 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Aware Synthetic Image Generation for Concept Coverage in Chest X-ray Models
Mar 16, 2026The clinical deployment of AI diagnostic models demands more than benchmark accuracy - it demands robustness across the full spectrum of disease presentations. However, publicly available chest radiographic datasets systematically underrepresent critical clinical feature combinations, leaving models under-trained precisely where clinical stakes are highest. We present CARS, a clinically aware and anatomically grounded framework that addresses this gap through principled synthetic image generation. CARS applies targeted perturbations to clinical feature vectors, enabling controlled insertion and deletion of pathological findings while explicitly preserving anatomical structure. We evaluate CARS across seven backbone architectures by fine-tuning models on synthetic subsets and testing on a held-out MIMIC-CXR benchmark. Compared to prior feature perturbation approaches, fine-tuning on CARS-generated images consistently improves precision-recall performance, reduces predictive uncertainty, and improves model calibration. Structural and semantic analyses demonstrate high anatomical fidelity, strong feature alignment, and low semantic uncertainty. Independent evaluation by two expert radiologists further confirms realism and clinical agreement. As the field moves toward regulated clinical AI, CARS demonstrates that anatomically faithful synthetic data generation for better feature space coverage is a viable and effective strategy for improving both the performance and trustworthiness of chest X-ray classification systems - without compromising clinical integrity.
Limitations of Public Chest Radiography Datasets for Artificial Intelligence: Label Quality, Domain Shift, Bias and Evaluation Challenges
Sep 18, 2025



Artificial intelligence has shown significant promise in chest radiography, where deep learning models can approach radiologist-level diagnostic performance. Progress has been accelerated by large public datasets such as MIMIC-CXR, ChestX-ray14, PadChest, and CheXpert, which provide hundreds of thousands of labelled images with pathology annotations. However, these datasets also present important limitations. Automated label extraction from radiology reports introduces errors, particularly in handling uncertainty and negation, and radiologist review frequently disagrees with assigned labels. In addition, domain shift and population bias restrict model generalisability, while evaluation practices often overlook clinically meaningful measures. We conduct a systematic analysis of these challenges, focusing on label quality, dataset bias, and domain shift. Our cross-dataset domain shift evaluation across multiple model architectures revealed substantial external performance degradation, with pronounced reductions in AUPRC and F1 scores relative to internal testing. To assess dataset bias, we trained a source-classification model that distinguished datasets with near-perfect accuracy, and performed subgroup analyses showing reduced performance for minority age and sex groups. Finally, expert review by two board-certified radiologists identified significant disagreement with public dataset labels. Our findings highlight important clinical weaknesses of current benchmarks and emphasise the need for clinician-validated datasets and fairer evaluation frameworks.
Selective Quantization Tuning for ONNX Models
Jul 16, 2025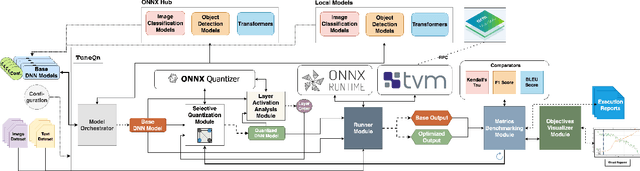
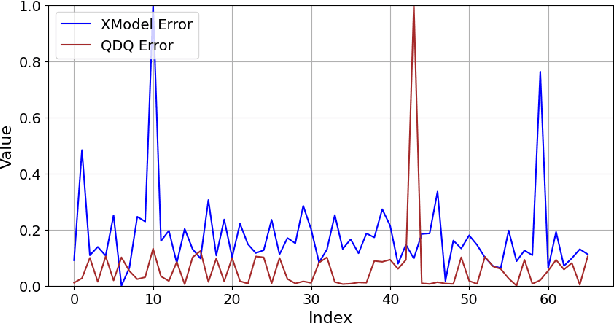


Quantization is a process that reduces the precision of deep neural network models to lower model size and computational demands, often at the cost of accuracy. However, fully quantized models may exhibit sub-optimal performance below acceptable levels and face deployment challenges on low-end hardware accelerators due to practical constraints. To address these issues, quantization can be selectively applied to only a subset of layers, but selecting which layers to exclude is non-trivial. To this direction, we propose TuneQn, a suite enabling selective quantization, deployment and execution of ONNX models across various CPU and GPU devices, combined with profiling and multi-objective optimization. TuneQn generates selectively quantized ONNX models, deploys them on different hardware, measures performance on metrics like accuracy and size, performs Pareto Front minimization to identify the best model candidate and visualizes the results. To demonstrate the effectiveness of TuneQn, we evaluated TuneQn on four ONNX models with two quantization settings across CPU and GPU devices. As a result, we demonstrated that our utility effectively performs selective quantization and tuning, selecting ONNX model candidates with up to a $54.14$% reduction in accuracy loss compared to the fully quantized model, and up to a $72.9$% model size reduction compared to the original model.
Explainability Through Human-Centric Design for XAI in Lung Cancer Detection
May 14, 2025



