 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNExT: Teaching Large Language Models to Reason about Code Execution
Apr 23, 2024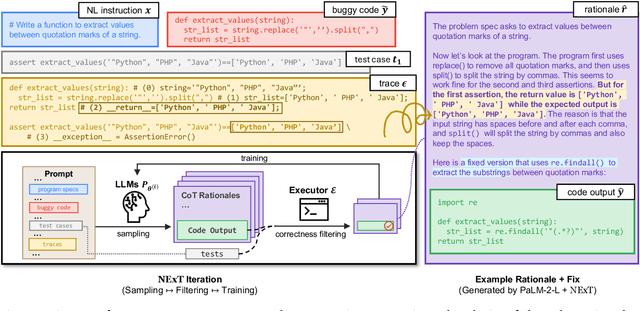



A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
Do Large Code Models Understand Programming Concepts? A Black-box Approach
Feb 23, 2024



Large Language Models' success on text generation has also made them better at code generation and coding tasks. While a lot of work has demonstrated their remarkable performance on tasks such as code completion and editing, it is still unclear as to why. We help bridge this gap by exploring to what degree auto-regressive models understand the logical constructs of the underlying programs. We propose Counterfactual Analysis for Programming Concept Predicates (CACP) as a counterfactual testing framework to evaluate whether Large Code Models understand programming concepts. With only black-box access to the model, we use CACP to evaluate ten popular Large Code Models for four different programming concepts. Our findings suggest that current models lack understanding of concepts such as data flow and control flow.
Unsupervised Evaluation of Code LLMs with Round-Trip Correctness
Feb 13, 2024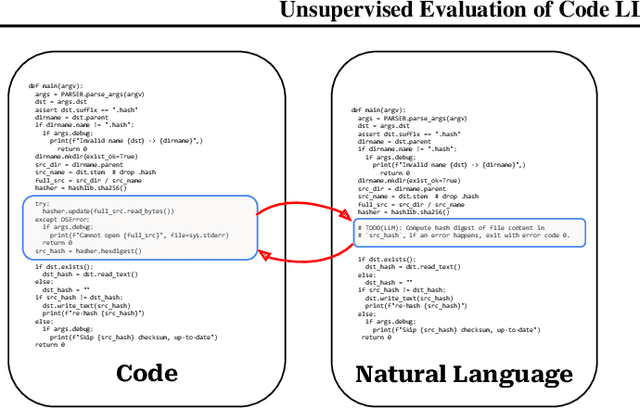

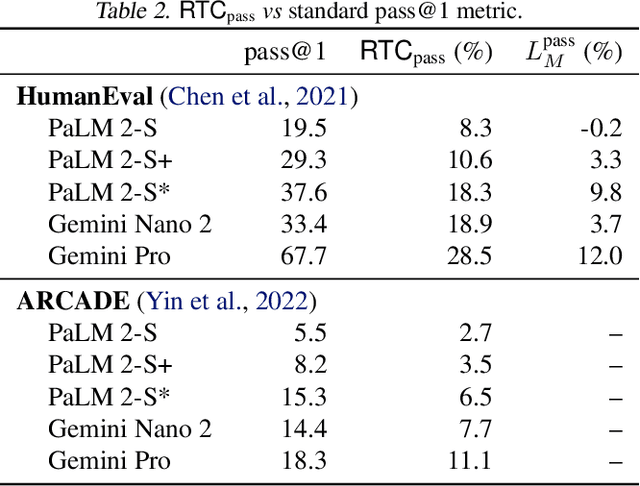
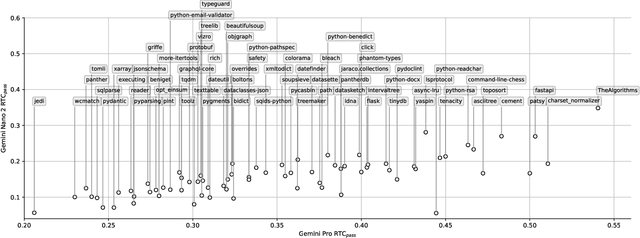
To evaluate code large language models (LLMs), research has relied on a few small manually curated benchmarks, such as HumanEval and MBPP, which represent a narrow part of the real-world software domains. In this work, we introduce round-trip correctness (RTC) as an alternative evaluation method. RTC allows Code LLM evaluation on a broader spectrum of real-world software domains without the need for costly human curation. RTC rests on the idea that we can ask a model to make a prediction (e.g., describe some code using natural language), feed that prediction back (e.g., synthesize code from the predicted description), and check if this round-trip leads to code that is semantically equivalent to the original input. We show how to employ RTC to evaluate code synthesis and editing. We find that RTC strongly correlates with model performance on existing narrow-domain code synthesis benchmarks while allowing us to expand to a much broader set of domains and tasks which was not previously possible without costly human annotations.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Epicure: Distilling Sequence Model Predictions into Patterns
Aug 16, 2023Most machine learning models predict a probability distribution over concrete outputs and struggle to accurately predict names over high entropy sequence distributions. Here, we explore finding abstract, high-precision patterns intrinsic to these predictions in order to make abstract predictions that usefully capture rare sequences. In this short paper, we present Epicure, a method that distils the predictions of a sequence model, such as the output of beam search, into simple patterns. Epicure maps a model's predictions into a lattice that represents increasingly more general patterns that subsume the concrete model predictions. On the tasks of predicting a descriptive name of a function given the source code of its body and detecting anomalous names given a function, we show that Epicure yields accurate naming patterns that match the ground truth more often compared to just the highest probability model prediction. For a false alarm rate of 10%, Epicure predicts patterns that match 61% more ground-truth names compared to the best model prediction, making Epicure well-suited for scenarios that require high precision.
JEMMA: An Extensible Java Dataset for ML4Code Applications
Dec 18, 2022Machine Learning for Source Code (ML4Code) is an active research field in which extensive experimentation is needed to discover how to best use source code's richly structured information. With this in mind, we introduce JEMMA, an Extensible Java Dataset for ML4Code Applications, which is a large-scale, diverse, and high-quality dataset targeted at ML4Code. Our goal with JEMMA is to lower the barrier to entry in ML4Code by providing the building blocks to experiment with source code models and tasks. JEMMA comes with a considerable amount of pre-processed information such as metadata, representations (e.g., code tokens, ASTs, graphs), and several properties (e.g., metrics, static analysis results) for 50,000 Java projects from the 50KC dataset, with over 1.2 million classes and over 8 million methods. JEMMA is also extensible allowing users to add new properties and representations to the dataset, and evaluate tasks on them. Thus, JEMMA becomes a workbench that researchers can use to experiment with novel representations and tasks operating on source code. To demonstrate the utility of the dataset, we also report results from two empirical studies on our data, ultimately showing that significant work lies ahead in the design of context-aware source code models that can reason over a broader network of source code entities in a software project, the very task that JEMMA is designed to help with.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022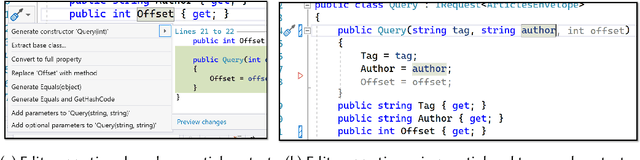


