 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Multivariate Time Series Pattern Exploration: Latent Space Visual Analytics with Temporal Fusion Transformer and Variational Autoencoders in Power Grid Event Diagnosis
Dec 24, 2024Detecting and analyzing complex patterns in multivariate time-series data is crucial for decision-making in urban and environmental system operations. However, challenges arise from the high dimensionality, intricate complexity, and interconnected nature of complex patterns, which hinder the understanding of their underlying physical processes. Existing AI methods often face limitations in interpretability, computational efficiency, and scalability, reducing their applicability in real-world scenarios. This paper proposes a novel visual analytics framework that integrates two generative AI models, Temporal Fusion Transformer (TFT) and Variational Autoencoders (VAEs), to reduce complex patterns into lower-dimensional latent spaces and visualize them in 2D using dimensionality reduction techniques such as PCA, t-SNE, and UMAP with DBSCAN. These visualizations, presented through coordinated and interactive views and tailored glyphs, enable intuitive exploration of complex multivariate temporal patterns, identifying patterns' similarities and uncover their potential correlations for a better interpretability of the AI outputs. The framework is demonstrated through a case study on power grid signal data, where it identifies multi-label grid event signatures, including faults and anomalies with diverse root causes. Additionally, novel metrics and visualizations are introduced to validate the models and evaluate the performance, efficiency, and consistency of latent maps generated by TFT and VAE under different configurations. These analyses provide actionable insights for model parameter tuning and reliability improvements. Comparative results highlight that TFT achieves shorter run times and superior scalability to diverse time-series data shapes compared to VAE. This work advances fault diagnosis in multivariate time series, fostering explainable AI to support critical system operations.
Do Large Code Models Understand Programming Concepts? A Black-box Approach
Feb 23, 2024



Large Language Models' success on text generation has also made them better at code generation and coding tasks. While a lot of work has demonstrated their remarkable performance on tasks such as code completion and editing, it is still unclear as to why. We help bridge this gap by exploring to what degree auto-regressive models understand the logical constructs of the underlying programs. We propose Counterfactual Analysis for Programming Concept Predicates (CACP) as a counterfactual testing framework to evaluate whether Large Code Models understand programming concepts. With only black-box access to the model, we use CACP to evaluate ten popular Large Code Models for four different programming concepts. Our findings suggest that current models lack understanding of concepts such as data flow and control flow.
Disentangling Space and Time in Video with Hierarchical Variational Auto-encoders
Dec 19, 2016
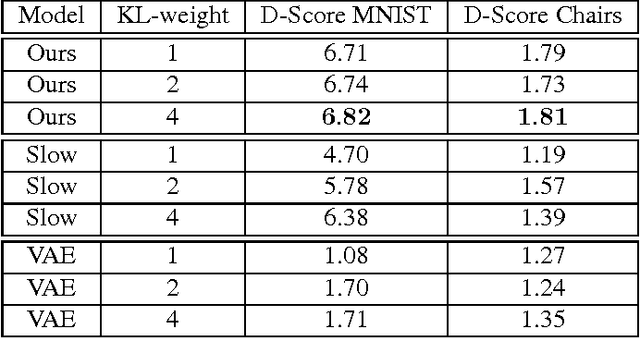

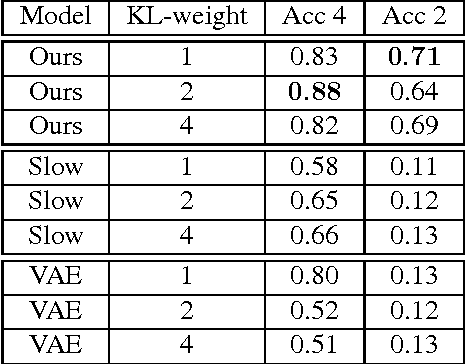
There are many forms of feature information present in video data. Principle among them are object identity information which is largely static across multiple video frames, and object pose and style information which continuously transforms from frame to frame. Most existing models confound these two types of representation by mapping them to a shared feature space. In this paper we propose a probabilistic approach for learning separable representations of object identity and pose information using unsupervised video data. Our approach leverages a deep generative model with a factored prior distribution that encodes properties of temporal invariances in the hidden feature set. Learning is achieved via variational inference. We present results of learning identity and pose information on a dataset of moving characters as well as a dataset of rotating 3D objects. Our experimental results demonstrate our model's success in factoring its representation, and demonstrate that the model achieves improved performance in transfer learning tasks.