 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Attribute-Based Speaker Verification
May 30, 2024
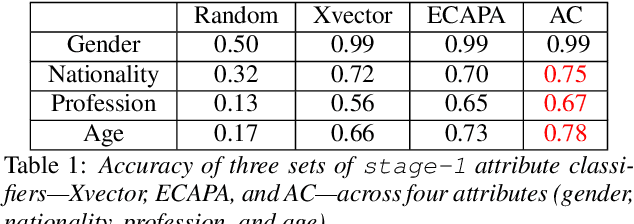
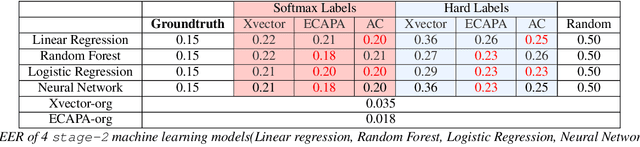

This paper proposes a fully explainable approach to speaker verification (SV), a task that fundamentally relies on individual speaker characteristics. The opaque use of speaker attributes in current SV systems raises concerns of trust. Addressing this, we propose an attribute-based explainable SV system that identifies speakers by comparing personal attributes such as gender, nationality, and age extracted automatically from voice recordings. We believe this approach better aligns with human reasoning, making it more understandable than traditional methods. Evaluated on the Voxceleb1 test set, the best performance of our system is comparable with the ground truth established when using all correct attributes, proving its efficacy. Whilst our approach sacrifices some performance compared to non-explainable methods, we believe that it moves us closer to the goal of transparent, interpretable AI and lays the groundwork for future enhancements through attribute expansion.
SSG2: A new modelling paradigm for semantic segmentation
Oct 12, 2023State-of-the-art models in semantic segmentation primarily operate on single, static images, generating corresponding segmentation masks. This one-shot approach leaves little room for error correction, as the models lack the capability to integrate multiple observations for enhanced accuracy. Inspired by work on semantic change detection, we address this limitation by introducing a methodology that leverages a sequence of observables generated for each static input image. By adding this "temporal" dimension, we exploit strong signal correlations between successive observations in the sequence to reduce error rates. Our framework, dubbed SSG2 (Semantic Segmentation Generation 2), employs a dual-encoder, single-decoder base network augmented with a sequence model. The base model learns to predict the set intersection, union, and difference of labels from dual-input images. Given a fixed target input image and a set of support images, the sequence model builds the predicted mask of the target by synthesizing the partial views from each sequence step and filtering out noise. We evaluate SSG2 across three diverse datasets: UrbanMonitor, featuring orthoimage tiles from Darwin, Australia with five spectral bands and 0.2m spatial resolution; ISPRS Potsdam, which includes true orthophoto images with multiple spectral bands and a 5cm ground sampling distance; and ISIC2018, a medical dataset focused on skin lesion segmentation, particularly melanoma. The SSG2 model demonstrates rapid convergence within the first few tens of epochs and significantly outperforms UNet-like baseline models with the same number of gradient updates. However, the addition of the temporal dimension results in an increased memory footprint. While this could be a limitation, it is offset by the advent of higher-memory GPUs and coding optimizations.
Can We Trust Explainable AI Methods on ASR? An Evaluation on Phoneme Recognition
May 29, 2023Explainable AI (XAI) techniques have been widely used to help explain and understand the output of deep learning models in fields such as image classification and Natural Language Processing. Interest in using XAI techniques to explain deep learning-based automatic speech recognition (ASR) is emerging. but there is not enough evidence on whether these explanations can be trusted. To address this, we adapt a state-of-the-art XAI technique from the image classification domain, Local Interpretable Model-Agnostic Explanations (LIME), to a model trained for a TIMIT-based phoneme recognition task. This simple task provides a controlled setting for evaluation while also providing expert annotated ground truth to assess the quality of explanations. We find a variant of LIME based on time partitioned audio segments, that we propose in this paper, produces the most reliable explanations, containing the ground truth 96% of the time in its top three audio segments.