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
AdaptivePaste: Code Adaptation through Learning Semantics-aware Variable Usage Representations
May 23, 2022


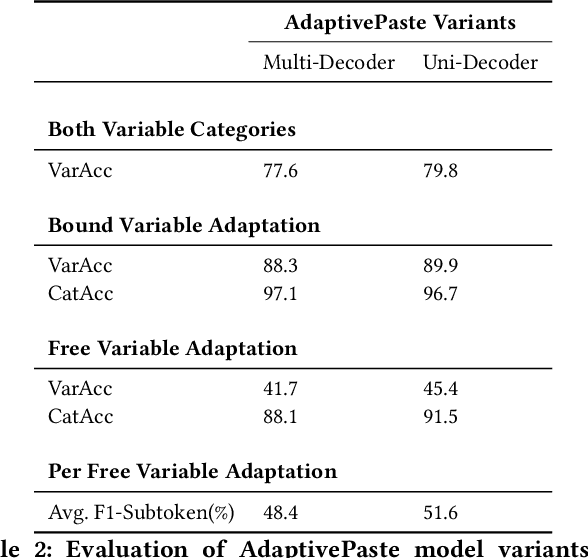
In software development, it is common for programmers to copy-paste code snippets and then adapt them to their use case. This scenario motivates \textit{code adaptation} task -- a variant of program repair which aims to adapt all variable identifiers in a pasted snippet of code to the surrounding, preexisting source code. Nevertheless, no existing approach have been shown to effectively address this task. In this paper, we introduce AdaptivePaste, a learning-based approach to source code adaptation, based on the transformer model and a dedicated dataflow-aware deobfuscation pre-training task to learn meaningful representations of variable usage patterns. We evaluate AdaptivePaste on a dataset of code snippets in Python. Evaluation results suggest that our model can learn to adapt copy-pasted code with 79.8\% accuracy.
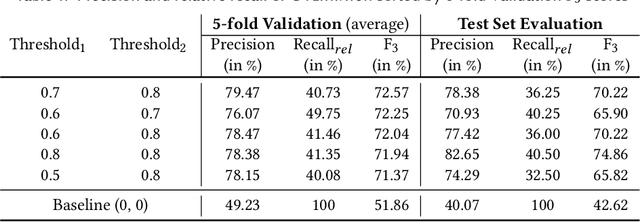
NS3: Neuro-Symbolic Semantic Code Search
May 21, 2022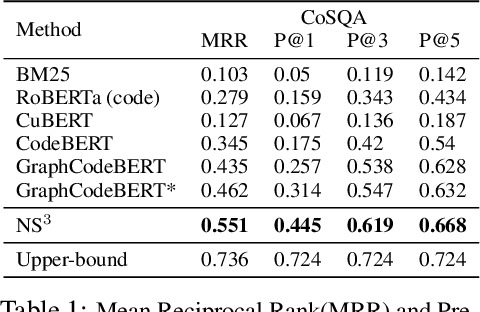
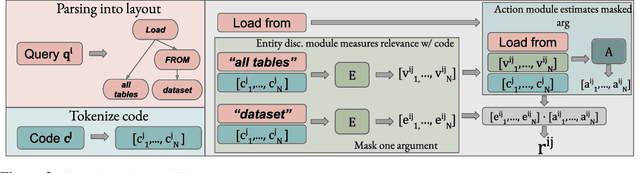
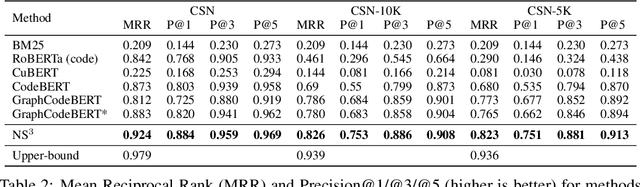
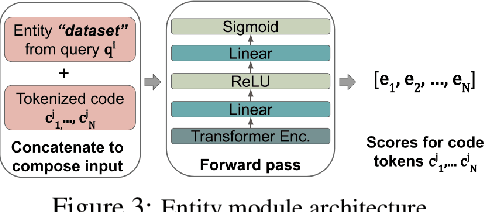
Semantic code search is the task of retrieving a code snippet given a textual description of its functionality. Recent work has been focused on using similarity metrics between neural embeddings of text and code. However, current language models are known to struggle with longer, compositional text, and multi-step reasoning. To overcome this limitation, we propose supplementing the query sentence with a layout of its semantic structure. The semantic layout is used to break down the final reasoning decision into a series of lower-level decisions. We use a Neural Module Network architecture to implement this idea. We compare our model - NS3 (Neuro-Symbolic Semantic Search) - to a number of baselines, including state-of-the-art semantic code retrieval methods, and evaluate on two datasets - CodeSearchNet and Code Search and Question Answering. We demonstrate that our approach results in more precise code retrieval, and we study the effectiveness of our modular design when handling compositional queries.
