Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Vocabulary for Big Code Machine Learning
Paper and Code
Apr 03, 2019
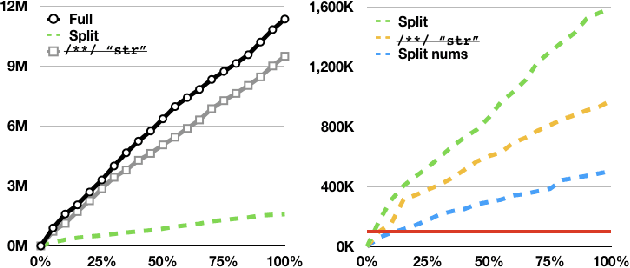
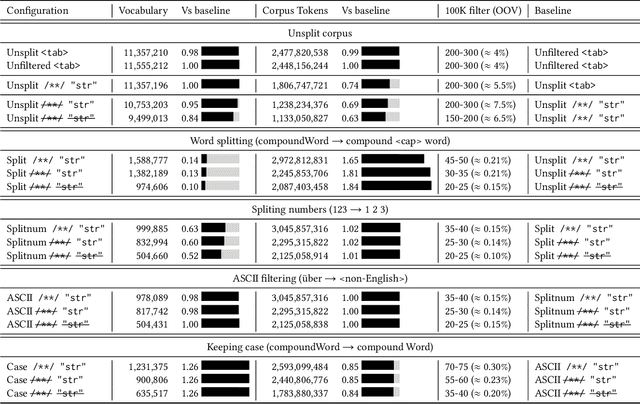
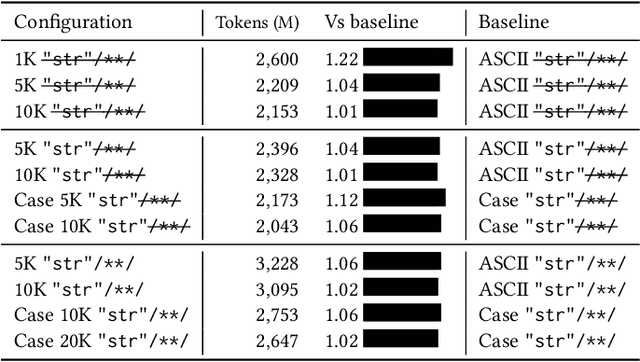
When building machine learning models that operate on source code, several decisions have to be made to model source-code vocabulary. These decisions can have a large impact: some can lead to not being able to train models at all, others significantly affect performance, particularly for Neural Language Models. Yet, these decisions are not often fully described. This paper lists important modeling choices for source code vocabulary, and explores their impact on the resulting vocabulary on a large-scale corpus of 14,436 projects. We show that a subset of decisions have decisive characteristics, allowing to train accurate Neural Language Models quickly on a large corpus of 10,106 projects.
* 12 pages, 1 figure
View paper on