 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAGON: Robust Classification for Very Large Collections of Software Repositories
Feb 09, 2026The ability to automatically classify source code repositories with ''topics'' that reflect their content and purpose is very useful, especially when navigating or searching through large software collections. However, existing approaches often rely heavily on README files and other metadata, which are frequently missing, limiting their applicability in real-world large-scale settings. We present DRAGON, a repository classifier designed for very large and diverse software collections. It operates entirely on lightweight signals commonly stored in version control systems: file and directory names, and optionally the README when available. In repository classification at scale, DRAGON improves F1@5 from 54.8% to 60.8%, surpassing the state of the art. DRAGON remains effective even when README files are absent, with performance degrading by only 6% w.r.t. when they are present. This robustness makes it practical for real-world settings where documentation is sparse or inconsistent. Furthermore, many of the remaining classification errors are near misses, where predicted labels are semantically close to the correct topics. This property increases the practical value of the predictions in real-world software collections, where suggesting a few related topics can still guide search and discovery. As a byproduct of developing DRAGON, we also release the largest open dataset to date for repository classification, consisting of 825 thousand repositories with associated ground-truth topics, sourced from the Software Heritage archive, providing a foundation for future large-scale and language-agnostic research on software repository understanding.
ThrowBench: Benchmarking LLMs by Predicting Runtime Exceptions
Mar 06, 2025Modern Large Language Models (LLMs) have shown astounding capabilities of code understanding and synthesis. In order to assess such capabilities, several benchmarks have been devised (e.g., HumanEval). However, most benchmarks focus on code synthesis from natural language instructions. Hence, such benchmarks do not test for other forms of code understanding. Moreover, there have been concerns about contamination and leakage. That is, benchmark problems (or closely related problems) may appear in training set, strongly biasing benchmark results. In this work we investigate whether large language models can correctly predict runtime program behavior. To this end, we introduce ThrowBench, a benchmark consisting of over 2,400 short user-written programs written in four different programming languages. The majority of these programs throw an exception during runtime (due to a bug). LLMs are asked to predict whether a presented program throws an exception and, if so, which one. Evaluating our benchmark on six state-of-the-art code LLMs we see modest performance ranging from 19 to 38% (F1 score). Benchmarking a wider set of code capabilities could improve the assessment of code LLMs and help identify weak points in current models. Moreover, as ground-truth answers have been determined through program execution, leakage is not a concern. We release ThrowBench as well as all of our results together with this work.
Out of Context: How important is Local Context in Neural Program Repair?
Dec 08, 2023Deep learning source code models have been applied very successfully to the problem of automated program repair. One of the standing issues is the small input window of current models which often cannot fully fit the context code required for a bug fix (e.g., method or class declarations of a project). Instead, input is often restricted to the local context, that is, the lines below and above the bug location. In this work we study the importance of this local context on repair success: how much local context is needed?; is context before or after the bug location more important? how is local context tied to the bug type? To answer these questions we train and evaluate Transformer models in many different local context configurations on three datasets and two programming languages. Our results indicate that overall repair success increases with the size of the local context (albeit not for all bug types) and confirm the common practice that roughly 50-60% of the input window should be used for context leading the bug. Our results are not only relevant for researchers working on Transformer-based APR tools but also for benchmark and dataset creators who must decide what and how much context to include in their datasets.