Deep learning models have shown promise in lung pathology detection from chest X-rays, but widespread clinical adoption remains limited due to opaque model decision-making. In prior work, we introduced ClinicXAI, a human-centric, expert-guided concept bottleneck model (CBM) designed for interpretable lung cancer diagnosis. We now extend that approach and present XpertXAI, a generalizable expert-driven model that preserves human-interpretable clinical concepts while scaling to detect multiple lung pathologies. Using a high-performing InceptionV3-based classifier and a public dataset of chest X-rays with radiology reports, we compare XpertXAI against leading post-hoc explainability methods and an unsupervised CBM, XCBs. We assess explanations through comparison with expert radiologist annotations and medical ground truth. Although XpertXAI is trained for multiple pathologies, our expert validation focuses on lung cancer. We find that existing techniques frequently fail to produce clinically meaningful explanations, omitting key diagnostic features and disagreeing with radiologist judgments. XpertXAI not only outperforms these baselines in predictive accuracy but also delivers concept-level explanations that better align with expert reasoning. While our focus remains on explainability in lung cancer detection, this work illustrates how human-centric model design can be effectively extended to broader diagnostic contexts - offering a scalable path toward clinically meaningful explainable AI in medical diagnostics.
OODTE: A Differential Testing Engine for the ONNX Optimizer
May 03, 2025With $700$ stars on GitHub and part of the official ONNX repository, the ONNX Optimizer consists of the standard method to apply graph-based optimizations on ONNX models. However, its ability to preserve model accuracy across optimizations, has not been rigorously explored. We propose OODTE, a utility to automatically and thoroughly assess the correctness of the ONNX Optimizer. OODTE follows a simple, yet effective differential testing and evaluation approach that can be easily adopted to other compiler optimizers. In particular, OODTE utilizes a number of ONNX models, then optimizes them and executes both the original and the optimized variants across a user-defined set of inputs, while automatically logging any issues with the optimization process. Finally, for successfully optimized models, OODTE compares the results, and, if any accuracy deviations are observed, it iteratively repeats the process for each pass of the ONNX Optimizer, to localize the root cause of the differences observed. Using OODTE, we sourced well-known $130$ models from the official ONNX Model Hub, used for a wide variety of tasks (classification, object detection, semantic segmentation, text summarization, question and answering, sentiment analysis) from the official ONNX model hub. We detected 15 issues, 14 of which were previously unknown, associated with optimizer crashes and accuracy deviations. We also observed $9.2$% of all model instances presenting issues leading into the crash of the optimizer, or the generation of an invalid model while using the primary optimizer strategies. In addition, $30$% of the classification models presented accuracy differences across the original and the optimized model variants, while $16.6$% of semantic segmentation and object detection models are also affected, at least to a limited extent.
Metric-Guided Synthesis of Class Activation Mapping
Apr 14, 2025Class activation mapping (CAM) is a widely adopted class of saliency methods used to explain the behavior of convolutional neural networks (CNNs). These methods generate heatmaps that highlight the parts of the input most relevant to the CNN output. Various CAM methods have been proposed, each distinguished by the expressions used to derive heatmaps. In general, users look for heatmaps with specific properties that reflect different aspects of CNN functionality. These may include similarity to ground truth, robustness, equivariance, and more. Although existing CAM methods implicitly encode some of these properties in their expressions, they do not allow for variability in heatmap generation following the user's intent or domain knowledge. In this paper, we address this limitation by introducing SyCAM, a metric-based approach for synthesizing CAM expressions. Given a predefined evaluation metric for saliency maps, SyCAM automatically generates CAM expressions optimized for that metric. We specifically explore a syntax-guided synthesis instantiation of SyCAM, where CAM expressions are derived based on predefined syntactic constraints and the given metric. Using several established evaluation metrics, we demonstrate the efficacy and flexibility of our approach in generating targeted heatmaps. We compare SyCAM with other well-known CAM methods on three prominent models: ResNet50, VGG16, and VGG19.
CoRPA: Adversarial Image Generation for Chest X-rays Using Concept Vector Perturbations and Generative Models
Feb 04, 2025
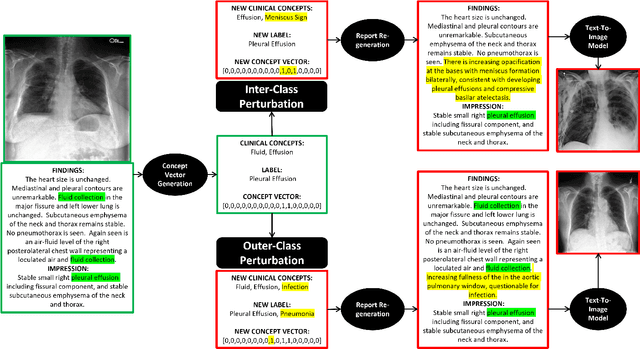


