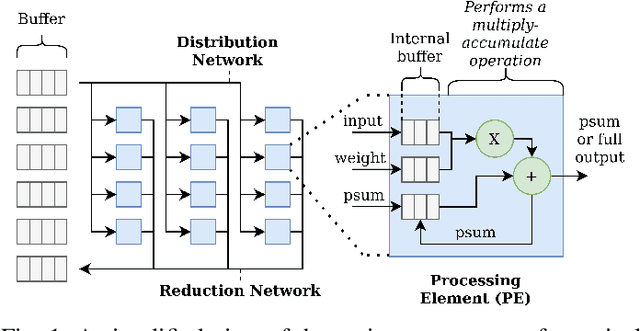
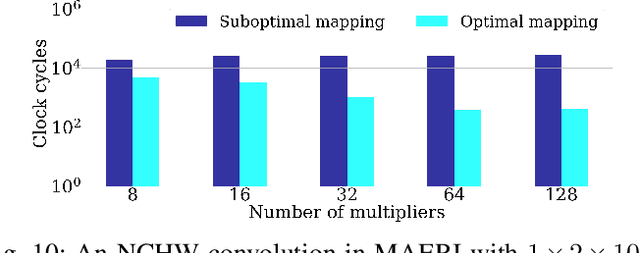
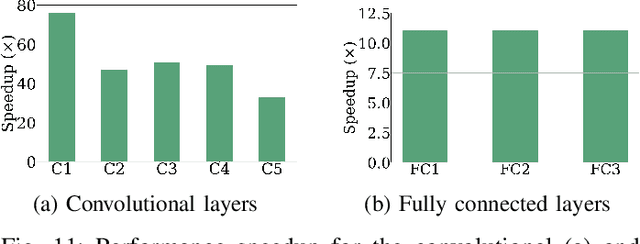
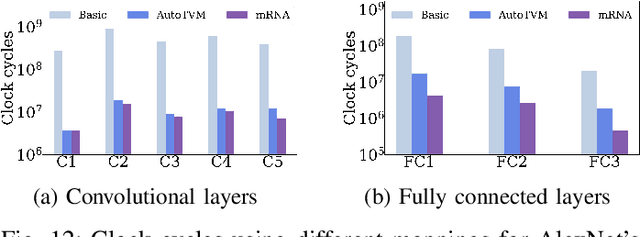
Reconfigurable accelerators for deep neural networks (DNNs) promise to improve performance such as inference latency. STONNE is the first cycle-accurate simulator for reconfigurable DNN inference accelerators which allows for the exploration of accelerator designs and configuration space. However, preparing models for evaluation and exploring configuration space in STONNE is a manual developer-timeconsuming process, which is a barrier for research. This paper introduces Bifrost, an end-to-end framework for the evaluation and optimization of reconfigurable DNN inference accelerators. Bifrost operates as a frontend for STONNE and leverages the TVM deep learning compiler stack to parse models and automate offloading of accelerated computations. We discuss Bifrost's advantages over STONNE and other tools, and evaluate the MAERI and SIGMA architectures using Bifrost. Additionally, Bifrost introduces a module leveraging AutoTVM to efficiently explore accelerator designs and dataflow mapping space to optimize performance. This is demonstrated by tuning the MAERI architecture and generating efficient dataflow mappings for AlexNet, obtaining an average speedup of $50\times$ for the convolutional layers and $11\times$ for the fully connected layers. Our code is available at www.github.com/gicLAB/bifrost.
Reusing Auto-Schedules for Efficient DNN Compilation
Jan 14, 2022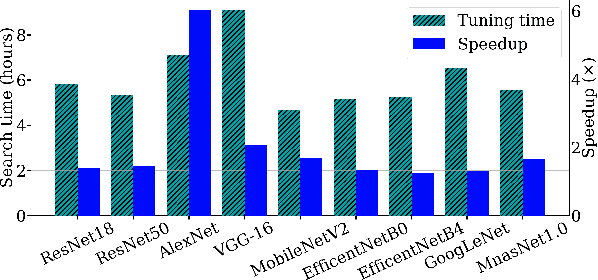
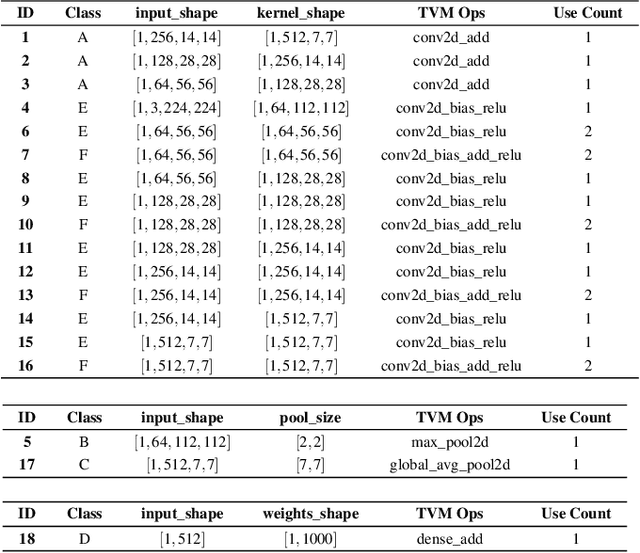
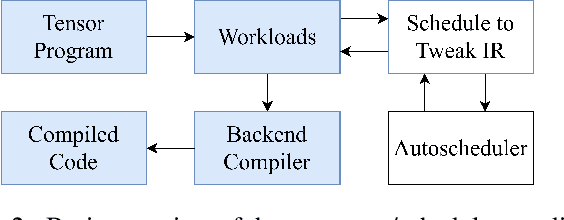
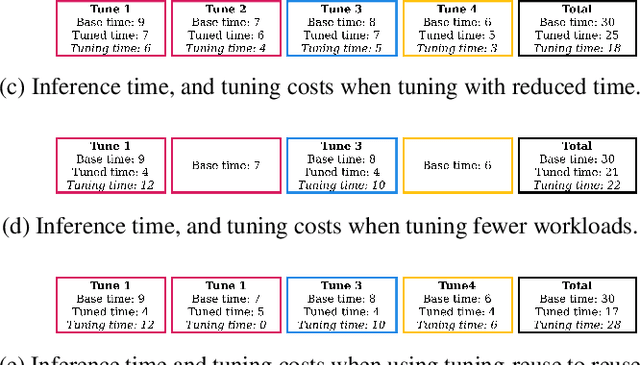
Auto-scheduling is a process where a search algorithm automatically explores candidate schedules (program transformations) for a given tensor program on a given hardware platform to improve its performance. However this can be a very time consuming process, depending on the complexity of the tensor program, and capacity of the target device, with often many thousands of program variants being explored. To address this, in this paper we introduce and demonstrate the idea of \emph{tuning-reuse}, a novel approach to identify and re-use auto-schedules between tensor programs. We demonstrate this concept using Deep Neural Networks (DNNs), taking sets of auto-schedules from pre-tuned DNNs, and using them to reduce the inference time of a new DNN. Given a set of pre-tuned schedules, tuning-reuse provides its maximum speedup in less time than auto-scheduling using the state-of-the-art Ansor auto-scheduler. On a set of widely used DNN models, we apply tuning-reuse and achieve maximum speedups between $1.16\times$ and $4.76\times$, while outperforming Ansor when given limited tuning time.