 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
HealthBench: Evaluating Large Language Models Towards Improved Human Health
May 13, 2025



We present HealthBench, an open-source benchmark measuring the performance and safety of large language models in healthcare. HealthBench consists of 5,000 multi-turn conversations between a model and an individual user or healthcare professional. Responses are evaluated using conversation-specific rubrics created by 262 physicians. Unlike previous multiple-choice or short-answer benchmarks, HealthBench enables realistic, open-ended evaluation through 48,562 unique rubric criteria spanning several health contexts (e.g., emergencies, transforming clinical data, global health) and behavioral dimensions (e.g., accuracy, instruction following, communication). HealthBench performance over the last two years reflects steady initial progress (compare GPT-3.5 Turbo's 16% to GPT-4o's 32%) and more rapid recent improvements (o3 scores 60%). Smaller models have especially improved: GPT-4.1 nano outperforms GPT-4o and is 25 times cheaper. We additionally release two HealthBench variations: HealthBench Consensus, which includes 34 particularly important dimensions of model behavior validated via physician consensus, and HealthBench Hard, where the current top score is 32%. We hope that HealthBench grounds progress towards model development and applications that benefit human health.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Go-Oracle: Automated Test Oracle for Go Concurrency Bugs
Dec 11, 2024



The Go programming language has gained significant traction for developing software, especially in various infrastructure systems. Nonetheless, concurrency bugs have become a prevalent issue within Go, presenting a unique challenge due to the language's dual concurrency mechanisms-communicating sequential processes and shared memory. Detecting concurrency bugs and accurately classifying program executions as pass or fail presents an immense challenge, even for domain experts. We conducted a survey with expert developers at Bytedance that confirmed this challenge. Our work seeks to address the test oracle problem for Go programs, to automatically classify test executions as pass or fail. This problem has not been investigated in the literature for Go programs owing to its distinctive programming model. Our approach involves collecting both passing and failing execution traces from various subject Go programs. We capture a comprehensive array of execution events using the native Go execution tracer. Subsequently, we preprocess and encode these traces before training a transformer-based neural network to effectively classify the traces as either passing or failing. The evaluation of our approach encompasses 8 subject programs sourced from the GoBench repository. These subject programs are routinely used as benchmarks in an industry setting. Encouragingly, our test oracle, Go-Oracle, demonstrates high accuracies even when operating with a limited dataset, showcasing the efficacy and potential of our methodology. Developers at Bytedance strongly agreed that they would use the Go-Oracle tool over the current practice of manual inspections to classify tests for Go programs as pass or fail.
BenchDirect: A Directed Language Model for Compiler Benchmarks
Mar 02, 2023The exponential increase of hardware-software complexity has made it impossible for compiler engineers to find the right optimization heuristics manually. Predictive models have been shown to find near optimal heuristics with little human effort but they are limited by a severe lack of diverse benchmarks to train on. Generative AI has been used by researchers to synthesize benchmarks into existing datasets. However, the synthetic programs are short, exceedingly simple and lacking diversity in their features. We develop BenchPress, the first ML compiler benchmark generator that can be directed within source code feature representations. BenchPress synthesizes executable functions by infilling code that conditions on the program's left and right context. BenchPress uses active learning to introduce new benchmarks with unseen features into the dataset of Grewe's et al. CPU vs GPU heuristic, improving its acquired performance by 50%. BenchPress targets features that has been impossible for other synthesizers to reach. In 3 feature spaces, we outperform human-written code from GitHub, CLgen, CLSmith and the SRCIROR mutator in targeting the features of Rodinia benchmarks. BenchPress steers generation with beam search over a feature-agnostic language model. We improve this with BenchDirect which utilizes a directed LM that infills programs by jointly observing source code context and the compiler features that are targeted. BenchDirect achieves up to 36% better accuracy in targeting the features of Rodinia benchmarks, it is 1.8x more likely to give an exact match and it speeds up execution time by up to 72% compared to BenchPress. Both our models produce code that is difficult to distinguish from human-written code. We conduct a Turing test which shows our models' synthetic benchmarks are labelled as 'human-written' as often as human-written code from GitHub.