Deep learning models for medical image classification tasks are becoming widely implemented in AI-assisted diagnostic tools, aiming to enhance diagnostic accuracy, reduce clinician workloads, and improve patient outcomes. However, their vulnerability to adversarial attacks poses significant risks to patient safety. Current attack methodologies use general techniques such as model querying or pixel value perturbations to generate adversarial examples designed to fool a model. These approaches may not adequately address the unique characteristics of clinical errors stemming from missed or incorrectly identified clinical features. We propose the Concept-based Report Perturbation Attack (CoRPA), a clinically-focused black-box adversarial attack framework tailored to the medical imaging domain. CoRPA leverages clinical concepts to generate adversarial radiological reports and images that closely mirror realistic clinical misdiagnosis scenarios. We demonstrate the utility of CoRPA using the MIMIC-CXR-JPG dataset of chest X-rays and radiological reports. Our evaluation reveals that deep learning models exhibiting strong resilience to conventional adversarial attacks are significantly less robust when subjected to CoRPA's clinically-focused perturbations. This underscores the importance of addressing domain-specific vulnerabilities in medical AI systems. By introducing a specialized adversarial attack framework, this study provides a foundation for developing robust, real-world-ready AI models in healthcare, ensuring their safe and reliable deployment in high-stakes clinical environments.
Go-Oracle: Automated Test Oracle for Go Concurrency Bugs
Dec 11, 2024



The Go programming language has gained significant traction for developing software, especially in various infrastructure systems. Nonetheless, concurrency bugs have become a prevalent issue within Go, presenting a unique challenge due to the language's dual concurrency mechanisms-communicating sequential processes and shared memory. Detecting concurrency bugs and accurately classifying program executions as pass or fail presents an immense challenge, even for domain experts. We conducted a survey with expert developers at Bytedance that confirmed this challenge. Our work seeks to address the test oracle problem for Go programs, to automatically classify test executions as pass or fail. This problem has not been investigated in the literature for Go programs owing to its distinctive programming model. Our approach involves collecting both passing and failing execution traces from various subject Go programs. We capture a comprehensive array of execution events using the native Go execution tracer. Subsequently, we preprocess and encode these traces before training a transformer-based neural network to effectively classify the traces as either passing or failing. The evaluation of our approach encompasses 8 subject programs sourced from the GoBench repository. These subject programs are routinely used as benchmarks in an industry setting. Encouragingly, our test oracle, Go-Oracle, demonstrates high accuracies even when operating with a limited dataset, showcasing the efficacy and potential of our methodology. Developers at Bytedance strongly agreed that they would use the Go-Oracle tool over the current practice of manual inspections to classify tests for Go programs as pass or fail.
Explainable Attribute-Based Speaker Verification
May 30, 2024
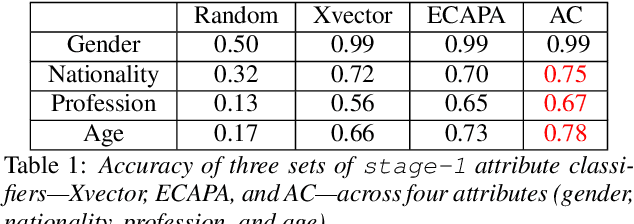
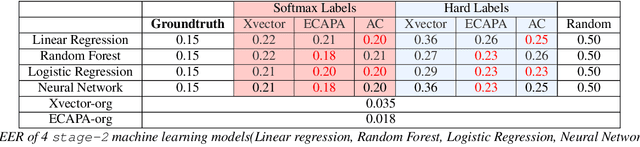

This paper proposes a fully explainable approach to speaker verification (SV), a task that fundamentally relies on individual speaker characteristics. The opaque use of speaker attributes in current SV systems raises concerns of trust. Addressing this, we propose an attribute-based explainable SV system that identifies speakers by comparing personal attributes such as gender, nationality, and age extracted automatically from voice recordings. We believe this approach better aligns with human reasoning, making it more understandable than traditional methods. Evaluated on the Voxceleb1 test set, the best performance of our system is comparable with the ground truth established when using all correct attributes, proving its efficacy. Whilst our approach sacrifices some performance compared to non-explainable methods, we believe that it moves us closer to the goal of transparent, interpretable AI and lays the groundwork for future enhancements through attribute expansion.
Transparent and Clinically Interpretable AI for Lung Cancer Detection in Chest X-Rays
Mar 28, 2024



The rapidly advancing field of Explainable Artificial Intelligence (XAI) aims to tackle the issue of trust regarding the use of complex black-box deep learning models in real-world applications. Existing post-hoc XAI techniques have recently been shown to have poor performance on medical data, producing unreliable explanations which are infeasible for clinical use. To address this, we propose an ante-hoc approach based on concept bottleneck models which introduces for the first time clinical concepts into the classification pipeline, allowing the user valuable insight into the decision-making process. On a large public dataset of chest X-rays and associated medical reports, we focus on the binary classification task of lung cancer detection. Our approach yields improved classification performance in lung cancer detection when compared to baseline deep learning models (F1 > 0.9), while also generating clinically relevant and more reliable explanations than existing techniques. We evaluate our approach against post-hoc image XAI techniques LIME and SHAP, as well as CXR-LLaVA, a recent textual XAI tool which operates in the context of question answering on chest X-rays.