 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackbox Untargeted Adversarial Testing of Automatic Speech Recognition Systems
Paper and Code
Dec 03, 2021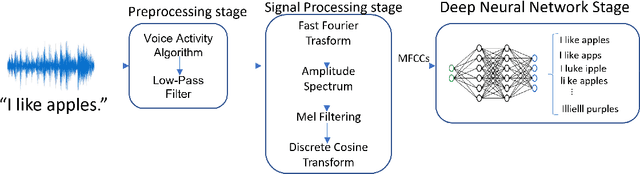
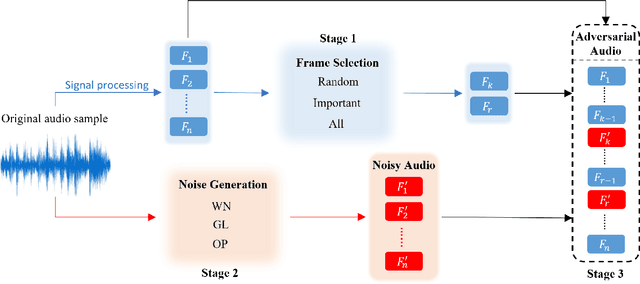
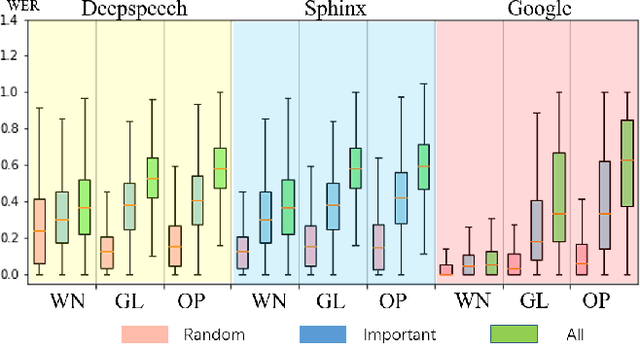
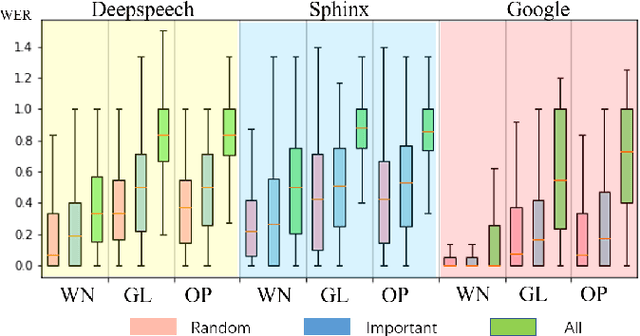
Automatic speech recognition (ASR) systems are prevalent, particularly in applications for voice navigation and voice control of domestic appliances. The computational core of ASRs are deep neural networks (DNNs) that have been shown to be susceptible to adversarial perturbations; easily misused by attackers to generate malicious outputs. To help test the correctness of ASRS, we propose techniques that automatically generate blackbox (agnostic to the DNN), untargeted adversarial attacks that are portable across ASRs. Much of the existing work on adversarial ASR testing focuses on targeted attacks, i.e generating audio samples given an output text. Targeted techniques are not portable, customised to the structure of DNNs (whitebox) within a specific ASR. In contrast, our method attacks the signal processing stage of the ASR pipeline that is shared across most ASRs. Additionally, we ensure the generated adversarial audio samples have no human audible difference by manipulating the acoustic signal using a psychoacoustic model that maintains the signal below the thresholds of human perception. We evaluate portability and effectiveness of our techniques using three popular ASRs and three input audio datasets using the metrics - WER of output text, Similarity to original audio and attack Success Rate on different ASRs. We found our testing techniques were portable across ASRs, with the adversarial audio samples producing high Success Rates, WERs and Similarities to the original audio.