INSPECT: Intrinsic and Systematic Probing Evaluation for Code Transformers
Dec 08, 2023
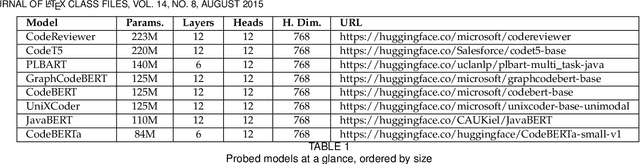
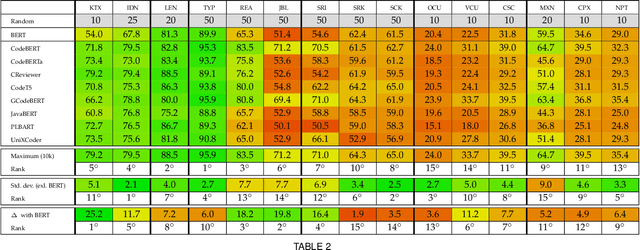
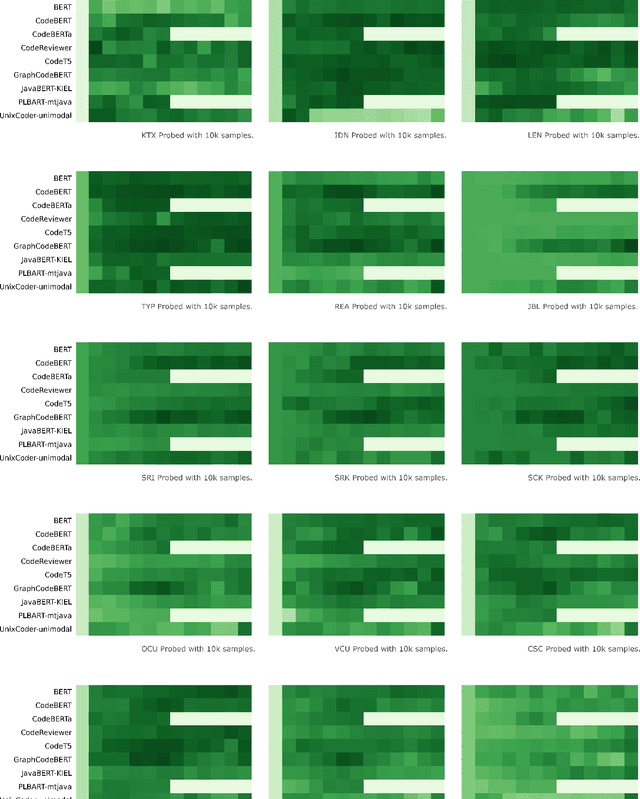
Pre-trained models of source code have recently been successfully applied to a wide variety of Software Engineering tasks; they have also seen some practical adoption in practice, e.g. for code completion. Yet, we still know very little about what these pre-trained models learn about source code. In this article, we use probing--simple diagnostic tasks that do not further train the models--to discover to what extent pre-trained models learn about specific aspects of source code. We use an extensible framework to define 15 probing tasks that exercise surface, syntactic, structural and semantic characteristics of source code. We probe 8 pre-trained source code models, as well as a natural language model (BERT) as our baseline. We find that models that incorporate some structural information (such as GraphCodeBERT) have a better representation of source code characteristics. Surprisingly, we find that for some probing tasks, BERT is competitive with the source code models, indicating that there are ample opportunities to improve source-code specific pre-training on the respective code characteristics. We encourage other researchers to evaluate their models with our probing task suite, so that they may peer into the hidden layers of the models and identify what intrinsic code characteristics are encoded.
RunBugRun -- An Executable Dataset for Automated Program Repair
Apr 03, 2023Recently, we can notice a transition to data-driven techniques in Automated Program Repair (APR), in particular towards deep neural networks. This entails training on hundreds of thousands or even millions of non-executable code fragments. We would like to bring more attention to an aspect of code often neglected in Neural Program Repair (NPR), namely its execution. Code execution has several significant advantages. It allows for test-based evaluation of candidate fixes and can provide valuable information to aid repair. In this work we present a fully executable dataset of 450,000 small buggy/fixed program pairs originally submitted to programming competition websites written in eight different programming languages. Along with the dataset we provide infrastructure to compile, safely execute and test programs as well as fine-grained bug-type labels. To give a point of reference, we provide basic evaluation results for two baselines, one based on a generate-and-validate approach and one on deep learning. With this dataset we follow several goals: we want to lift Neural Program Repair beyond fully static code representations, foster the use of execution-based features and, by including several different languages, counterbalance the predominance of Java in the current landscape of APR datasets and benchmarks.
