 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Invisible Hand of AI Libraries Shaping Open Source Projects and Communities
Jan 05, 2026In the early 1980s, Open Source Software emerged as a revolutionary concept amidst the dominance of proprietary software. What began as a revolutionary idea has now become the cornerstone of computer science. Amidst OSS projects, AI is increasing its presence and relevance. However, despite the growing popularity of AI, its adoption and impacts on OSS projects remain underexplored. We aim to assess the adoption of AI libraries in Python and Java OSS projects and examine how they shape development, including the technical ecosystem and community engagement. To this end, we will perform a large-scale analysis on 157.7k potential OSS repositories, employing repository metrics and software metrics to compare projects adopting AI libraries against those that do not. We expect to identify measurable differences in development activity, community engagement, and code complexity between OSS projects that adopt AI libraries and those that do not, offering evidence-based insights into how AI integration reshapes software development practices.
Lowering Detection in Sport Climbing Based on Orientation of the Sensor Enhanced Quickdraw
Jan 17, 2023Tracking climbers' activity to improve services and make the best use of their infrastructure is a concern for climbing gyms. Each climbing session must be analyzed from beginning till lowering of the climber. Therefore, spotting the climbers descending is crucial since it indicates when the ascent has come to an end. This problem must be addressed while preserving privacy and convenience of the climbers and the costs of the gyms. To this aim, a hardware prototype is developed to collect data using accelerometer sensors attached to a piece of climbing equipment mounted on the wall, called quickdraw, that connects the climbing rope to the bolt anchors. The corresponding sensors are configured to be energy-efficient, hence become practical in terms of expenses and time consumption for replacement when using in large quantity in a climbing gym. This paper describes hardware specifications, studies data measured by the sensors in ultra-low power mode, detect sensors' orientation patterns during lowering different routes, and develop an supervised approach to identify lowering.
Climbing Routes Clustering Using Energy-Efficient Accelerometers Attached to the Quickdraws
Nov 04, 2022One of the challenges for climbing gyms is to find out popular routes for the climbers to improve their services and optimally use their infrastructure. This problem must be addressed preserving both the privacy and convenience of the climbers and the costs of the gyms. To this aim, a hardware prototype is developed to collect data using accelerometer sensors attached to a piece of climbing equipment mounted on the wall, called quickdraw, that connects the climbing rope to the bolt anchors. The corresponding sensors are configured to be energy-efficient, hence becoming practical in terms of expenses and time consumption for replacement when used in large quantities in a climbing gym. This paper describes hardware specifications, studies data measured by the sensors in ultra-low power mode, detect patterns in data during climbing different routes, and develops an unsupervised approach for route clustering.
Modeling Vocabulary for Big Code Machine Learning
Apr 03, 2019
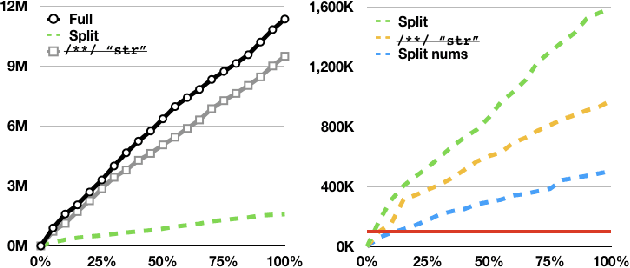
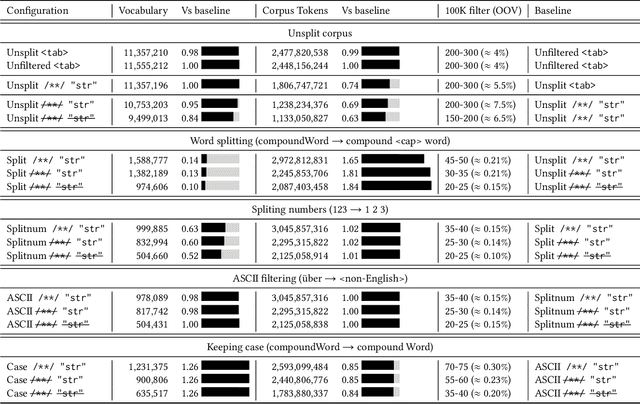
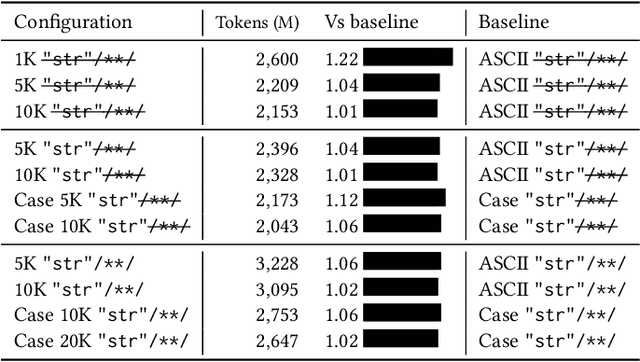
When building machine learning models that operate on source code, several decisions have to be made to model source-code vocabulary. These decisions can have a large impact: some can lead to not being able to train models at all, others significantly affect performance, particularly for Neural Language Models. Yet, these decisions are not often fully described. This paper lists important modeling choices for source code vocabulary, and explores their impact on the resulting vocabulary on a large-scale corpus of 14,436 projects. We show that a subset of decisions have decisive characteristics, allowing to train accurate Neural Language Models quickly on a large corpus of 10,106 projects.