BenchPress: A Deep Active Benchmark Generator
Aug 16, 2022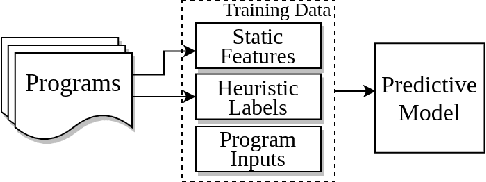

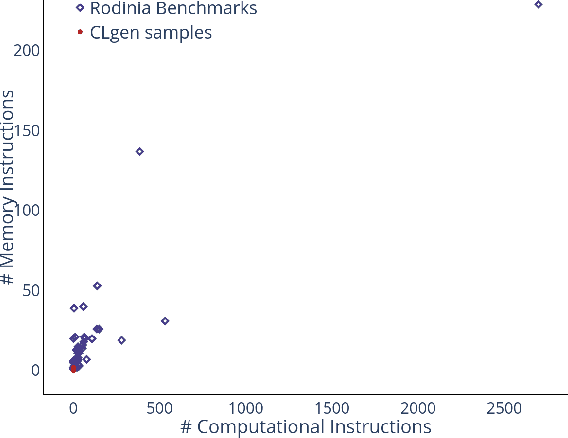
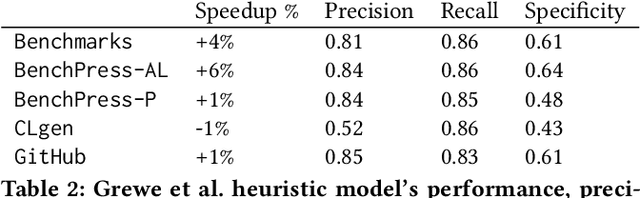
We develop BenchPress, the first ML benchmark generator for compilers that is steerable within feature space representations of source code. BenchPress synthesizes compiling functions by adding new code in any part of an empty or existing sequence by jointly observing its left and right context, achieving excellent compilation rate. BenchPress steers benchmark generation towards desired target features that has been impossible for state of the art synthesizers (or indeed humans) to reach. It performs better in targeting the features of Rodinia benchmarks in 3 different feature spaces compared with (a) CLgen - a state of the art ML synthesizer, (b) CLSmith fuzzer, (c) SRCIROR mutator or even (d) human-written code from GitHub. BenchPress is the first generator to search the feature space with active learning in order to generate benchmarks that will improve a downstream task. We show how using BenchPress, Grewe's et al. CPU vs GPU heuristic model can obtain a higher speedup when trained on BenchPress's benchmarks compared to other techniques. BenchPress is a powerful code generator: Its generated samples compile at a rate of 86%, compared to CLgen's 2.33%. Starting from an empty fixed input, BenchPress produces 10x more unique, compiling OpenCL benchmarks than CLgen, which are significantly larger and more feature diverse.