JEMMA: An Extensible Java Dataset for ML4Code Applications
Dec 18, 2022Machine Learning for Source Code (ML4Code) is an active research field in which extensive experimentation is needed to discover how to best use source code's richly structured information. With this in mind, we introduce JEMMA, an Extensible Java Dataset for ML4Code Applications, which is a large-scale, diverse, and high-quality dataset targeted at ML4Code. Our goal with JEMMA is to lower the barrier to entry in ML4Code by providing the building blocks to experiment with source code models and tasks. JEMMA comes with a considerable amount of pre-processed information such as metadata, representations (e.g., code tokens, ASTs, graphs), and several properties (e.g., metrics, static analysis results) for 50,000 Java projects from the 50KC dataset, with over 1.2 million classes and over 8 million methods. JEMMA is also extensible allowing users to add new properties and representations to the dataset, and evaluate tasks on them. Thus, JEMMA becomes a workbench that researchers can use to experiment with novel representations and tasks operating on source code. To demonstrate the utility of the dataset, we also report results from two empirical studies on our data, ultimately showing that significant work lies ahead in the design of context-aware source code models that can reason over a broader network of source code entities in a software project, the very task that JEMMA is designed to help with.
Codex Hacks HackerRank: Memorization Issues and a Framework for Code Synthesis Evaluation
Dec 06, 2022


The Codex model has demonstrated extraordinary competence in synthesizing code from natural language problem descriptions. However, in order to reveal unknown failure modes and hidden biases, such large-scale models must be systematically subjected to multiple and diverse evaluation studies. In this work, we evaluate the code synthesis capabilities of the Codex model based on a set of 115 Python problem statements from a popular competitive programming portal: HackerRank. Our evaluation shows that Codex is indeed proficient in Python, solving 96% of the problems in a zero-shot setting, and 100% of the problems in a few-shot setting. However, Codex exhibits clear signs of generating memorized code based on our evaluation. This is alarming, especially since the adoption and use of such models could directly impact how code is written and produced in the foreseeable future. With this in mind, we further discuss and highlight some of the prominent risks associated with large-scale models of source code. Finally, we propose a framework for code-synthesis evaluation using variations of problem statements based on mutations.