Explanations for Automatic Speech Recognition
Feb 27, 2023We address quality assessment for neural network based ASR by providing explanations that help increase our understanding of the system and ultimately help build trust in the system. Compared to simple classification labels, explaining transcriptions is more challenging as judging their correctness is not straightforward and transcriptions as a variable-length sequence is not handled by existing interpretable machine learning models. We provide an explanation for an ASR transcription as a subset of audio frames that is both a minimal and sufficient cause of the transcription. To do this, we adapt existing explainable AI (XAI) techniques from image classification-Statistical Fault Localisation(SFL) and Causal. Additionally, we use an adapted version of Local Interpretable Model-Agnostic Explanations (LIME) for ASR as a baseline in our experiments. We evaluate the quality of the explanations generated by the proposed techniques over three different ASR ,Google API, the baseline model of Sphinx, Deepspeech and 100 audio samples from the Commonvoice dataset.
Blackbox Untargeted Adversarial Testing of Automatic Speech Recognition Systems
Dec 03, 2021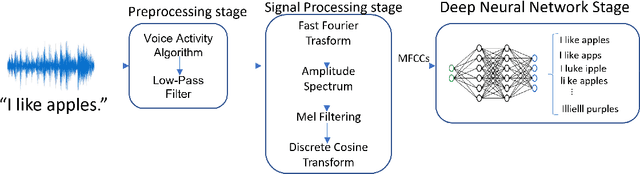
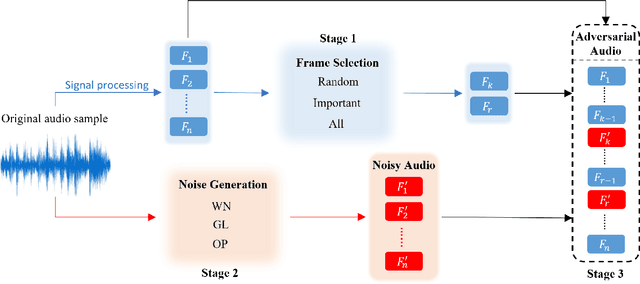
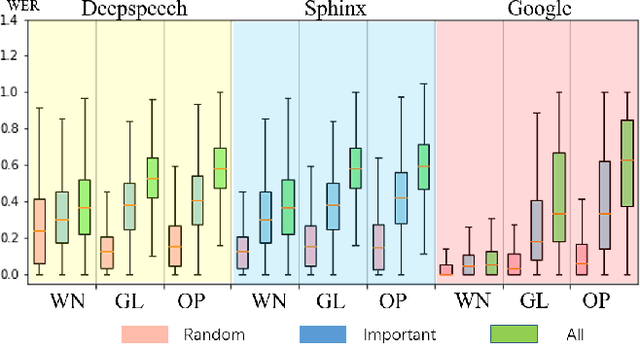
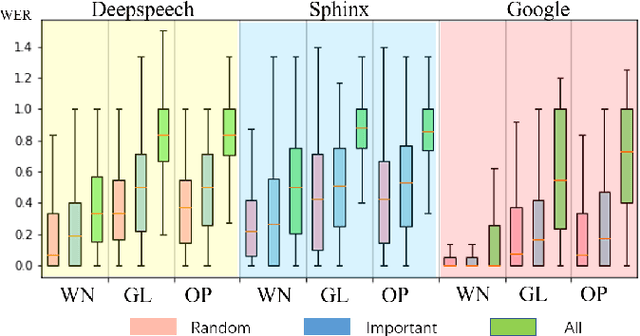
Automatic speech recognition (ASR) systems are prevalent, particularly in applications for voice navigation and voice control of domestic appliances. The computational core of ASRs are deep neural networks (DNNs) that have been shown to be susceptible to adversarial perturbations; easily misused by attackers to generate malicious outputs. To help test the correctness of ASRS, we propose techniques that automatically generate blackbox (agnostic to the DNN), untargeted adversarial attacks that are portable across ASRs. Much of the existing work on adversarial ASR testing focuses on targeted attacks, i.e generating audio samples given an output text. Targeted techniques are not portable, customised to the structure of DNNs (whitebox) within a specific ASR. In contrast, our method attacks the signal processing stage of the ASR pipeline that is shared across most ASRs. Additionally, we ensure the generated adversarial audio samples have no human audible difference by manipulating the acoustic signal using a psychoacoustic model that maintains the signal below the thresholds of human perception. We evaluate portability and effectiveness of our techniques using three popular ASRs and three input audio datasets using the metrics - WER of output text, Similarity to original audio and attack Success Rate on different ASRs. We found our testing techniques were portable across ASRs, with the adversarial audio samples producing high Success Rates, WERs and Similarities to the original audio.