 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPECT: Intrinsic and Systematic Probing Evaluation for Code Transformers
Dec 08, 2023
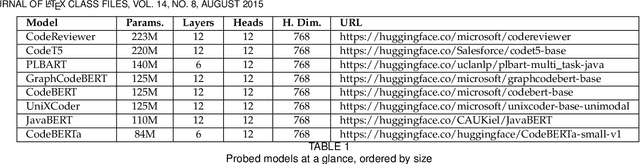
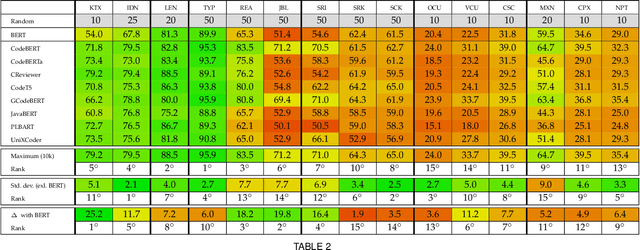
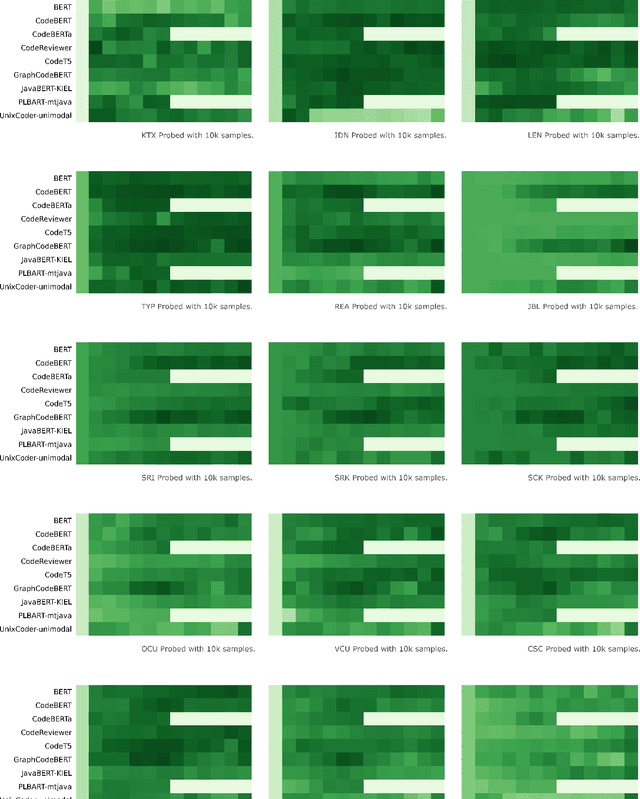
Pre-trained models of source code have recently been successfully applied to a wide variety of Software Engineering tasks; they have also seen some practical adoption in practice, e.g. for code completion. Yet, we still know very little about what these pre-trained models learn about source code. In this article, we use probing--simple diagnostic tasks that do not further train the models--to discover to what extent pre-trained models learn about specific aspects of source code. We use an extensible framework to define 15 probing tasks that exercise surface, syntactic, structural and semantic characteristics of source code. We probe 8 pre-trained source code models, as well as a natural language model (BERT) as our baseline. We find that models that incorporate some structural information (such as GraphCodeBERT) have a better representation of source code characteristics. Surprisingly, we find that for some probing tasks, BERT is competitive with the source code models, indicating that there are ample opportunities to improve source-code specific pre-training on the respective code characteristics. We encourage other researchers to evaluate their models with our probing task suite, so that they may peer into the hidden layers of the models and identify what intrinsic code characteristics are encoded.
JEMMA: An Extensible Java Dataset for ML4Code Applications
Dec 18, 2022Machine Learning for Source Code (ML4Code) is an active research field in which extensive experimentation is needed to discover how to best use source code's richly structured information. With this in mind, we introduce JEMMA, an Extensible Java Dataset for ML4Code Applications, which is a large-scale, diverse, and high-quality dataset targeted at ML4Code. Our goal with JEMMA is to lower the barrier to entry in ML4Code by providing the building blocks to experiment with source code models and tasks. JEMMA comes with a considerable amount of pre-processed information such as metadata, representations (e.g., code tokens, ASTs, graphs), and several properties (e.g., metrics, static analysis results) for 50,000 Java projects from the 50KC dataset, with over 1.2 million classes and over 8 million methods. JEMMA is also extensible allowing users to add new properties and representations to the dataset, and evaluate tasks on them. Thus, JEMMA becomes a workbench that researchers can use to experiment with novel representations and tasks operating on source code. To demonstrate the utility of the dataset, we also report results from two empirical studies on our data, ultimately showing that significant work lies ahead in the design of context-aware source code models that can reason over a broader network of source code entities in a software project, the very task that JEMMA is designed to help with.
