 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Attribute-Based Speaker Verification
May 30, 2024
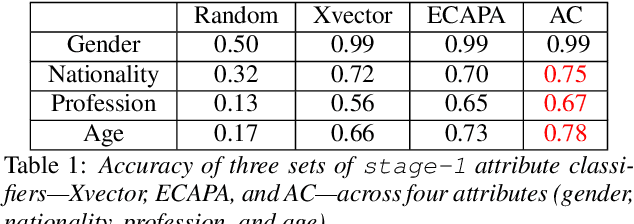
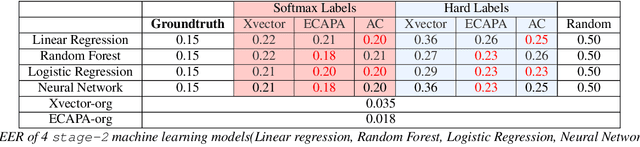

This paper proposes a fully explainable approach to speaker verification (SV), a task that fundamentally relies on individual speaker characteristics. The opaque use of speaker attributes in current SV systems raises concerns of trust. Addressing this, we propose an attribute-based explainable SV system that identifies speakers by comparing personal attributes such as gender, nationality, and age extracted automatically from voice recordings. We believe this approach better aligns with human reasoning, making it more understandable than traditional methods. Evaluated on the Voxceleb1 test set, the best performance of our system is comparable with the ground truth established when using all correct attributes, proving its efficacy. Whilst our approach sacrifices some performance compared to non-explainable methods, we believe that it moves us closer to the goal of transparent, interpretable AI and lays the groundwork for future enhancements through attribute expansion.
Leveraging speaker attribute information using multi task learning for speaker verification and diarization
Oct 27, 2020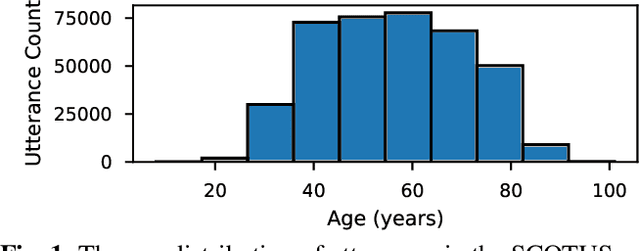
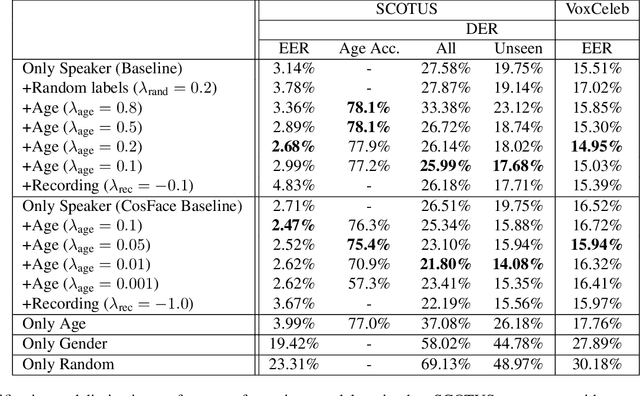
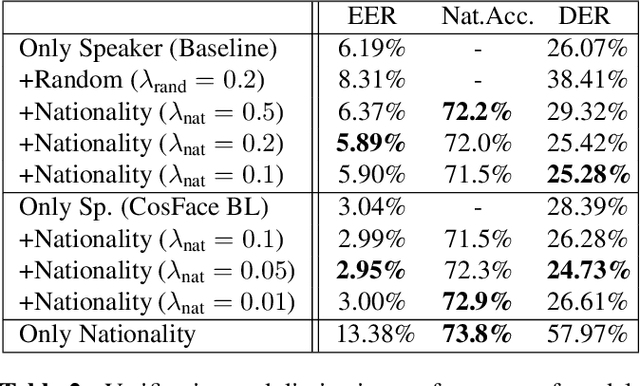
Deep speaker embeddings have become the leading method for encoding speaker identity in speaker recognition tasks. The embedding space should ideally capture the variations between all possible speakers, encoding the multiple aspects that make up speaker identity. In this work, utilizing speaker age as an auxiliary variable in US Supreme Court recordings and speaker nationality with VoxCeleb, we show that by leveraging additional speaker attribute information in a multi task learning setting, deep speaker embedding performance can be increased for verification and diarization tasks, achieving a relative improvement of 17.8% in DER and 8.9% in EER for Supreme Court audio compared to omitting the auxiliary task. Experimental code has been made publicly available.