What do pre-trained code models know about code?
Aug 25, 2021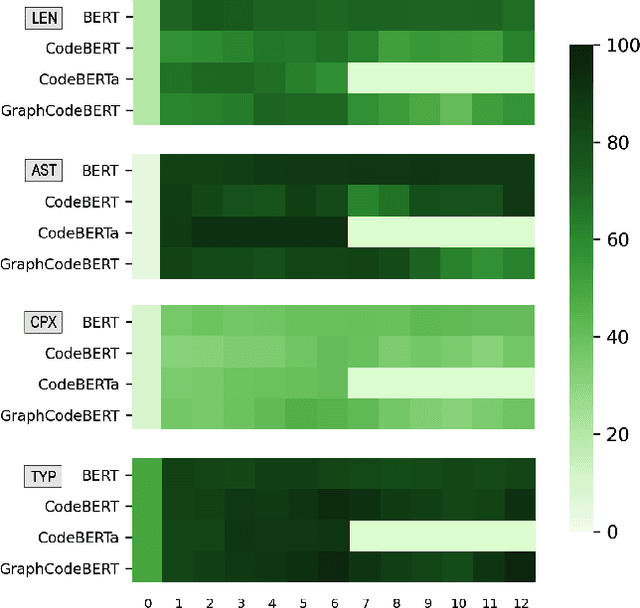
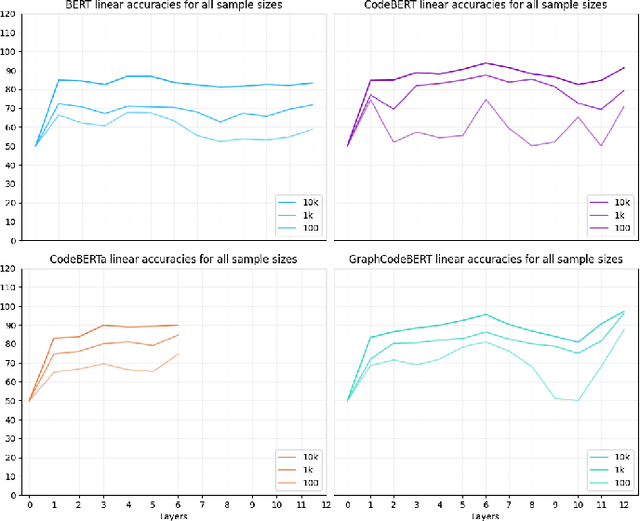
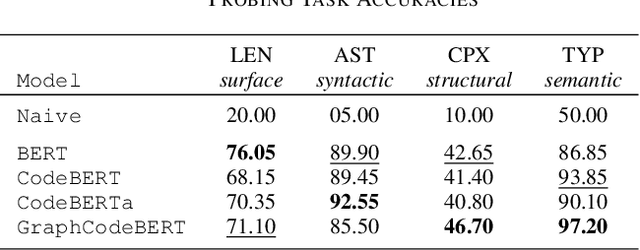
Pre-trained models of code built on the transformer architecture have performed well on software engineering (SE) tasks such as predictive code generation, code summarization, among others. However, whether the vector representations from these pre-trained models comprehensively encode characteristics of source code well enough to be applicable to a broad spectrum of downstream tasks remains an open question. One way to investigate this is with diagnostic tasks called probes. In this paper, we construct four probing tasks (probing for surface-level, syntactic, structural, and semantic information) for pre-trained code models. We show how probes can be used to identify whether models are deficient in (understanding) certain code properties, characterize different model layers, and get insight into the model sample-efficiency. We probe four models that vary in their expected knowledge of code properties: BERT (pre-trained on English), CodeBERT and CodeBERTa (pre-trained on source code, and natural language documentation), and GraphCodeBERT (pre-trained on source code with dataflow). While GraphCodeBERT performs more consistently overall, we find that BERT performs surprisingly well on some code tasks, which calls for further investigation.
Modeling Vocabulary for Big Code Machine Learning
Apr 03, 2019
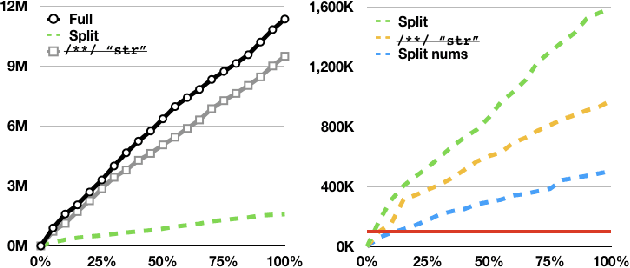
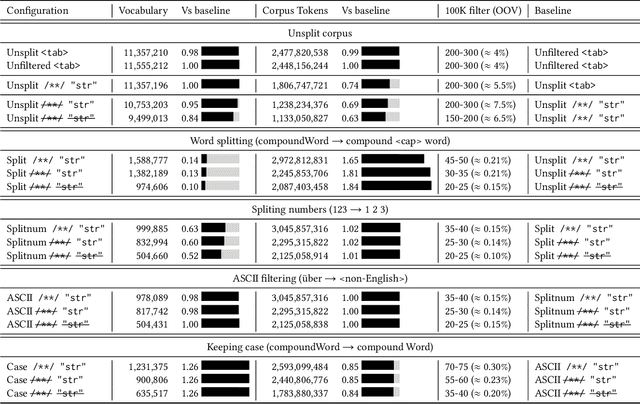
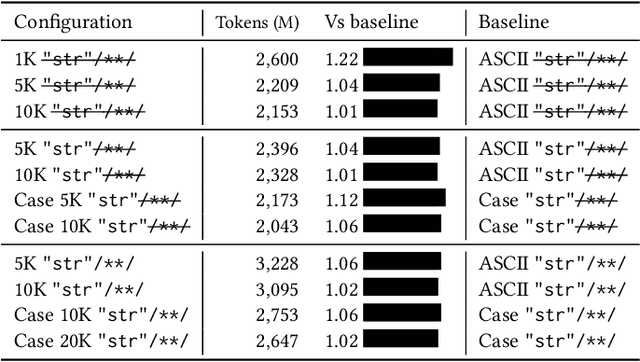
When building machine learning models that operate on source code, several decisions have to be made to model source-code vocabulary. These decisions can have a large impact: some can lead to not being able to train models at all, others significantly affect performance, particularly for Neural Language Models. Yet, these decisions are not often fully described. This paper lists important modeling choices for source code vocabulary, and explores their impact on the resulting vocabulary on a large-scale corpus of 14,436 projects. We show that a subset of decisions have decisive characteristics, allowing to train accurate Neural Language Models quickly on a large corpus of 10,106 projects.