Is Surprisal in Issue Trackers Actionable?
Apr 15, 2022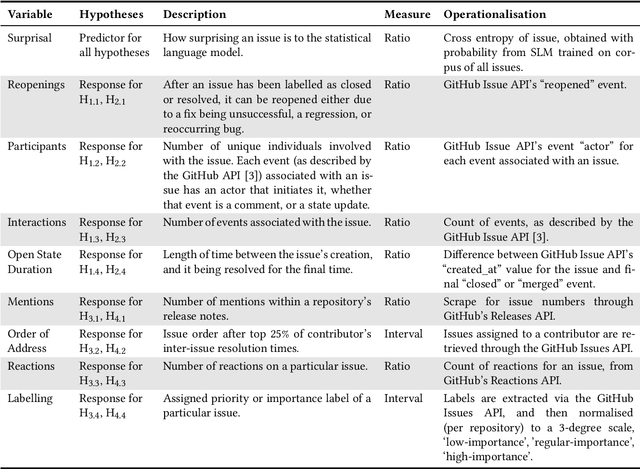
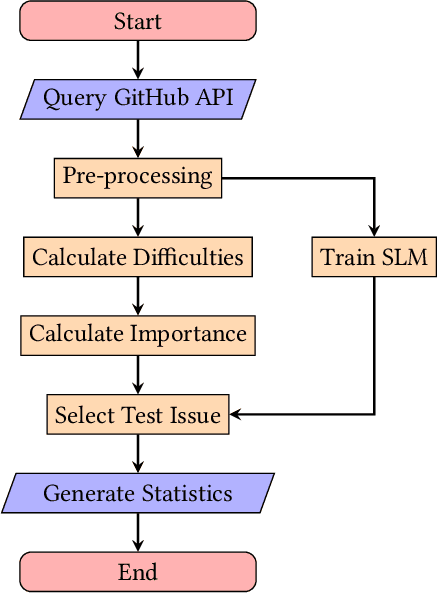
Background. From information theory, surprisal is a measurement of how unexpected an event is. Statistical language models provide a probabilistic approximation of natural languages, and because surprisal is constructed with the probability of an event occuring, it is therefore possible to determine the surprisal associated with English sentences. The issues and pull requests of software repository issue trackers give insight into the development process and likely contain the surprising events of this process. Objective. Prior works have identified that unusual events in software repositories are of interest to developers, and use simple code metrics-based methods for detecting them. In this study we will propose a new method for unusual event detection in software repositories using surprisal. With the ability to find surprising issues and pull requests, we intend to further analyse them to determine if they actually hold importance in a repository, or if they pose a significant challenge to address. If it is possible to find bad surprises early, or before they cause additional troubles, it is plausible that effort, cost and time will be saved as a result. Method. After extracting the issues and pull requests from 5000 of the most popular software repositories on GitHub, we will train a language model to represent these issues. We will measure their perceived importance in the repository, measure their resolution difficulty using several analogues, measure the surprisal of each, and finally generate inferential statistics to describe any correlations.