DropClass and DropAdapt: Dropping classes for deep speaker representation learning
Feb 02, 2020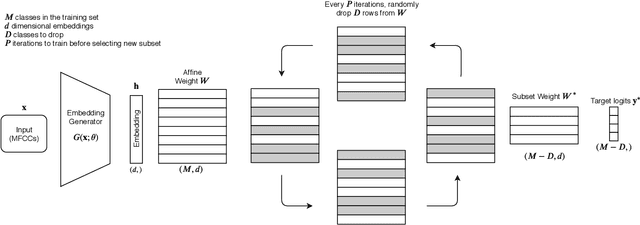
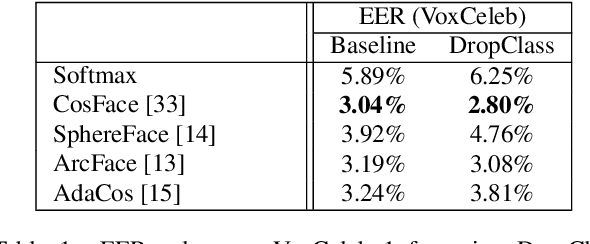
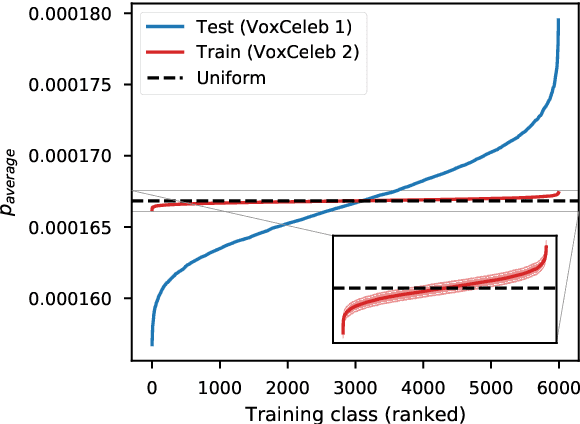
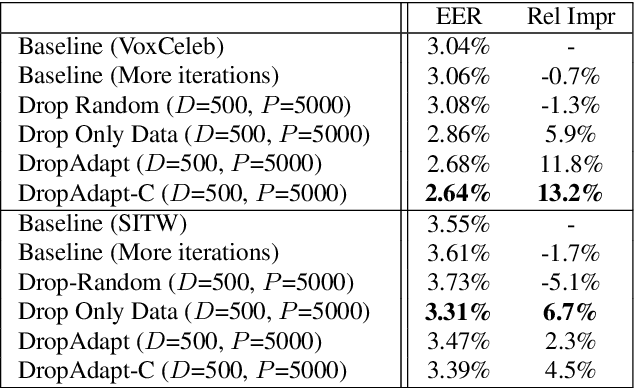
Many recent works on deep speaker embeddings train their feature extraction networks on large classification tasks, distinguishing between all speakers in a training set. Empirically, this has been shown to produce speaker-discriminative embeddings, even for unseen speakers. However, it is not clear that this is the optimal means of training embeddings that generalize well. This work proposes two approaches to learning embeddings, based on the notion of dropping classes during training. We demonstrate that both approaches can yield performance gains in speaker verification tasks. The first proposed method, DropClass, works via periodically dropping a random subset of classes from the training data and the output layer throughout training, resulting in a feature extractor trained on many different classification tasks. Combined with an additive angular margin loss, this method can yield a 7.9% relative improvement in equal error rate (EER) over a strong baseline on VoxCeleb. The second proposed method, DropAdapt, is a means of adapting a trained model to a set of enrolment speakers in an unsupervised manner. This is performed by fine-tuning a model on only those classes which produce high probability predictions when the enrolment speakers are used as input, again also dropping the relevant rows from the output layer. This method yields a large 13.2% relative improvement in EER on VoxCeleb. The code for this paper has been made publicly available.
Channel adversarial training for speaker verification and diarization
Oct 25, 2019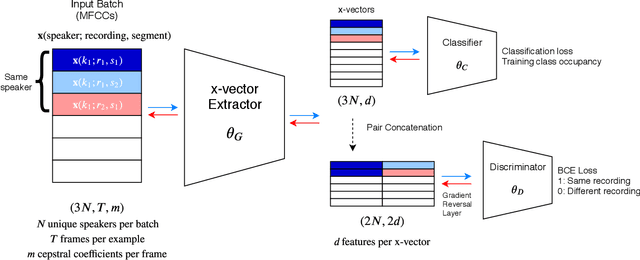
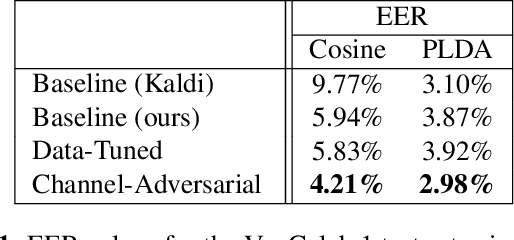
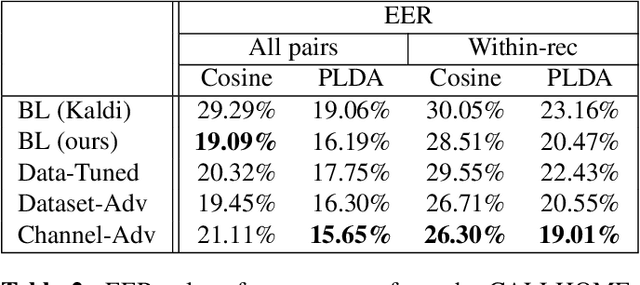
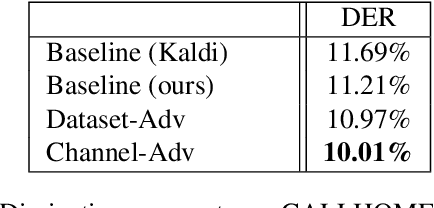
Previous work has encouraged domain-invariance in deep speaker embedding by adversarially classifying the dataset or labelled environment to which the generated features belong. We propose a training strategy which aims to produce features that are invariant at the granularity of the recording or channel, a finer grained objective than dataset- or environment-invariance. By training an adversary to predict whether pairs of same-speaker embeddings belong to the same recording in a Siamese fashion, learned features are discouraged from utilizing channel information that may be speaker discriminative during training. Experiments for verification on VoxCeleb and diarization and verification on CALLHOME show promising improvements over a strong baseline in addition to outperforming a dataset-adversarial model. The VoxCeleb model in particular performs well, achieving a $4\%$ relative improvement in EER over a Kaldi baseline, while using a similar architecture and less training data.