Codex Hacks HackerRank: Memorization Issues and a Framework for Code Synthesis Evaluation
Dec 06, 2022


The Codex model has demonstrated extraordinary competence in synthesizing code from natural language problem descriptions. However, in order to reveal unknown failure modes and hidden biases, such large-scale models must be systematically subjected to multiple and diverse evaluation studies. In this work, we evaluate the code synthesis capabilities of the Codex model based on a set of 115 Python problem statements from a popular competitive programming portal: HackerRank. Our evaluation shows that Codex is indeed proficient in Python, solving 96% of the problems in a zero-shot setting, and 100% of the problems in a few-shot setting. However, Codex exhibits clear signs of generating memorized code based on our evaluation. This is alarming, especially since the adoption and use of such models could directly impact how code is written and produced in the foreseeable future. With this in mind, we further discuss and highlight some of the prominent risks associated with large-scale models of source code. Finally, we propose a framework for code-synthesis evaluation using variations of problem statements based on mutations.
What do pre-trained code models know about code?
Aug 25, 2021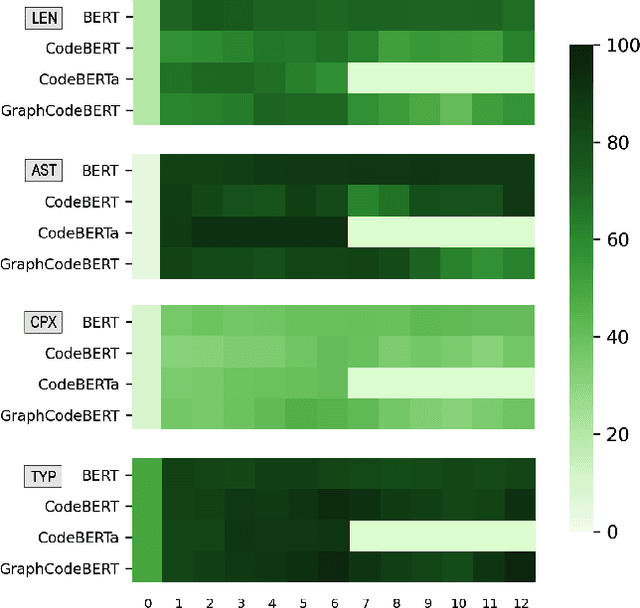
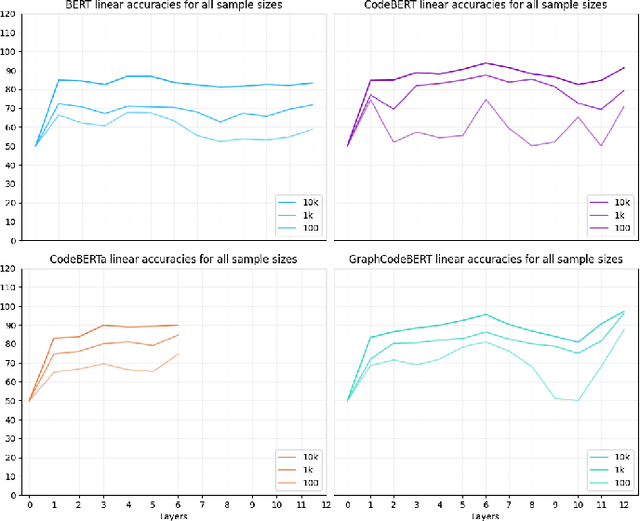
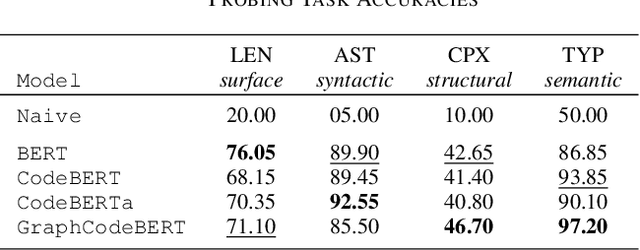
Pre-trained models of code built on the transformer architecture have performed well on software engineering (SE) tasks such as predictive code generation, code summarization, among others. However, whether the vector representations from these pre-trained models comprehensively encode characteristics of source code well enough to be applicable to a broad spectrum of downstream tasks remains an open question. One way to investigate this is with diagnostic tasks called probes. In this paper, we construct four probing tasks (probing for surface-level, syntactic, structural, and semantic information) for pre-trained code models. We show how probes can be used to identify whether models are deficient in (understanding) certain code properties, characterize different model layers, and get insight into the model sample-efficiency. We probe four models that vary in their expected knowledge of code properties: BERT (pre-trained on English), CodeBERT and CodeBERTa (pre-trained on source code, and natural language documentation), and GraphCodeBERT (pre-trained on source code with dataflow). While GraphCodeBERT performs more consistently overall, we find that BERT performs surprisingly well on some code tasks, which calls for further investigation.