Learning to Encode and Classify Test Executions
Jan 08, 2020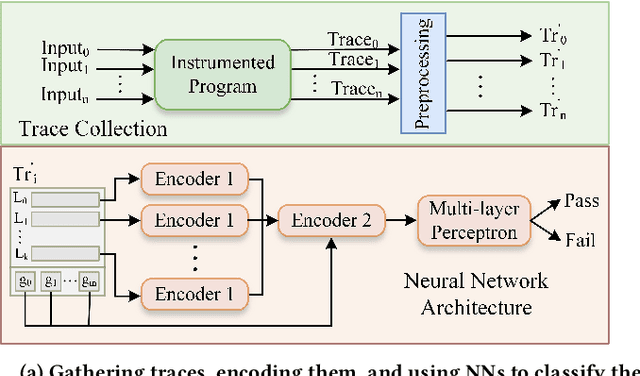
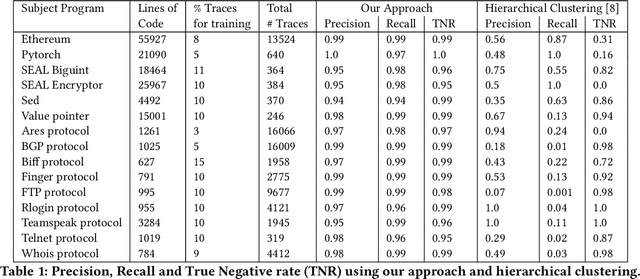
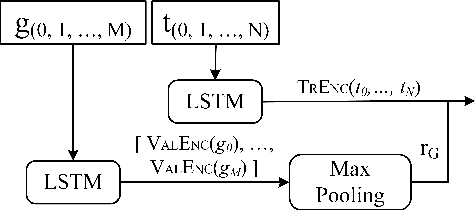
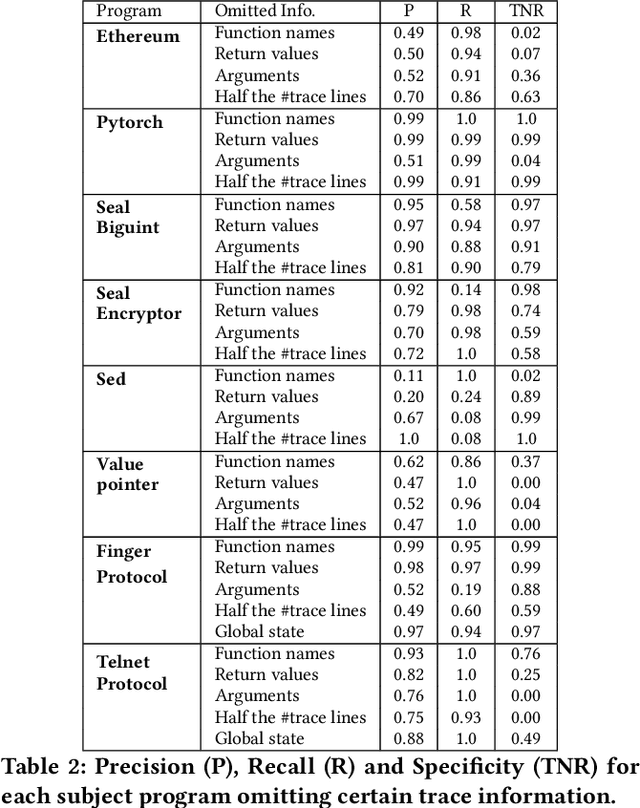
The challenge of automatically determining the correctness of test executions is referred to as the test oracle problem and is one of the key remaining issues for automated testing. The goal in this paper is to solve the test oracle problem in a way that is general, scalable and accurate. To achieve this, we use supervised learning over test execution traces. We label a small fraction of the execution traces with their verdict of pass or fail. We use the labelled traces to train a neural network (NN) model to learn to distinguish runtime patterns for passing versus failing executions for a given program. Our approach for building this NN model involves the following steps, 1. Instrument the program to record execution traces as sequences of method invocations and global state, 2. Label a small fraction of the execution traces with their verdicts, 3. Designing a NN component that embeds information in execution traces to fixed length vectors, 4. Design a NN model that uses the trace information for classification, 5. Evaluate the inferred classification model on unseen execution traces from the program. We evaluate our approach using case studies from different application domains: 1. Module from Ethereum Blockchain, 2. Module from PyTorch deep learning framework, 3. Microsoft SEAL encryption library components, 4. Sed stream editor, 5. Value pointer library and 6. Nine network protocols from Linux packet identifier, L7-Filter. We found the classification models for all subject programs resulted in high precision, recall and specificity, over 95%, while only training with an average 9% of the total traces. Our experiments show that the proposed neural network model is highly effective as a test oracle and is able to learn runtime patterns to distinguish passing and failing test executions for systems and tests from different application domains.