 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSG2: A new modelling paradigm for semantic segmentation
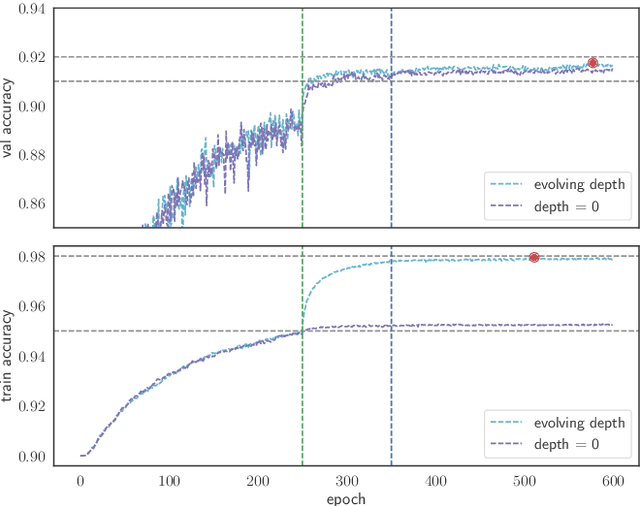
Oct 12, 2023State-of-the-art models in semantic segmentation primarily operate on single, static images, generating corresponding segmentation masks. This one-shot approach leaves little room for error correction, as the models lack the capability to integrate multiple observations for enhanced accuracy. Inspired by work on semantic change detection, we address this limitation by introducing a methodology that leverages a sequence of observables generated for each static input image. By adding this "temporal" dimension, we exploit strong signal correlations between successive observations in the sequence to reduce error rates. Our framework, dubbed SSG2 (Semantic Segmentation Generation 2), employs a dual-encoder, single-decoder base network augmented with a sequence model. The base model learns to predict the set intersection, union, and difference of labels from dual-input images. Given a fixed target input image and a set of support images, the sequence model builds the predicted mask of the target by synthesizing the partial views from each sequence step and filtering out noise. We evaluate SSG2 across three diverse datasets: UrbanMonitor, featuring orthoimage tiles from Darwin, Australia with five spectral bands and 0.2m spatial resolution; ISPRS Potsdam, which includes true orthophoto images with multiple spectral bands and a 5cm ground sampling distance; and ISIC2018, a medical dataset focused on skin lesion segmentation, particularly melanoma. The SSG2 model demonstrates rapid convergence within the first few tens of epochs and significantly outperforms UNet-like baseline models with the same number of gradient updates. However, the addition of the temporal dimension results in an increased memory footprint. While this could be a limitation, it is offset by the advent of higher-memory GPUs and coding optimizations.
Looking for change? Roll the Dice and demand Attention
Sep 04, 2020


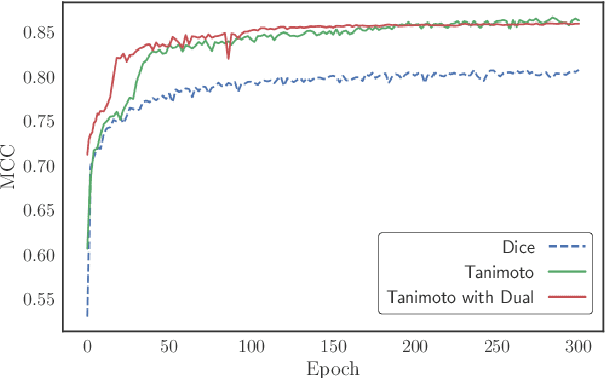
Change detection, i.e. identification per pixel of changes for some classes of interest from a set of bi-temporal co-registered images, is a fundamental task in the field of remote sensing. It remains challenging due to unrelated forms of change that appear at different times in input images. These are changes due to to different environmental conditions or simply changes of objects that are not of interest. Here, we propose a reliable deep learning framework for the task of semantic change detection in very high-resolution aerial images. Our framework consists of a new loss function, new attention modules, new feature extraction building blocks, and a new backbone architecture that is tailored for the task of semantic change detection. Specifically, we define a new form of set similarity, that is based on an iterative evaluation of a variant of the Dice coefficient. We use this similarity metric to define a new loss function as well as a new spatial and channel convolution Attention layer (the FracTAL). The new attention layer, designed specifically for vision tasks, is memory efficient, thus suitable for use in all levels of deep convolutional networks. Based on these, we introduce two new efficient self-contained feature extraction convolution units. We term these units CEECNet and FracTAL ResNet units. We validate the performance of these feature extraction building blocks on the CIFAR10 reference data and compare the results with standard ResNet modules. Further, we introduce a new encoder/decoder scheme, a network macro-topology, that is tailored for the task of change detection. We validate our approach by showing excellent performance and achieving state of the art score (F1 and Intersection over Union - hereafter IoU) on two building change detection datasets, namely, the LEVIRCD (F1: 0.918, IoU: 0.848) and the WHU (F1: 0.938, IoU: 0.882) datasets.
ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data
Apr 01, 2019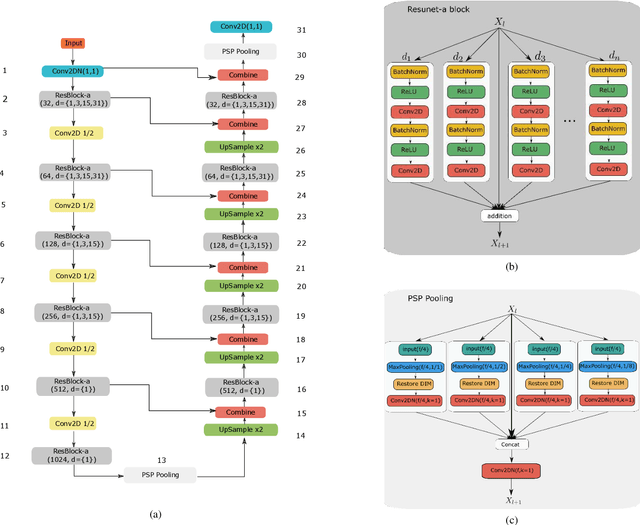
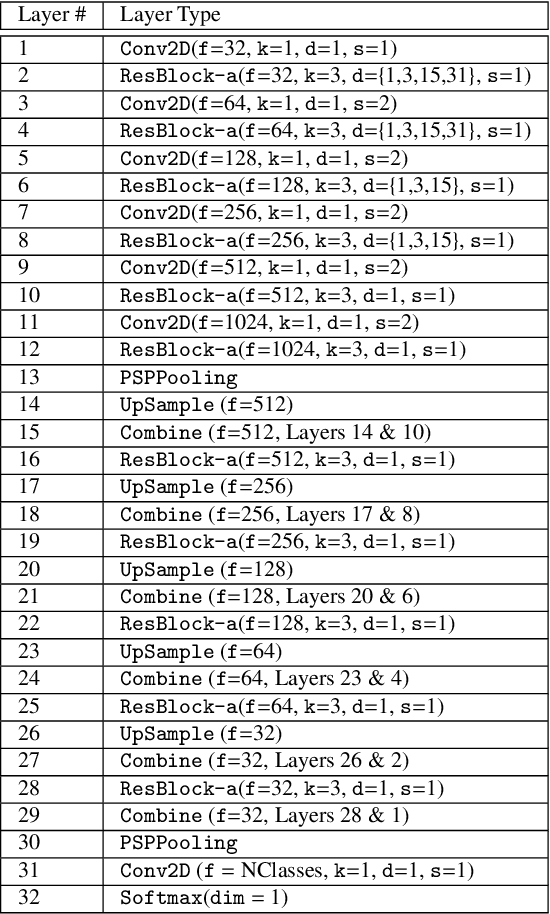

Scene understanding of high resolution aerial images is of great importance for the task of automated monitoring in various remote sensing applications. Due to the large within-class and small between-class variance in pixel values of objects of interest, this remains a challenging task. In recent years, deep convolutional neural networks have started being used in remote sensing applications and demonstrate state-of-the-art performance for pixel level classification of objects. Here we present a novel deep learning architecture, ResUNet-a, that combines ideas from various state-of-the-art modules used in computer vision for semantic segmentation tasks. We analyse the performance of several flavours of the Generalized Dice loss for semantic segmentation, and we introduce a novel variant loss function for semantic segmentation of objects that has better convergence properties and behaves well even under the presence of highly imbalanced classes. The performance of our modelling framework is evaluated on the ISPRS 2D Potsdam dataset. Results show state-of-the-art performance with an average F1 score of 92.1\% over all classes for our best model.